Raft 笔记(六) – Cluster membership change
Cluster membership change
在生产环境中,有时需要改变集群配置,比如更换坏掉的节点、改变副本的个数,需要在保证 safety 的前提下完成:不能在同一 term 有多个 leader,否则可能存在 term 和 index 相同但内容不同的 log entry。
不能直接从当前配置转变为新配置,因为各节点变化的时机不同,可能存在如下场景:采用不同配置的两部分,各选举出新的 leader。
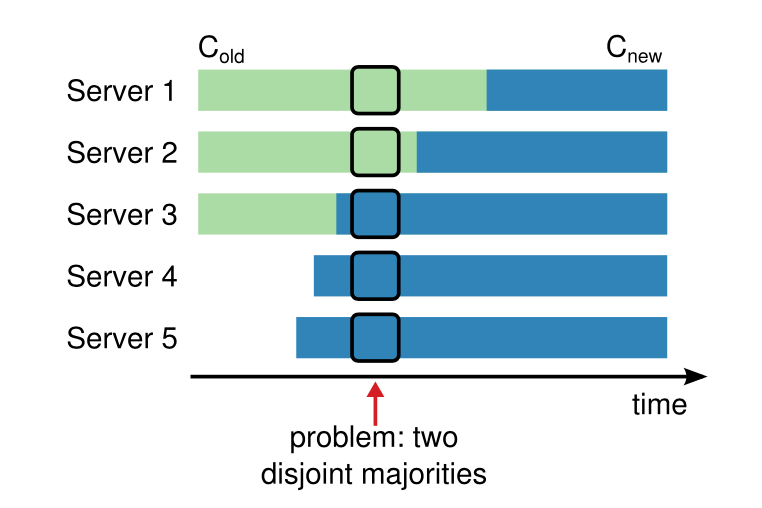
下面的两种算法都是基于不允许由单独一部分做出决定。
Add/Remove one node
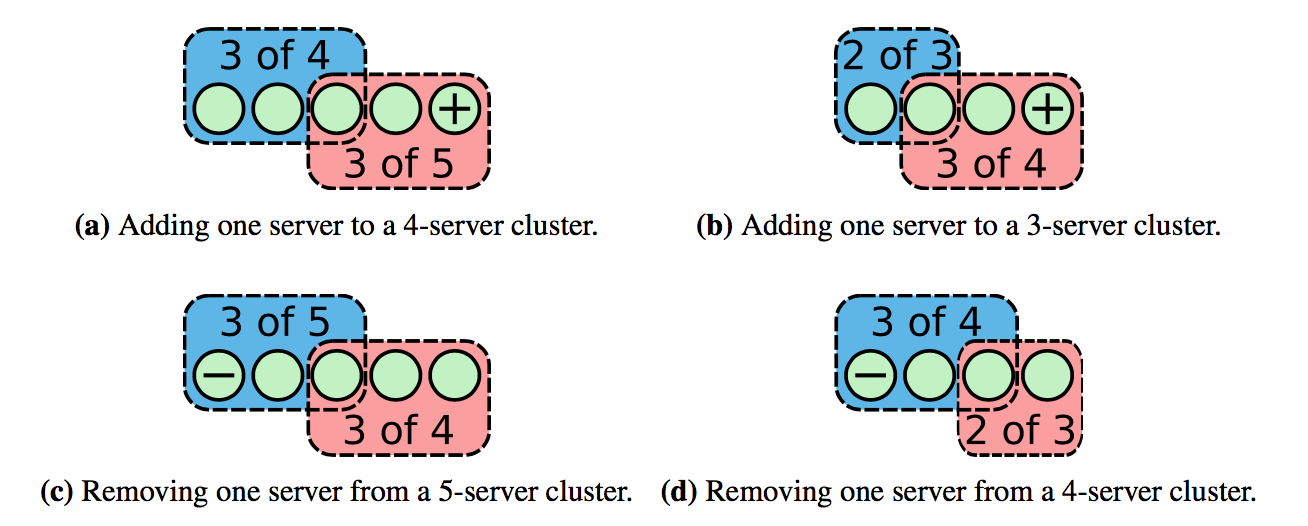
该算法每次只允许增加或移除一个节点,只有当上一轮成员变更结束,才能开始下一轮,复杂的成员变更转换为多次单个成员变更。
增加或删除一个节点时,新旧配置中构成 majority 的部分必有重叠,不会有单独一部分做出决定,保证了 safety:
当发起成员变更时,leader 会增加一个特殊的 log entry,然后通过 log replication 复制到其他节点上。raft thesis 中是节点接收到成员变更的 entry 时,就使用
新的配置,当该 entry 被 commit 后,意味着 majority 节点采用了新的配置,该次成员变更结束,可以开始下一轮。采用这种方式,节点配置需要能够回退,因为未 commit 的 entry 有可能被覆盖。
因为节点只有接收到 config change entry 才会改变配置,需要处理不在当前配置内的节点的消息:
- 节点需要接收不在自己集群成员内的
leader的AppendEntries,否则新加入的节点将永远不会加入到集群中(不会接收任何log); - 节点需要给不在自己集群成员内的节点投票,比如给3个节点的集群增加了第4个节点,当
leader挂了需要新增加的节点也可以投票; - 被移除的节点不会收到
heartbeat,可能会超时发起投票影响集群(因为上面第二点),使用check quorum和Pre-Vote可以解决。
etcd/raft 的实现有所不同:只有当成员变更的 entry 被 apply 之后,才使用新的配置(同样需要处理上面的问题)。raft thesis 中写道,但是我没有想到在某种情况下,使用 etcd/raft 的方式会有问题:
It is only safe to start another membership change once a majority of the old cluster has moved to operating under the rules of Cnew. If servers adopted Cnew only when they learned that Cnew was committed, Raft leaders would have a difficult time knowing when a majority of the old cluster had adopted it.
使用 etcd/raft 的方式需要注意: 从2个节点中移除一个时,若有一个节点挂了,则整个集群不可用,但是一般至少使用3副本。
etcd/raft 实现
调用 Node.ProposeConfChange() 来发起成员变更,因为也需要通过 log replication 来提交,所以复用了 pb.Entry,需要进行 marshal:
func (n *node) ProposeConfChange(ctx context.Context, cc pb.ConfChange) error {
data, err := cc.Marshal()
if err != nil {
return err
}
return n.Step(ctx, pb.Message{Type: pb.MsgProp, Entries: []pb.Entry{{Type: pb.EntryConfChange, Data: data}}})
}
pb.ConfChange 结构如下:
