leveldb 源码分析(三) – Write
leveldb 的写操作很简单,先写 WAL,然后写到 memtable:
- 每个写操作都有
sequence,会一同记录在key中,通过sequence实现MVCC。 - 删除
key时是插入一个tombstone。 - 所有的操作顺序追加到
log中。
写操作执行
leveldb 不支持多个写操作同时执行,写操作会保存在 deque 中,只有队首的才会执行:
Status DBImpl::Write(const WriteOptions& options, WriteBatch* my_batch) {
Writer w(&mutex_);
w.batch = my_batch;
w.sync = options.sync;
w.done = false;
MutexLock l(&mutex_);
writers_.push_back(&w);
while (!w.done && &w != writers_.front()) {
w.cv.Wait();
}
if (w.done) {
return w.status;
}
leveldb 会将写操作合并执行:队首的线程将 deque 中正在等待执行的写操作 batch 到当前线程中一起执行,执行后设置 done 通知其他线程完成。batch 能够提高写 WAL 的效率。
WAL
leveldb 不是直接将 kv 插入到 memtable 中,而是先生成 WAL,然后解析 WAL 插入,目的是为了减少重复代码,复用了重启时用 WAL 恢复 memtable 的代码。
WAL 的格式如下:
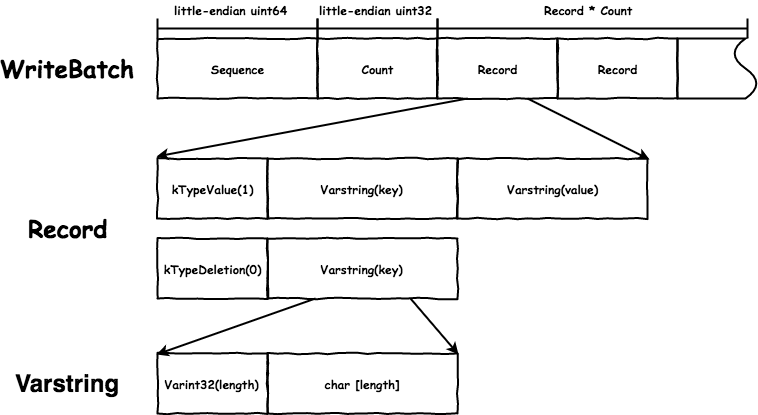
WriteBatch 记录了当前 batch 的起始 Sequence,会追加在 key 后用于实现 MVCC,写操作合并就是修改 WriteBatch 的 Count 并追加 Record。
varint
leveldb 中对 int 编码有2种格式:
fixedint: 固定字节数的little-endian编码。varint: 变长字节数的int编码,目的是为了节省空间,把每个字节的最高位作为进位标志。因为编码后的每个字节只用到了7位,所以在最坏的情况下会比定长编码用的空间多,int32最多用到5字节,int64最多用到10字节:char* EncodeVarint32(char* dst, uint32_t v) { // Operate on characters as unsigneds unsigned char* ptr = reinterpret_cast<unsigned char*>(dst); static const int B = 128; if (v < (1<<7)) { *(ptr++) = v; } else if (v < (1<<14)) { *(ptr++) = v | B; *(ptr++) = v>>7; } else if (v < (1<<21)) { *(ptr++) = v | B; *(ptr++) = (v>>7) | B; *(ptr++) = v>>14; } else if (v < (1<<28)) { *(ptr++) = v | B; *(ptr++) = (v>>7) | B; *(ptr++) = (v>>14) | B; *(ptr++) = v>>21; } else { *(ptr++) = v | B; *(ptr++) = (v>>7) | B; *(ptr++) = (v>>14) | B; *(ptr++) = (v>>21) | B; *(ptr++) = v>>28; } return reinterpret_cast<char*>(ptr); }
log
leveldb 使用 log::Writer 写 log,包括 WAL 和 MANIFEST。log::Writer 会在具体内容之外增加如 checksum 之类的保护,用于检测 corruption,它的格式如下:
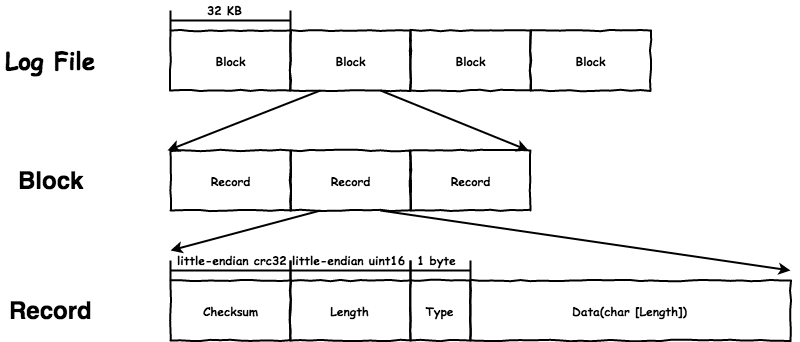
log::Writer 将文件划分为固定大小的 Block(32 KB),Record 不能跨越 Block,每个 Block 开始一定是一个新的 Record,这么做的目的是当一个 Block 的数据发生
