leveldb 源码分析(四) – Compaction
compaction 和读密切相关,sstable 文件的格式、sstable 的组织都会影响读的性能。leveldb 的 compaction 有两种:
memtable大小超过阈值时,转储为level-0的sstable。sstable的compaction。
compaction 的思路在之前的文章 有介绍,不再赘述。
sstable
对 sstable 的操作只有2种:从 sstable 中查找 key和遍历 sstable。所以对 sstable 的要求如下:
- 生成时要顺序写。
- 支持高效的查找。
- 要支持遍历。
sstable 的格式如下:
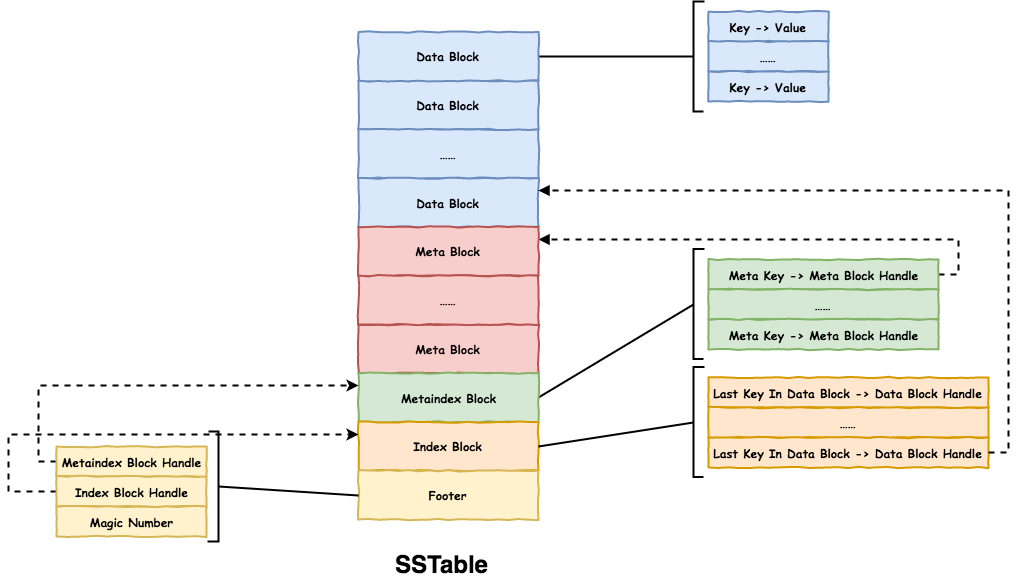
sstable 划分为 Block 存储,不同 Block 存储不同的数据:
Data Block:有序存储key value数据。Meta Block:存储metadata,目前leveldb中只存储filter信息。Metaindex Block:handle用于索引Block,包括Block的offset和size。Metaindex Block保存Meta Block的索引,目前只保存filter.name和filter Block索引。Index Block:保存每个Data Block最后一个key和该Data Block的索引。Footer:固定48 Bytes,保存Metaindex Block和Index Block的索引,是解析的起点。
sstable 生成时按顺序写入。当读取某个 key 时,按照如下顺序:
- 解析
Footer,找到Metaindex Block和Index Block的位置。 - 查找
Index Block找到key属于的Data Block的位置。 - 在
Data Block中查找key。 - 若是有
filter,会在查找Data Block前先查找filter,只有存在时才查找Data Block。
leveldb 在读取 sstable 时会把整个文件映射进来(mmap),查找很高效。
Block
Block 保存 key/value 对,并会进行压缩和校验(checksum),格式如下:
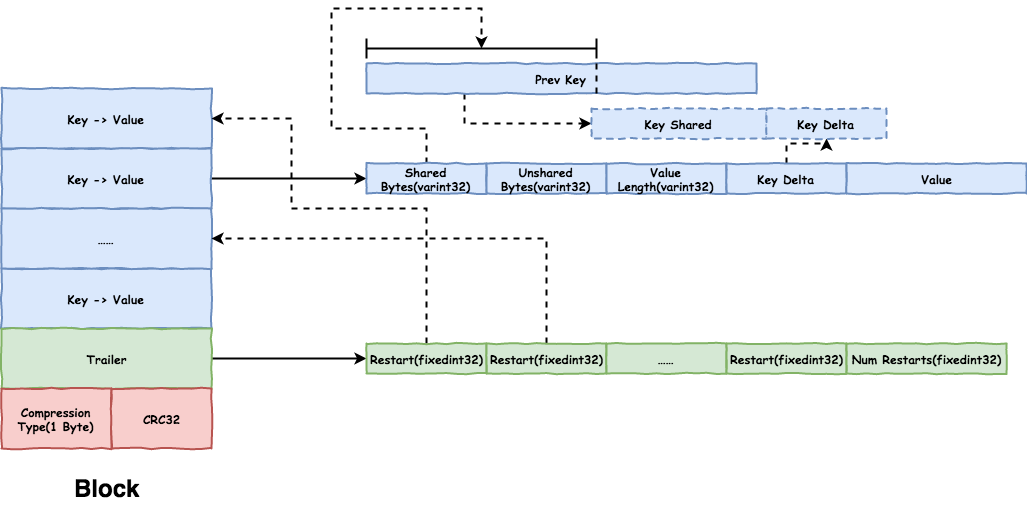
Block 中第一个 key 是完整的,按顺序解析时,通过拼接和前一个 key 重叠的加上 Delta 部分即可得到当前完整的 key。按顺序存放的 key 之间很可能会有重叠,
尤其是 leveldb 中很多 key 只有 sequence 不同,使用这种存储方式能够极大的降低数据存储量。因为 Block 的大小可能很大,
如 leveldb 默认配置 Data Block 大小为 4KB,存放的 key/value 可能很多,每次查找都要从头开始会很慢,而且只要开头的完整 key 有损坏,整个 Block 的数据都无法使用。
Block 增加了 restart points 来解决这些问题:
- 每隔一定数量的
key/value会有一个restart point,如Data Block默认间隔为16。restart point的shared bytes为0,存放完整的key。 Trailer中记录restart points的offset,查找时先二分查找restart points找到key所在的起始restart point,然后顺序查找即可,避免了从头开始查找。
Block 的查找算法如下:
- 二分查找
restart points:找到最后一个key < target的restart point。 - 然后从
restart point开始顺序遍历,直到找到第一个key >= target。
Block 还会进行压缩和校验,目前只支持 snappy 压缩。Block 不强制存放 key/value,如 filter Block 中只存放了 filter。
Data Block
Data Block 按照上面格式存放 key/value,其中 key 是 InternalKey 的格式,包括 sequence 和 type,value 格式不变。当 Data Block 的大小超过配置的 block_size(默认为 4KB)时,
会创建一个新的 Data Block。
需要注意根据 Block 的查找算法,若查找的 key 正好是 restart point,那么会从上一个 restart point 开始查找,不影响功能正确,但会多遍历一些 key。