Type: 成员变更操作类型,包括增加节点、删除节点等;NodeId:etcd/raft中使用ID代表节点,ID必须非零且唯一(使用之前使用过的也不行);Context: 可以用来保存节点的地址。type ConfChange struct { ID uint64 `protobuf:"varint,1,opt,name=ID" json:"ID"` Type ConfChangeType `protobuf:"varint,2,opt,name=Type,enum=raftpb.ConfChangeType" json:"Type"` NodeID uint64 `protobuf:"varint,3,opt,name=NodeID" json:"NodeID"` Context []byte `protobuf:"bytes,4,opt,name=Context" json:"Context,omitempty"` XXX_unrecognized []byte `json:"-"` }
在 raft.StepLeader() 中会判断是否有未完成 config change,若存在,则忽略新的 config change:
for i, e := range m.Entries {
if e.Type == pb.EntryConfChange {
if r.pendingConfIndex > r.raftLog.applied { // 存在未完成的 config change
r.logger.Infof("propose conf %s ignored since pending unapplied configuration [index %d, applied %d]",
e.String(), r.pendingConfIndex, r.raftLog.applied)
m.Entries[i] = pb.Entry{Type: pb.EntryNormal}
} else {
r.pendingConfIndex = r.raftLog.lastIndex() + uint64(i) + 1 // 设置 pendingConfIndex 为 config change entry 的 index
}
}
}
当 config change 被提交了,调用 Node.ApplyConfChange() 来完成成员变更:
- 调用
raft的接口增加或删除节点:etcd/raft的实现很简单,就是操作raft.prs(NodeId到Progress的映射); - 返回最新的集群结构。
用户根据
config change的类型,决定是关闭节点,还是新建连接。
启动
在启动一个新的集群时,raft.StartNode() 中需要传入集群的 peer list,然后使用 config change 的方式添加节点,使用这种方式把启动时的成员配置和成员变更统一起来,简化了实现:
func StartNode(c *Config, peers []Peer) Node {
r := newRaft(c)
r.becomeFollower(1, None)
for _, peer := range peers {
cc := pb.ConfChange{Type: pb.ConfChangeAddNode, NodeID: peer.ID, Context: peer.Context}
d, err := cc.Marshal()
if err != nil {
panic("unexpected marshal error")
}
e := pb.Entry{Type: pb.EntryConfChange, Term: 1, Index: r.raftLog.lastIndex() + 1, Data: d}
r.raftLog.append(e)
}
r.raftLog.committed = r.raftLog.lastIndex()
for _, peer := range peers {
r.addNode(peer.ID)
}
n := newNode()
n.logger = c.Logger
go n.run(r)
return &n
}
README 中只传入了其他节点的 ID,不包含自己的,应该有问题,peer list 应该包含所有节点的 ID,否则节点的 log 有冲突,新加入节点的成员配置也会出错。
当需要新增一个节点时,首先给集群发起成员变更,然后不用传入 peer list 启动节点,集群配置会在 log replication 过程中同步到新节点:
n := raft.StartNode(c, nil)
Snapshot
