leveldb 源码分析(二) – Architecture
整体架构
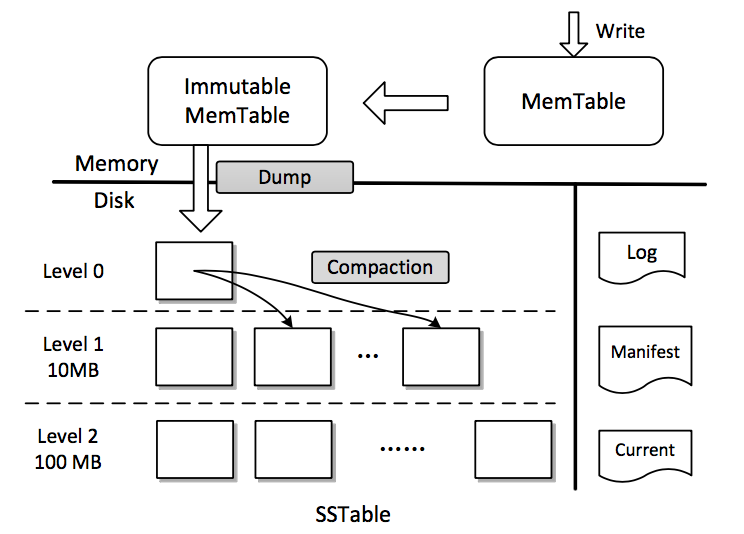
leveldb 的架构图如下:
LSM-Tree
leveldb 是以 LSM-tree 为模型实现的。LSM-tree 将随机写转换为顺序写从而获得更高的写性能,大致思路如下:
- 数据分为2部分存储,共同维护一个有序的空间:
- 内存中维护最新的写数据
memtable,所有的写操作都在内存中进行,同时顺序写WAL。 - 磁盘上维护较老的数据
sstable。 - 读操作先读内存中的数据,然后读磁盘上的数据。
- 内存中维护最新的写数据
- 在合适的时机进行
compaction:- 当内存中的数据大小超过阈值时,刷新到磁盘上。
- 在合适的时机清理、合并磁盘上的数据。
LSM-tree 是一种设计思想,没有固定的实现方式,其中最重要的是 compaction 的实现,涉及到 compaction 的时机、 sstable 的组织方式、
memtable 和 sstable 间的合并方式。compaction 对读写性能起着至关重要的影响,它会清理无用数据,能够降低磁盘空间使用并降低读的延迟,但是也会带来极大的 I/O 压力。
compaction 主要考虑如下几个因素:
- 写放大: 要减少
compaction时涉及到的无关数据量。 - 读放大: 减少读数据时,读取的无关数据量。
- 随机
I/O: 尽量减少随机I/O。
考虑最基本的情况,磁盘上维护一个大的 sstable,当 memtable 大小超过阈值时,就与磁盘上的 sstable 合并。可以是 in-place 的修改,可能伴随着很多随机 I/O,或者顺序写生成新的 sstable,
但可能要将整个 sstable 进行重写,会带来极大的写放大。现在只关注后面一种方式,一步步进行优化:
- 不是每次
memtable大小超过阈值就与sstable合并,而是将memtable转储为sstable,当到了一定数量后批量合并,从而减少合并的次数。同时需要控制sstable的数量,因为读可能需要读每个sstable,数量太多会降低读的性能。 - 但每次合并仍有可能将整个
sstable重写,为了降低写放大,将大的sstable划分为多个小的、不重叠的sstable,这样sstable就分为2层:level-0是memtable直接转换而来,文件之间有重叠;level-1由level-0合并而来,文件之间无重叠。当level-0的文件个数达到上限时,只要挑选level-1中和level-0文件有重叠的合并即可,读level-1也只要读一个文件。 但仍有可能level-1中所有的sstable都需要合并,所以又要限制level-1的大小。 - 当
level-1的sstable达到上限时,使用类似的方法compaction为level-2的sstable。level-2达到上限,再compaction为level-3……
leveldb 就是类似上面的思路分层管理 sstable,所以叫 leveldb。现在看一下它的实现:
memtable由skiplist实现,只有追加操作,每个操作先顺序写到log中。- 当
memtable大小超过阈值时(默认为4MB),变为immutable memtable,在后台线程compaction为level-0的sstable。 sstable的大小固定,默认为2MB。- 共分为
7层:level-0由memtable直接转化而来,文件之间有重叠。当level-0的sstable数量到达阈值时,会将level-0中相互重叠的sstable和level-1中重叠的sstable合并为新的level-1的sstable。- 其余
level由低层compaction而来,除最高层外,每层有大小限制,level-(N+1)的大小限制是level-N的10倍,其中level-1为10MB。相同level的文件之间无重叠。当level-N的sstable大小到达阈值时,会挑选一个文件(可能不止一个)和level-(N+1)中有重叠的sstable合并为新的level-(N+1)的sstable。
- 所有的写操作,包括
compacion都是顺序写。 - 读的顺序如下,只要读到对应的
key就会停止:memtableimmutable memtablelevel-0中文件有重叠,从新到旧读取- 其余
level文件不重叠,每层最多只要读 1 个文件,按照层的顺序从低到高读取
并发控制
leveldb 使用 MVCC 实现并发控制,不支持事务,支持单个写操作和多个读操作同时执行:
- 每个成功的写操作会更新
db内部维护的顺序递增的sequence,sequence会追加到key后一同保存。 - 读操作会使用当前最新的
sequence(或者使用传入的snapshot),只会读到小于等于自己的最大的sequence数据。
因为 compaction 会改变磁盘上文件的组织,为了不影响正在进行的操作,leveldb 使用 VersionSet 维护不同版本的 sstable 组织,每当有文件删除或增加时,就会创建新的
Version 插入到 VersionSet。只有当一个 sstable 不再被任意 Version 使用时才会进行删除。
数据恢复
leveldb 中每个 db 对应一个目录,目录名即 dbname。目录下有如下几种文件:
LOG: 记录操作日志。*.log: 记录memtable的WAL。*.ldb(*.sst):sstable文件。MANIFEST-*: 记录元信息,如sstable的组织结构,每个sstable的key range等。CURRENT: 记录当前的MANIFEST文件名。LOCK:leveldb不支持多个进程同时打开相同db,会加文件锁。
数据恢复主要就是通过 CURRENT 文件找到当前的 MANIFEST 文件读取之后进行清理和恢复操作。
留下评论