Meta Block
目前 leveldb 中只有 filter 一种 metadata。leveldb 中使用 bloom filter,用于快速判断 key 是否存在,它的原理如下:
- 对于一个
key集合,使用固定大小的位图,假设key的个数为n,位图大小为m bits。 - 集合内每个
key计算出一组hash值,将对应的bit置位,假设每个key使用k bits。 - 查询
key时使用相同的算法计算出k bits,若每个bit都为1,则这个key很可能存在;若不都为1,则这个key一定不在。
bloom filter 的关键就是降低 false positive 的概率,false positive 即 bloom filter 认为这个 key 存在但不存在,它的概率如下:
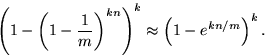
一般情况下,key 的数量是已知的,位图的大小是根据 key 个数决定的,那么 n 和 m 是固定,最优的 k 为: k = ln2 * m/n。m/n 即 bits_per_key,
所以 leveldb 中 bloom filter 会乘以 ln2(0.69) 得到 hash 的次数,不过并不是计算多次 hash,而是计算一次 hash,
之后的 bit 直接加上一个 delta 得到,避免了多次 hash 带来的性能消耗:
explicit BloomFilterPolicy(int bits_per_key)
: bits_per_key_(bits_per_key) {
// We intentionally round down to reduce probing cost a little bit
k_ = static_cast<size_t>(bits_per_key * 0.69); // 0.69 =~ ln(2)
if (k_ < 1) k_ = 1;
if (k_ > 30) k_ = 30;
}
Filter Block 的格式如下:
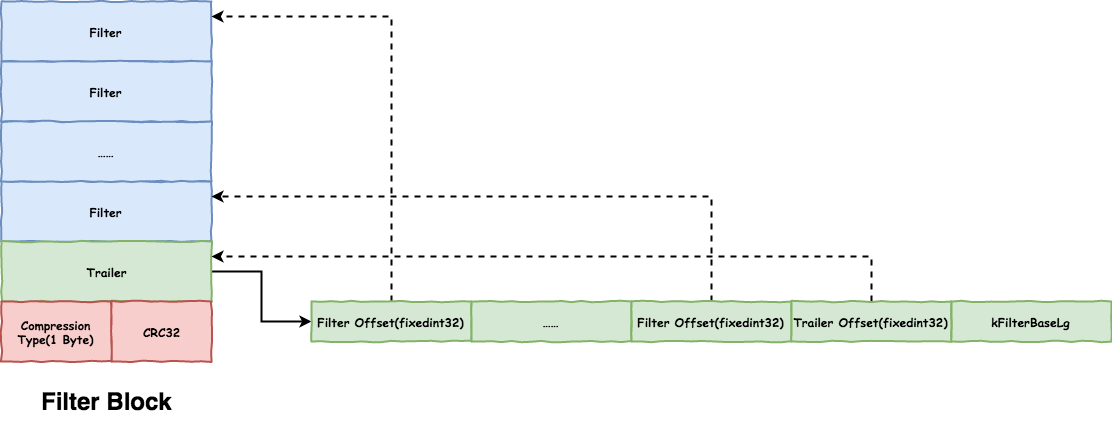
leveldb 是为每个 Data Block 创建一个 bloom filter,要注意创建 bloom filter 的 key 要是 UserKey 而不是 InternalKey。
需要查找某个 Data Block 前,先查找该 Block 对应的 bloom filter,这就带来另一个需求,快速查找 Data Block对应的 bloom filter。leveldb 使用如下方式:
- 为每个
Data Block生成一个Filter。 - 按照
Data Block的offset生成filter索引,目前是每2KB(1 << kFilterBaseLg)生成一个。当查找Data Block对应的filter时,只要 查找第Data Block Offset >> kFilterBaseLg个Filter Offset即可。按照2KB划分的原因是因为Data Block的大小不固定,超过4KB会切换到新的,但可能会超很多。
其实感觉为整个 sstable 生成一个 bloom filter 即可。
Metaindex Block
目前只存放 filter.name 到 Filter Block 的索引。
Index Block
Index Block 保存 Data Block 的索引,且每个 key 都是 restart point:
key:大于等于该DataBlock最后一个key,小于后一个DataBlock第一个key。这么做可以降低存储的数据量,比如最后一个key很长,但比它大且比后一个小的key很短。Value:该Block的offset和size。
存放每个 DataBlock 最后一个 Key 而不是第一个 Key 的原因是,DataBlock 找到的是第一个大于等于 target 的。
Footer
Footer 是解析的起点,大小固定为 48 Bytes:
Metaindex Block Handle:20 bytes,offset和size都使用varint64存储。Index Block Handle:同上。Magic Number:用于判断检测文件有效性。
Compaction
之前提到过 leveldb 是分层管理 sstable 的,level-0 的 sstable 之间有重叠,其他 level 的 sstable 之间无重叠。读是从 level-0 开始从低往高查找,
