Raft 笔记(七) – Client interaction
线性一致性
Raft 的目标是实现线性一致性(Linearizability):
Each operation appears to take effect atomically at some point between its invocation and completion.
操作不是瞬间完成的,从客户端角度看有2个边界:
invocation: 操作发起的时间;completion: 操作完成的时间。
操作会在 invocation 和 completion 之间某点完成,但操作对其他操作生效的时机对于不同一致性是不同的。线性一致性要求当一个操作 complete,在这之后 invoke 的操作要么看到该操作的结果,
要么看到更新的状态。对于读操作而言:
- 读的结果,必须反映
invoke之前所有已经completion的结果,或者返回更新的结果;换句话说,会返回在invocation和completion之间的某种状态。 - 不会出现
non-monotonic read,之后的读操作要么返回之前返回的值,要么返回更新的值。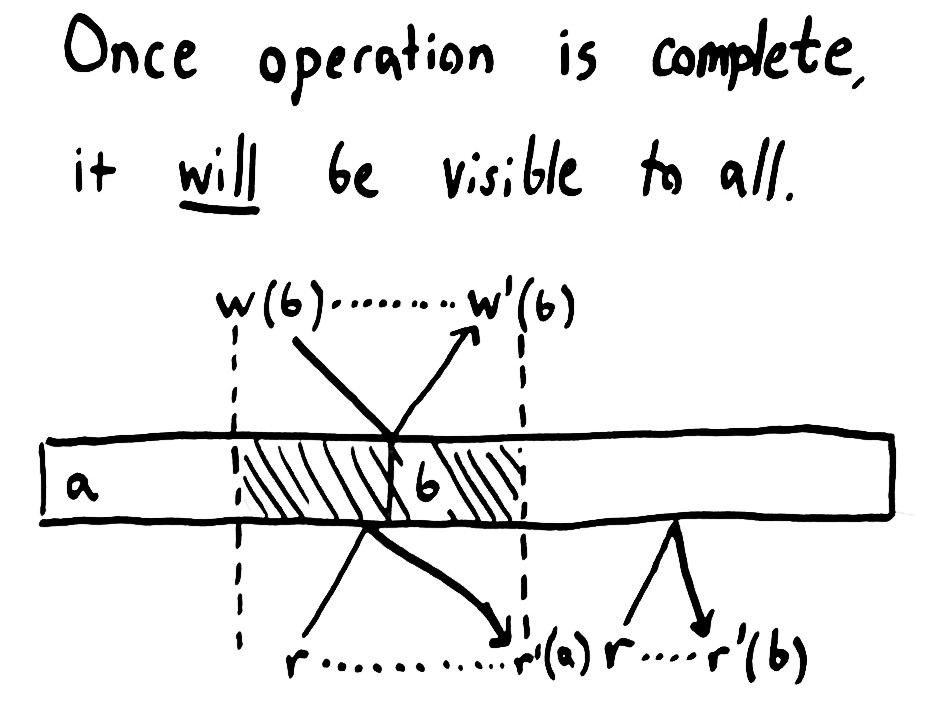
raft-thesis 中是这么描述读的:
Linearizability requires the results of a read to reflect a state of the system sometime after the read was initiated; each read must at least return the results of the latest committed write
更详细的解释请看 Strong consistency models。
客户端请求
请求大部分由 leader 处理,客户端会随机选一个节点发送请求,若该节点不是 leader 则有2种处理方式:
- 返回
leader的地址,客户端重新发起请求; - 节点作为
proxy,将请求发送给leader。
若请求超时或失败,再随机选择一个节点发送请求。
etcd/raft 实现了 proxy 的方式,可以通过设置 Config.DisableProposalForwarding 禁止:
func stepFollower(r *raft, m pb.Message) error {
switch m.Type {
case pb.MsgProp:
if r.lead == None {
r.logger.Infof("%x no leader at term %d; dropping proposal", r.id, r.Term)
return ErrProposalDropped
} else if r.disableProposalForwarding {
r.logger.Infof("%x not forwarding to leader %x at term %d; dropping proposal", r.id, r.lead, r.Term)
return ErrProposalDropped
}
m.To = r.lead
r.send(m)
// ...