raft 的集群配置通过 log replication 传递,同样也通过 log 来恢复,通过一个个应用 log entry 能够恢复到一致的集群成员配置。之前提到 snapshot 只保存了状态机的状态,为了支持成员变更,
snapshot 中需要保存该 snapshot 对应的集群成员配置:
type SnapshotMetadata struct {
ConfState ConfState `protobuf:"bytes,1,opt,name=conf_state,json=confState" json:"conf_state"`
Index uint64 `protobuf:"varint,2,opt,name=index" json:"index"`
Term uint64 `protobuf:"varint,3,opt,name=term" json:"term"`
XXX_unrecognized []byte `json:"-"`
}
type ConfState struct {
Nodes []uint64 `protobuf:"varint,1,rep,name=nodes" json:"nodes,omitempty"`
Learners []uint64 `protobuf:"varint,2,rep,name=learners" json:"learners,omitempty"`
XXX_unrecognized []byte `json:"-"`
}
Learner
加入新的节点有可能降低集群的可用性,因为新的节点需要花费很长时间来同步 log,可能导致集群无法 commit 新的请求,比如原来有 3 个节点的集群,可以容忍 1 个节点出错,然后新加入了一个节点,
若原先的一个节点出错会导致集群不能 commit 新的请求,直到节点恢复或新节点追上:
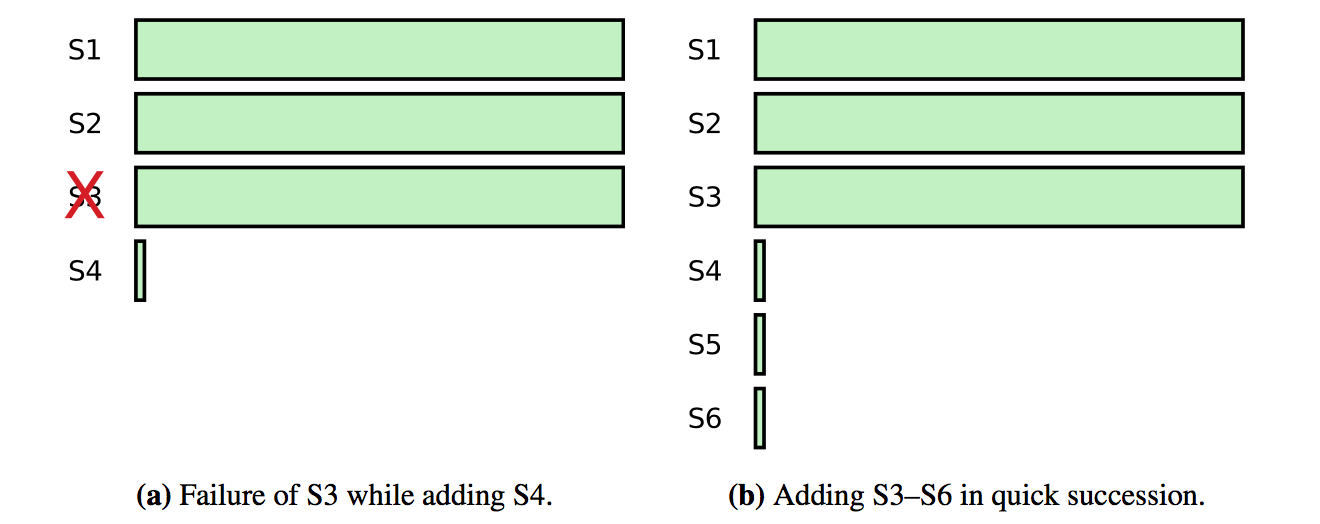
为了避免这个问题,可以引入 learner 状态,新加入的节点设置为 learner 状态,该状态的节点不计在 majority,也就不参与投票和 commit,
当 learner 追上集群的进度时,提升为正常的节点,完成 config change。
etcd/raft 增加了 learner 特性,但是没有投入使用,也没有实现判断 learner 进度。过程和上面类似,只是设置 ConfChangeType 为 ConfChangeAddLearnerNode。etcd/raft 使用 raft.learnerPrs 保存
learner 节点的 NodeId 到 Progress 的映射,当应用成员变更时,调用 raft.addNodeOrLearnerNode() 添加到 raft.learnerPrs 中:
func (r *raft) addNodeOrLearnerNode(id uint64, isLearner bool) {
pr := r.getProgress(id)
if pr == nil {
r.setProgress(id, 0, r.raftLog.lastIndex()+1, isLearner)
} else {
if isLearner && !pr.IsLearner {
// can only change Learner to Voter
r.logger.Infof("%x ignored addLearner: do not support changing %x from raft peer to learner.", r.id, id)
return
}
if isLearner == pr.IsLearner {
// Ignore any redundant addNode calls (which can happen because the
// initial bootstrapping entries are applied twice).
return
}
// change Learner to Voter, use origin Learner progress
delete(r.learnerPrs, id)
pr.IsLearner = false
r.prs[id] = pr
}
if r.id == id {
r.isLearner = isLearner
}
// When a node is first added, we should mark it as recently active.