当查找到第一个 key 相同且 sequence 小于等于 target key 的就会停止,需要保证一个 key 的高版本(sequence 大)所在的 sstable 层高一定要小于等于低版本的层高,
这样才能保证查找到的 key 是最新的。
compaction 分为两种:
memtable compaction:memtable直接转储为sstable。sstable compaction:将level-n的一个sstable和level-(n+1)重叠的sstable合并生成新的level-(n+1)的sstable。
因为 level-0 的 sstable 间有重叠,为了保证上面的结构,会把 level-0 中所有重叠的 sstable 和 level-1 中重叠的 sstable 合并生成新的 level-1 的 sstable。
将 level-0 所有重叠 sstable 合并保证了旧的 key 不会在更低层;低层和高层的重叠 sstable 合并保证了高层的 sstable 之间无重叠。
sstable 由 file number 区分,file number 顺序递增,越大文件越新,查找 level-0 时就会按照新旧程度排序,先查找新的 sstable。还会记录每个 sstable 的 key range,
只要查找相匹配的即可。
Memtable Compaction
当 memtable 大小超过 Options.write_buffer_size 时(默认 4MB),会在下一次写操作时将当前的 memtable 转为 immutable memtable,创建新的 memtable,并触发
immutable memtable 的 compaction。compaction 会由单独的线程来执行。
memtable compaction 的过程很简单,顺序遍历 memtable 将所有的 key/value 转储为 sstable 格式即可(不会清理无用数据),生成的 sstable 不一定在 level-0,只要满足上面的保证即可。
要注意的是,leveldb 为了防止 sstable 数量太多会对写操作进行流控:
- 当
level-0 sstable数量达到kL0_SlowdownWritesTrigger(8)时,每个写操作会sleep(1ms)。 - 当前
memtable已满需要compaction但之前的immutable memtable compaction还未完成时,会等待之前的完成。 - 当
level-0 sstable数量达到kL0_StopWritesTrigger(12)时,会等待level-0 compaction完成。
Sstable Compaction
触发 sstable compaction 的条件如下:
level-0:sstable文件个数超过kL0_CompactionTrigger(4)。因为level-0是从sstable直接转储而来,所以用个数限制而不是大小。- 其他
level:高层的sstable会按照max_file_size(2MB)进行切割,当一层的sstable总大小超过阈值时会触发,最高层无大小限制。 - 每个文件还有
seek的次数限制,超过次数会进行compaction,防止读多写少的场景下,compaction不会触发。
挑选参与 compaction 的文件分2步:
- 执行
compaction的level:leveldb会记录每个level上次compaction的最大的key,下一次时会挑选在这之后的文件,防止后面的文件一直不会被选到。 - 高一层的文件:挑选和低一层的文件有重叠的所有文件。高一层的总的
key range可能会覆盖到更多的低一层的文件,所以会进行expand,同时为了防止compaction太大, 会有一定的限制。
sstable compaction 的过程也比较简单,和 memtable compaction 的区别在于,这里是多个文件,类似 merge sort 的流程,leveldb 中也实现了 MergingIterator 用于
在多个迭代器的情况下有序迭代。需要关注的是无用数据的清理,每个 key 会有多个版本,再也不会访问到的版本不需要保留。leveldb 支持 snapshot,也就是 sequence,在其内部维护了一个 SnapshotList,
保存着所有正在使用的 snapshot,会根据当前使用到的 smallest snapshot 进行清理(若没有则是 last sequence):
