leveldb 源码分析(五) – Read
有了之前的铺垫,leveldb 的读操作就很显然了。按照数据的新旧依次读:
memtableimmutable memtablelevel-0中按照file number倒序level1 -> level-6
因为 leveldb 保证了更新的数据一定会比旧的数据先找到,所以当找到第一个 key 相同且 sequence 小于等于 target key 的就停止。
Cache
leveldb 中使用 LRU cache 来提高读的性能,compaction 时也会从 cache 中获取数据,有两种 cache:
TableCache:缓存打开的sstable,容量为max_open_files(1000)。BlockCache:缓存读取的Data Block,默认容量为8MB。
leveldb 中优先使用 mmap 将整个 sstable 映射进内存,失败时才会打开为文件读取,两种实现分别继承 RandomAccessFile 实现多态。
在创建 Table 时会读取 index block 和 filter block,data block 会按需读取。当 sstable 是 mmap 进来的时,BlockCache 就没用了,因为所有
数据都已缓存在 TableCache 中,只有文件类型的 Table 才会使用 BlockCache。
LRU Cache
leveldb 中实现的是并发安全的 LRU cache。实现也很简单:
- 由
list、hashtable实现的LRUCache,由mutex保护,保证并发安全。 - 为了减少锁的竞争,在
LRUCache基础之上实现了ShardedLRUCache,共有16个LRUCache,使用时会shard到指定的LRUCache。
因为 LRUCache 会有多个线程使用,需要做一些特殊处理:
- 引用计数:使用引用计数保证数据使用时的有效性,因为有可能被淘汰的数据仍有线程在使用。
- 使用
2个链表保存数据:lru_:保存存放在cache中且没有线程使用的数据,链表尾保存最近使用的数据。in_use_:保存存放在cache中且被使用到的数据,无特定顺序,只有当没有使用到时(ref==1)才会追加到lru_尾部,保证了是按照least-recently used而不是least-recently requested淘汰。
Snapshot
之前也提到过 leveldb 支持 snapshot:使用 SnapshotList 记录所有的 snapshot,在 compaction 时会保留所有有可能被 snapshot 访问到的数据,ReleaseSnapshot 就是
把该 snapshot 从 SnapshotList 中移除,就不再赘述了。
leveldb 不会持久化 snapshots,因为重启时所有 snapshots 就无效了。
VersionSet
还有很重要的一环是保证读取数据时的有效性,比如读 memtable 时,要保证该 memtable 是有效的;使用 snapshot 时,要保证对应版本的数据要存在;遍历 db 时,要保证提供
一致的数据。memtable 使用引用计数保证了有效性,compaction 的实现保证了 snapshot 对应的数据不会被清理,而对外提供 db 一致的数据就由 VersionSet 保证。
VersionSet 记录了所有的 metadata,同时保存了一个 Version 链表,Version 记录的是当时版本的 sstable 组织结构,只有每次 compaction 完成时才会改变 sstable 的
组织结构并增加一个新的 Version(图来自CatKang):
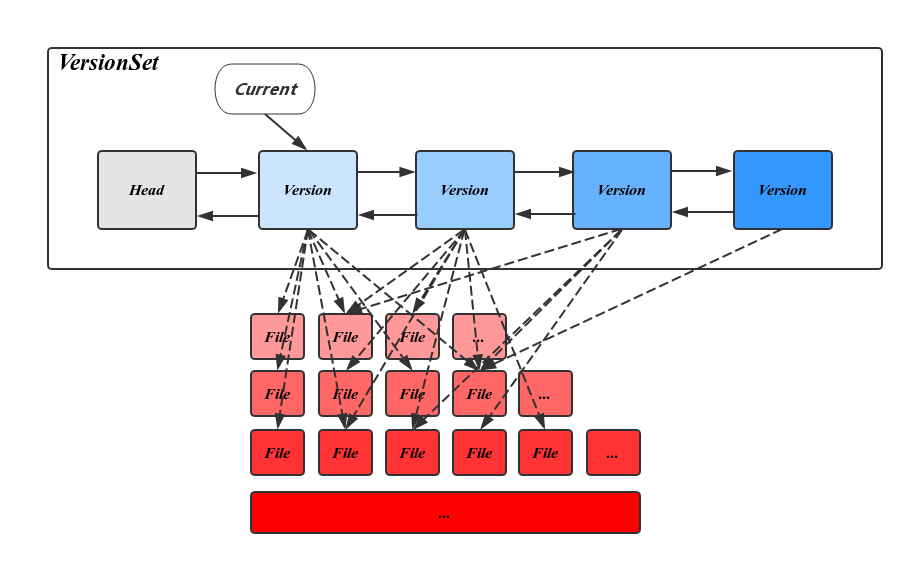
Version 与 Version 之间的增量就是 manifest 中记录的数据 VersionEdit:

Version 同样使用引用计数保护,当引用计数为 0 时会从 VersionSet 中移除,leveldb 保证了所有被 Version 使用到的 sstable 文件不会被删除,从而提供了一致的数据。当用 Iterator 遍历
整个 DB 的数据时,就会增加当前 Version 的引用计数。
重启时会根据 manifest 中的 VersionEdit 恢复并只保留最新的 Version,并清理无用数据。
Iterator
leveldb 支持对 db 的遍历,在其内部也实现了多种 Iterator 用于查询、顺序遍历数据,Iterator 为上层提供了统一的接口,封装了底层的存储细节。Iterator 按功能分为如下几类:
Iterator:提供最基本的查询数据的能力,用在memtable的查询、block的查询等。TwoLevelIterator:传入一个Iterator和函数指针,以Iterator的数据作为参数调用函数生成新的Iterator,相当于传入的是Iterator的Iterator,用在 遍历非0层的sstable、遍历sstable等。MergingIterator:传入多个Iterator,用类似merge sort的思路,产生有序的结果,用在不同level间的sstable遍历等。
TwoLevelIterator 和 MergingIterator 将基本的 Iterator 组合起来,提供了极大的灵活性。以遍历整个 db 为例,会将 memtable Iterator、immutable memtable Iterator、
level-0 的各个 sstable Iterator、其他 level 的 ConcatenatingIterator 组合为 MergingIterator 来遍历,需要注意的是,遍历 db 时会有许多版本(sequence)的 key,
需要返回的是能访问到的最新的版本(若不传入 snapshot 则默认 snapshot 为当时最新的)。
留下评论