// Otherwise, CheckQuorum may cause us to step down if it is invoked
// before the added node has a chance to communicate with us.
pr = r.getProgress(id)
pr.RecentActive = true
}
当判断 learner 节点追上其他节点,需要提升为正常节点时,需要再发起一次正常的成员变更。只允许 learner 变为 voter,不允许反过来。
learner 节点有如下特性:
- 当
election timeout时,不会成为candidate发起选举:func (r *raft) promotable() bool { _, ok := r.prs[r.id] return ok } - 不会给其他节点投票:
case pb.MsgVote, pb.MsgPreVote: if r.isLearner { // TODO: learner may need to vote, in case of node down when confchange. r.logger.Infof("%x [logterm: %d, index: %d, vote: %x] ignored %s from %x [logterm: %d, index: %d] at term %d: learner can not vote", r.id, r.raftLog.lastTerm(), r.raftLog.lastIndex(), r.Vote, m.Type, m.From, m.LogTerm, m.Index, r.Term) return nil } - 不计在
quorum中:func (r *raft) quorum() int { return len(r.prs)/2 + 1 }
Leadership transfer
有可能需要移除的节点是 leader,按照 raft thesis 的做法会比较奇怪,leader 需要管理不包含自己的集群,直到提交之后再 step down,可以通过 leadership transfer 将 leadership 转移到其他节点,
然后再移除原先的 leader。leadership transfer 还有其他的用途,比如 leader 所在机器的负载比较高,要转移到低负载机器上;leader 要改变机房实现就近等,同时还能降低选举的影响。
leadership transfer 的流程如下:
leader停止接收新的请求;- 通过
log replication使leader和transferee的log相同,确保transferee能够赢得选举; leader发送TimeoutNow给transferee,transferee会立即发起选举。leader收到transferee的消息会step down。
仍有几个问题需要处理:
transferee挂了: 当leadership transfer在election timeout时间内未完成,则终止并恢复接收客户端请求。transferee有大概率成为下一个leader,若失败,可以重新发起leader transfer。check quorum会使节点忽略RequestVote,需要强制投票。
etcd/raft 实现
调用 Node.TransferLeadership() 发起 leadership transfer:
func (n *node) TransferLeadership(ctx context.Context, lead, transferee uint64) {
select {
// manually set 'from' and 'to', so that leader can voluntarily transfers its leadership
case n.recvc <- pb.Message{Type: pb.MsgTransferLeader, From: transferee, To: lead}:
case <-n.done:
case <-ctx.Done():
}
}
leader 接收到之后会做一些检查,如果有正在进行的 leadership transfer,则终止之前的;检查 transferee 的 ID 等。主要看一下正常的逻辑:
- 设置
r.electionElapsed = 0,用于检测leadership transfer超时; - 设置