- 只需要保存
smallest snapshot能够访问到的及更高版本的,即保存第一个小于等于smallest snapshot的版本及更高版本即可。 - 若第一个小于等于
smallest snapshot的版本是删除操作,只要高层没有这个key也可以丢弃这个版本。
高层的 sstable 会进行切割,除了大小限制 max_file_size(2MB) 外,还会防止该文件与更高一层的 sstable 重叠太多,会导致该文件的 compaction 消耗很大。同时在 sstable compaction
的过程中若发现存在 immutable memtable,会进行 memtable compaction,防止阻塞写操作。
Manifest
除了 sstable 文件,还有一些 metadata 需要保存,如当前的 sequence、file number 和 sstable 的组织结构等,manifest 文件就用来保存这些数据。leveldb 不是
每次 metadata 发生变化就修改 manifest,而是当 compaction 完成时,写入一条 VersionEdit 数据,因为大部分 metadata 只有 compaction 完成才会变化。
VersionEdit 结构如下:
class VersionEdit {
typedef std::set< std::pair<int, uint64_t> > DeletedFileSet;
std::string comparator_; // 用于检测文件是否和 db 的 comparator 匹配
uint64_t log_number_; // 当前 memtable 的 log file number
uint64_t prev_log_number_; // 之前的 memtable 的 log file number
uint64_t next_file_number_; // 最新的 file number
SequenceNumber last_sequence_; // 最新的 sequence
std::vector< std::pair<int, InternalKey> > compact_pointers_; // 每层下一次 compaction 的位置
DeletedFileSet deleted_files_; // 删除的文件
std::vector< std::pair<int, FileMetaData> > new_files_; // 新增的文件
};
manifest 结构和 memtable log 相同,VersionEdit 的编码也很简单,通过前缀 type 区分数据类别,就不再赘述了。
VersionEdit 中大多是增量数据,顺序累积回放 mainifest 即可得到完整的最新的 metadata。这种记录方式使得 manifest 也都是顺序写,同时减少了
需要记录的数据量。
manifest 中除了记录当前 memtable 对应的 log file 还需要记录 immutable memtable 的 log file,只有当 immutable memtable compaction 时
才可以删除对应的 log file。manifest 中记录的 sequence 并不是最新的,重启 db 时会根据 log file 恢复到最新。
manifest 在 db 打开时一直追加,不会进行清理,只有下一次打开时才会清理。若不幸 manifest 文件有所损坏或者被删除了,leveldb 也提供了修复的方式,所有的 metadata 除了 sstable 的组织结构外,都可以
通过 sstable 和 log 文件恢复,同时会将 log 转换为 sstable 并认为所有的 sstable 都处于 level-0,然后将修复后的 metadata 写入 manifest。会在打开 db 时立刻触发一次 compaction,因为
所有文件都在 level-0 所以 compaction 耗时会很久。
Write Error
值得一提的是若和写文件相关的操作出错,leveldb 会设置 bg_error_,此时会拒绝写请求并不会触发 compaction,而且没有方式清空 bg_error_,只能重启进行修复。其实这里可以使用类似
Redis 的策略,当写操作失败时,truncate 掉 short write 部分并进行重试,当成功写入时恢复状态并接收写请求。
留下评论