corruption 时不会影响到其他的 Block。显然,单条 log 的大小可能会超过 Block size,通过 Record 中的 Type 区分:
kFullType:当前Block中是完整的一条log。kFirstType、kMiddleType、kLastType:组装成一条完整的log。
memtable
个人认为 memtable 是 leveldb 里实现最复杂的部分。任意有序的结构都可以实现 memtable,leveldb 使用 skiplist 实现,因为结构简单,
更容易实现 lock-free 的支持一写多读的。
InternalKey
为了实现并发控制,每个写入的 key 会携带着 sequence,并且不能够修改之前写入的数据,而是插入新的数据。InternalKey 的格式如下:
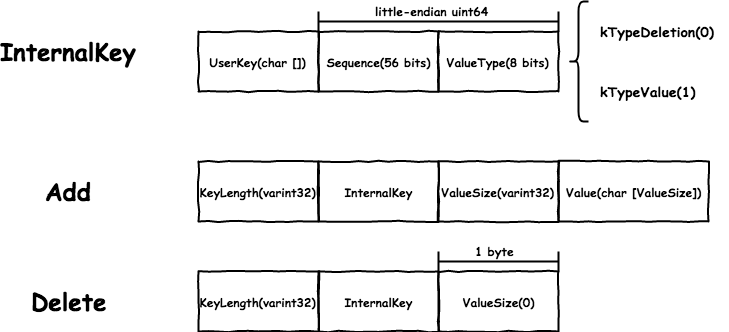
InternalKey 的比较按照:
UserKey升序:使用用户传入的comparator比较,默认是memcmp。Sequence降序。ValueType降序:每个写操作都有不同的sequence,所以ValueType用不到。
查找的时候会根据传入的 snapshot 或者最新的 sequence 构造出 InternalKey 查询,只要查找到第一个大于等于自己的即可。
leveldb 中 skiplist node 结构如下所示,只有 key 用于存储数据,所以 memtable 会构造如上所示的 Add/Delete 结构插入到 skiplist 中,通过 InternalKey 即可比较出大小,
后面追加的 value 不会影响先后顺序。
template<typename Key, class Comparator>
struct SkipList<Key,Comparator>::Node {
Key const key;
private:
port::AtomicPointer next_[1];
};
skiplist
leveldb 在插入和读取 memtable 的时候是不加锁的,全依赖 skiplist 实现并发控制。leveldb 实现的是支持一写多读的、lock-free 的 skiplist,skiplist 的原理不再赘述,主要看一下是如何实现并发控制的。
想要知道原理必须先理解 atomic pointer 的实现。
atomic pointer
leveldb 自己实现了 atomic pointer,具体原因可以查看 port/atomic_pointer.h 上面的注释,实现如下:
#if defined(ARCH_CPU_X86_FAMILY) && defined(__GNUC__)
inline void MemoryBarrier() {
__asm__ __volatile__("" : : : "memory");
}
class AtomicPointer {
private:
void* rep_;
public:
AtomicPointer() { }
explicit AtomicPointer(void* p) : rep_(p) {}
inline void* NoBarrier_Load() const { return rep_; }
inline void NoBarrier_Store(void* v) { rep_ = v; }
inline void* Acquire_Load() const {
void* result = rep_; // read-acquire
MemoryBarrier();
return result;
}
inline void Release_Store(void* v) {
MemoryBarrier();
rep_ = v; // write-release
}
};
AtomicPointer 提供了以下语义(我认为的,可能这里就已经出错了):
- 原子性:
store/load是原子的,不会被其他线程看到half-write,这里的原子性不包括原子变量的可见性。 - 可见性:
Release_Store/Acquire_Load提供了release/acquire语义。Release_Store立即对接下来的Acquire_Load可见(原子变量的可见性);Release_Store之前的写命令对Acquire_Load之后的读命令可见。
我主要关注 linux on x86/64 下的实现,为了搞懂有一些细节需要了解:
- 多核体系下,每个
CPU有独占的cache,使用MESI协议来保证cache coherence。为了降低同步对性能的影响,每个CPU有store buffer和invalidate queue来缓冲相应的同步消息,对同步消息处理 的时机和顺序是不确定的。 CPU在保证单线程程序的正确运行的前提下,为了提高性能会对命令做乱序处理。多线程情况下,因为store buffer和invalidate queue的存在,其他线程的修改不会立即对另外的线程可见;受到CPU乱序和 对同步消息处理的顺序影响,可见的顺序也不能保证。memory barrier用于保证多核之间操作的执行顺序,包含4类:LoadLoad-barrier:memory barrier前(后)的load不会乱序到memory barrier后(前)。LoadStore-barrier:memory barrier前的load(后的store)不会乱序到memory barrier后(前)。StoreStore-barrier:memory barrier前(后) 的store不会乱序到memory barrier后(前)。StoreLoad-barrier:memory barrier前的store(后的load)不会乱序到memory barrier后(前)。
memory barrier只能保证memory oder,也即可见性顺序,如x操作完成可见,则y操作也一定完成可见,但并不能保证可见性,CPU会尽最大努力保证可见性。memory barrier一般成对使用,否则一个线程有序另一个乱序,最终的结果还是乱序。- 比
memory barrier更高一层的语义是acquire/release,同样也要成对使用:acquire: 保证了在acquire之后的读写操作不会乱序到acquire前。release: 保证了在release之前的读写操作不会乱序到release后。
acquire/release同样只保证可见性顺序,对可见的时机不能保证,需要有方法判断acquire或者release完成。一般将load(RMW)/store(RMW)操作和memory barrier搭配使用构成acquire/release语义, 对load/store操作和memory barrier的顺序有要求:acquire:load/RMW在前,memory barrier在后,load/RMW操作构成read-acquire,防止了LoadLoad/LoadStore乱序。release:store/RMW在后,memory barrier在前,store/RMW操作构成write-release,防止了LoadStore/StoreStore乱序。- 这种顺序很符合逻辑,只有这样才能够确保
store操作完成,之前的release操作一定完成;load操作不会在memory barrier之后执行。
- 构成
acquire/release语义的读写操作要操作相同的变量,同时需要是原子操作。 - 除了
CPU乱序,编译器也会在保证单线程程序正确性的前提下,对命令乱序处理,同样有compiler barrier保证编译的命令顺序。
x86/64 是 strong memory model,load/store 自带 acquire/release 语义,只会出现操作不同地址的 StoreLoad 乱序。对于 naturally aligned native types 且大小不超过 memory bus 的变量读写操作是原子的
,所以只要防止编译器乱序即可。所以 leveldb 的 AtomicPointer 在 gcc on x86 的实现中只使用了 compiler barrier。
比较奇怪的是,按照我的理解 acquire/release 语义只能保证可见性顺序,所以不能保证对 AtomicPointer 的修改立即对其他线程可见,难道是可见的时间很短可以忽略不计,atomic variable 是如何保证可见性?