r.leadTransferee = leadTransferee,表示正在进行leadership transfer; - 若
transferee的log已经最新,则立刻发送TimeoutNow,否则等到log匹配时,再发送:case pb.MsgTransferLeader: // ... // Transfer leadership should be finished in one electionTimeout, so reset r.electionElapsed. r.electionElapsed = 0 r.leadTransferee = leadTransferee if pr.Match == r.raftLog.lastIndex() { r.sendTimeoutNow(leadTransferee) r.logger.Infof("%x sends MsgTimeoutNow to %x immediately as %x already has up-to-date log", r.id, leadTransferee, leadTransferee) } else { r.sendAppend(leadTransferee) }
leader 不会接收新的客户端请求:
case pb.MsgProp:
// ...
if r.leadTransferee != None {
r.logger.Debugf("%x [term %d] transfer leadership to %x is in progress; dropping proposal", r.id, r.Term, r.leadTransferee)
return ErrProposalDropped
}
当 transferee 的 log 追上时,发送 TimeoutNow:
// Transfer leadership is in progress.
if m.From == r.leadTransferee && pr.Match == r.raftLog.lastIndex() {
r.logger.Infof("%x sent MsgTimeoutNow to %x after received MsgAppResp", r.id, m.From)
r.sendTimeoutNow(m.From)
当 transferee 收到 TimeoutNow,调用 raft.campaign(campaignTransfer),会跳过 Pre-Vote 阶段,和正常投票只有一点不同,会设置 Message.Context 用于跳过 check quorum:
var ctx []byte
if t == campaignTransfer {
ctx = []byte(t)
}
r.send(pb.Message{Term: term, To: id, Type: voteMsg, Index: r.raftLog.lastIndex(), LogTerm: r.raftLog.lastTerm(), Context: ctx})
在其他节点收到携带 Context 的 RequestVote 消息时,会强制投票:
force := bytes.Equal(m.Context, []byte(campaignTransfer))
leader 在 tickHeartbeat() 中检测 leadership transfer 超时,设置 raft.leadTransferee = None 终止:
// tickHeartbeat is run by leaders to send a MsgBeat after r.heartbeatTimeout.
func (r *raft) tickHeartbeat() {
r.heartbeatElapsed++
r.electionElapsed++
if r.electionElapsed >= r.electionTimeout {
r.electionElapsed = 0
// If current leader cannot transfer leadership in electionTimeout, it becomes leader again.
if r.state == StateLeader && r.leadTransferee != None {
r.abortLeaderTransfer()
}
}
// ...