可能是我什么地方疏漏了或者理解有误,这方面比较薄弱,以后会进一步需学习。后面分析 lock-free 时默认对 AtomicPointer 的 Release_Store 立即对 Acquire_Load 可见。
参考资料:
- An Introduction to Lock-Free Programming
- Memory Ordering at Compile Time
- Memory Barriers Are Like Source Control Operations
- Acquire and Release Semantics
- The Synchronizes-With Relation
- Weak vs. Strong Memory Models
- Atomic vs. Non-Atomic Operations
- The JSR-133 Cookbook for Compiler Writers
- Lockless Programming Considerations for Xbox 360 and Microsoft Windows
- LINUX KERNEL MEMORY BARRIERS
lock-free
skiplist 只需要支持如下场景的线程安全即可:
- 一写多读:写操作不影响正在进行的读操作。
- 写之后读:写操作之后的读要立刻读到最新的写入。
- 写之后写:写操作之后继续写入要保证线程安全。
先来看一下 skiplist 的结构:
template<typename Key, class Comparator>
class SkipList {
private:
enum { kMaxHeight = 12 };
Comparator const compare_;
Arena* const arena_;
Node* const head_;
port::AtomicPointer max_height_;
Random rnd_;
};
template<typename Key, class Comparator>
struct SkipList<Key,Comparator>::Node {
explicit Node(const Key& k) : key(k) { }
Key const key;
Node* Next(int n) {
return reinterpret_cast<Node*>(next_[n].Acquire_Load());
}
void SetNext(int n, Node* x) {
next_[n].Release_Store(x);
}
Node* NoBarrier_Next(int n) {
return reinterpret_cast<Node*>(next_[n].NoBarrier_Load());
}
void NoBarrier_SetNext(int n, Node* x) {
next_[n].NoBarrier_Store(x);
}
private:
port::AtomicPointer next_[1];
};
leveldb 的 skiplist 的结构没什么特别的,查找和插入算法和不支持并发的区别也不大:
- 查找:从最高层开始向右、向下查找。
template<typename Key, class Comparator> typename SkipList<Key,Comparator>::Node* SkipList<Key,Comparator>::FindGreaterOrEqual(const Key& key, Node** prev) const { Node* x = head_; int level = GetMaxHeight() - 1; while (true) { Node* next = x->Next(level); // read-acquire if (KeyIsAfterNode(key, next)) { x = next; } else { if (prev != NULL) prev[level] = x; if (level == 0) { return next; } else { level--; } } } } - 插入:查找算法会保存查找过程中每层中向下的结点,也就是被插入节点每层的
prev结点,最后将被插入结点插入在prev[]后。template<typename Key, class Comparator> void SkipList<Key,Comparator>::Insert(const Key& key) { Node* prev[kMaxHeight]; Node* x = FindGreaterOrEqual(key, prev); int height = RandomHeight(); if (height > GetMaxHeight()) { for (int i = GetMaxHeight(); i < height; i++) { prev[i] = head_; } max_height_.NoBarrier_Store(reinterpret_cast<void*>(height)); } x = NewNode(key, height); for (int i = 0; i < height; i++) { x->NoBarrier_SetNext(i, prev[i]->NoBarrier_Next(i)); prev[i]->SetNext(i, x); // write-release } }
需要注意的是使用 AtomicPointer 的地方:
Skiplist::AtomicPointer max_height_:- 插入:使用