}
Joint consensus
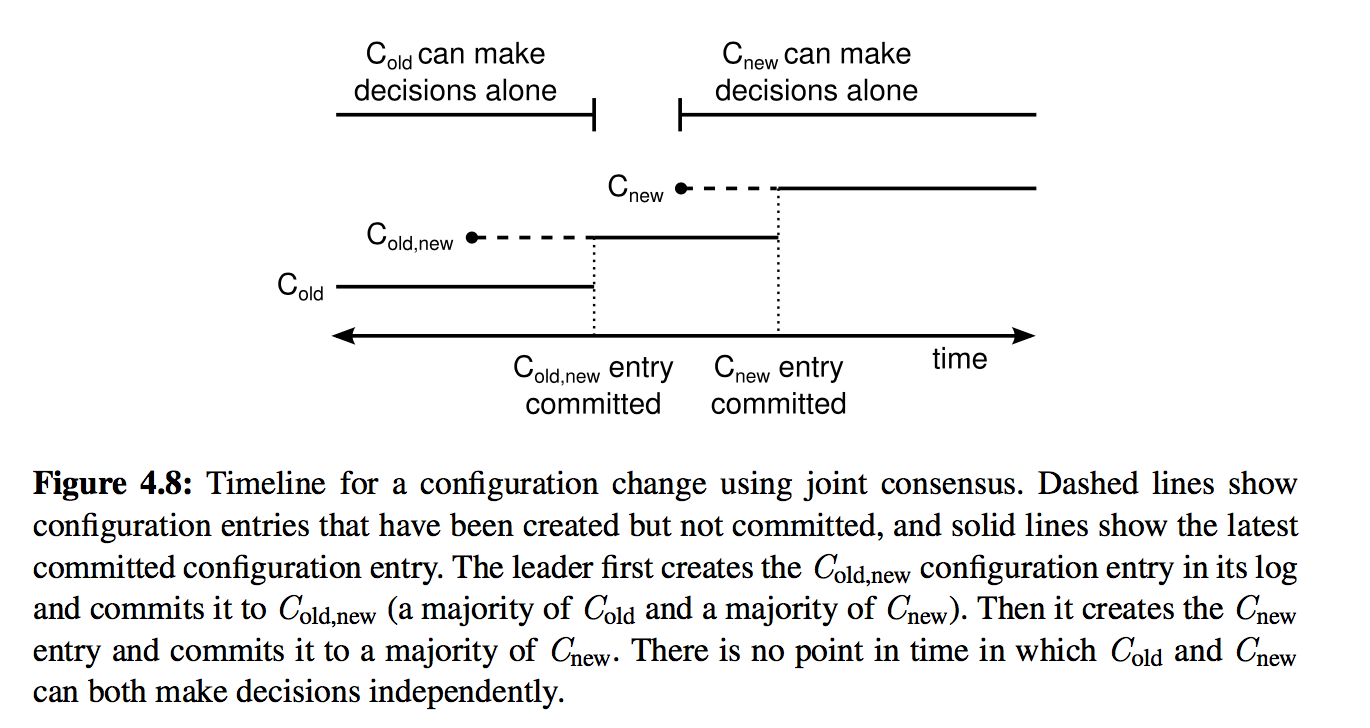
最开始 Raft 使用 joint consensus 实现成员变更,raft extended 中也只提到了这种方式,这种方式支持一次变更多个成员,但是复杂一些。
C-old 为当前的配置,C-new 为目标配置。当 leader 收到成员变更的请求时,会创建一个 C-old-new 的配置(joint consensus),所有节点在接收到配置时就采用新的配置,不用等到 commit。
joint consensus 把新旧配置联系起来:
log entries复制到2个配置的所有节点上;- 使用
C-old或C-old-new配置的节点都可能成为leader; - 处于
C-old-new状态时,必须收到C-old的majority和C-new的majority的同意才能提交或选出leader。
当 C-old-new 被提交之后,创建 C-new 配置,当 C-new 被提交后,整个成员变更结束,不在 C-new 中的节点可以关闭。joint consensus 确保了 C-old 和 C-new 不会同时做决定,保证了 safety。
留下评论