NoBarrier_Store设置。 - 查找:使用
NoBarrier_Load读取。
- 插入:使用
Node::AtomicPointer next_[1]:- 插入:设置被插入结点的
next_[]时用的是NoBarrier_Store,设置prev结点的next_[]时使用Release_Store。 - 查找:使用
AcquireLoad读取next_[]。
- 插入:设置被插入结点的
前面的 AtomicPointer 分析可知:成对 Acquire_Load/Release_Store 能够保证在不同线程间立刻可见,且 Release_Store 之前的修改对 Acquire_Load 之后立即可见。因为查找是按照从高层向低层、从小
到大的顺序遍历,而插入的时候是按照从低层到高层、用 Release_Store 设置 prev 结点的 next_[],确保了当观察到新插入的结点时,后续的遍历一定是个完好的 skiplist。
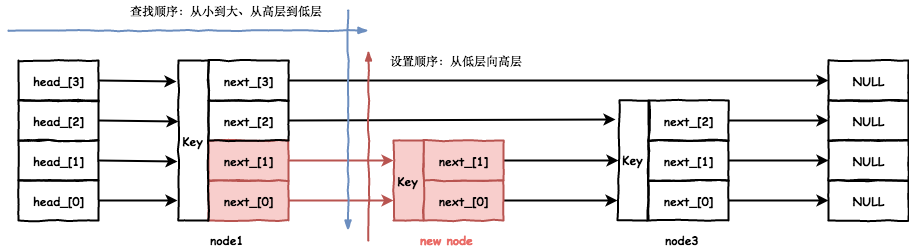
查找操作只会有下面2种情形:
- 观察不到新插入的结点。
- 在某一层观察到新插入的结点,且更低层也会观察到,也就是完好的
skiplist。
当读写同时发生时,上述两种情况都有可能发生,但都不会影响正确的结果,因为不会查找正在插入的 key(Sequence 只有写操作完成才会更新)。
需要注意一点,max_height_ 只保证了原子性,没有保证对 max_height_ 可见性,也没有保证对 next_[] 的可见性,但都不会影响读的结果。假设插入增大了 max_height_:
- 读操作观察到了
max_height_的更新,对应上面两种情况分别是:- 新增的
level的head_都指向NULL,leveldb保证了skiplist中NULL是最大的,所以会立刻向下层查找。 - 在某一层观察到了新插入的
key,继续遍历。
- 新增的
- 读操作未观察到
max_height_的更新,直接从低层开始遍历不影响skiplist的查找。
而当写之后再读刚写入的 key 时,因为写已经完成,一定会观察到新插入的 key。写之后写我个人觉得有点问题,写操作使用了查找操作来获取需要设置的 prev 结点,但是遍历的时候不能保证获取到最新的 max_height_,
所以设置 prev[] 时高层会有问题。但是注释写到插入操作时有外部同步:
TODO(opt): We can use a barrier-free variant of FindGreaterOrEqual() here since Insert() is externally synchronized.
我没找到外部同步,但如果有外部同步的话,就确保了插入操作一定能观察到最新的 max_height_ 和 node,可以保证写操作的安全。
arena
leveldb 自己实现了一个内存分配器 arena,用于分配 Node 和 Key 的空间,实现很简单,分配大小一般为 4KB 的 block,然后从 block 中分配需要的大小和对齐要求,对齐很重要,否则 AtomicPointer 就不是
原子操作了。
leveldb 使用了类似 C 语言柔性数组的特性分配 Node,多分配的内存会用作 next_[]:
template<typename Key, class Comparator>
struct SkipList<Key,Comparator>::Node {
Key const key;
private:
port::AtomicPointer next_[1];
};
template<typename Key, class Comparator>
typename SkipList<Key,Comparator>::Node*
SkipList<Key,Comparator>::NewNode(const Key& key, int height) {
char* mem = arena_->AllocateAligned(
sizeof(Node) + sizeof(port::AtomicPointer) * (height - 1));
return new (mem) Node(key);
}
arena 的优点我没想出来,难道是为了速度,还是为了更方便的获取 memtable 的大小,还是为了释放 memtable 的方便?(更新:最近在看《Effective C++》,条款 50 中写道:经常一起使用的数据可使用
placement new 来减少 page faults)使用 arena 带来的另一个问题是,因为 skiplist 是线程安全的,所以要保证
arena 也是线程安全的,leveldb 中 arena 的实现并不是线程安全的,所以我相信如上面注释所说的,一定有外部同步我没有注意到,或者对可见性理解有错误。
lock-free 编程是个大坑,了解一番之后感觉连基本的多线程编程模式都要怀疑了,需要系统的学习一下。
更新(2018-10-10)
临界区主要有这几个作用:
- 保证只有一个线程能进入,临界区内的操作是原子的。
- 临界区内的修改是可见的。
我以前一直认为在临界区内的修改才是可见的,这是错误的。可见性是由 acquire/release 保证的,lock 是 read-acquire,unlock 是 write-release,unlock 保证了之前的修改一定对 lock 之后可见,包括不在临界区内的。
这也就是 leveldb 的外部同步:leveldb 在写 WAL 和 memtable 时是不持有锁的,但是之前抢占队首和之后通知其他线程时是有 lock/unlcok 操作的,读的时候也要 lock 获取 Sequence, 在这里保证了可见性。
留下评论