}
写
写操作只会由 leader 处理,通过 log replication 能够保证线性一致性,并提供了 at-least-once 语义,但是客户端有可能会发起多次请求,比如客户端在接收到上次请求的相应之前崩溃、客户端请求超时然后重试等,服务端需要做去重处理。
Raft 作者把这部分也归为 linearizable semantics 的一部分,raft-thesis 中提供了解决办法:
- 每个客户端设置
unique identifier,并给它的每个不同的proposal设置连续的序列号,通过client id和序列号唯一确定一个proposal,相同的proposal使用相同序列号。 raft节点为每个客户端保持session,记录了客户端之前的请求的结果,当收到了重复的请求,不重复执行,直接返回结果。session不可能无限期保存和无限增长,需要清理和超时机制:- 清理:客户端请求携带着最小的未收到响应的序列号,
raft节点清理所有之前的结果。 - 超时:
raft节点只维护一定数量的客户端session,可以使用LRU淘汰客户端session。
- 清理:客户端请求携带着最小的未收到响应的序列号,
- 当接收到客户端
session已被淘汰了的客户端请求,如果创建一个新的session可能会导致重复应用。Raft作者认为这是异常情况,可以直接返回错误,让客户端fail。 - 客户端
session必须在各节点保持一致,同样需要能够从错误中恢复,否则会导致各节点state machine不同,或者重启时有重复应用的风险。换句话说,这些信息同样是state machine的一部分。
读
为了保证读操作的线性一致性,最简单的办法是读请求也走一遍完整的 log replication 流程,这种方式性能太低。读操作不会改变状态机状态,可以避开 log replication 过程,同时要有一种机制保证线性一致性,
对于 Raft 而言,要保证读的线性一致性需要保证下面2方面:
- 保证处理读请求的
leader一定是当前leader。如果发生了脑裂,有新的leader提交了log,会导致stale read。 - 在上面的前提下,保证读的结果能反映读请求
invoke时的状态,或更新的状态。
ReadIndex
raft-thesis 中提出了 ReadIndex 的方案,可以避开 log replication,处理读请求的流程如下:
leader必须在当前term提交过log entry才能处理读请求。因为leader是按照log的新旧选举而不是committed index,所以新leader的committed index可能落后,通过在新term提交log entry来更新到最新,同时也能提交之前term未提交的log。Raft通过给新leader追加一个当前term的no-op entry来解决这个问题。- 保存当前的
commited index为readIndex。readIndex即是能够保证线性一致性的最小的commited index。 leader需要确认自己仍是有效的leader,通过给其他节点发送新一轮heartbeat并收到majority的成功响应来保证。leader等待状态机执行committed log,直到applied index >= readIndex。leader将结果返回给客户端。
这种方式能够保证处理读请求的 leader 仍是有效的(3),同时读的结果能够反映 invoke 时的状态或更新的状态(1, 2, 4),保证了读的线性一致性。
etcd/raft 实现
当接收到读请求时,调用 Node.ReadIndex(),rctx 标记了一个读请求,相当于 request id,要保证全局唯一:
func (n *node) ReadIndex(ctx context.Context, rctx []byte) error {
return n.step(ctx, pb.Message{Type: pb.MsgReadIndex, Entries: []pb.Entry{{Data: rctx}}})
}
在 raft.StepLeader() 中处理 MsgReadIndex:
- 检查在当前
term是否commit过log entry:if r.raftLog.zeroTermOnErrCompacted(r.raftLog.term(r.raftLog.committed)) != r.Term { // Reject read only request when this leader has not committed any log entry at its term. return nil } - 保存
readIndex并给其他节点发送heartbeat,会设置ctx,用于区分正常heartbeat和ReadIndex的heartbeat(当还有未确认的ReadIndex时,正常的heartbeat也会携带最后一个ReadIndex的ctx):case ReadOnlySafe: r.readOnly.addRequest(r.raftLog.committed, m) r.bcastHeartbeatWithCtx(m.Entries[0].Data)
etcd/raft 使用如下结构保存 ReadIndex 状态:
readOnly:保存节点所有的ReadIndex请求,string是传入的rctx。type readOnly struct { option ReadOnlyOption pendingReadIndex map[string]*readIndexStatus // 保存每个读请求的状态 readIndexQueue []string // 保存未完成的 ReadIndex }readIndexStatus:保存单个读请求的readIndex和heartbeat状态。type readIndexStatus struct { req pb.Message index uint64 acks map[uint64]struct{} }
当 leader 接收到 MsgHeartbeatResp 时:
if r.readOnly.option != ReadOnlySafe || len(m.Context) == 0 { // 收到了 ReadIndex 的 heartbeat resp
return nil
}
ackCount := r.readOnly.recvAck(m) // 检查是否收到了 majority 的 resp
if ackCount < r.quorum() {
return nil
}
rss := r.readOnly.advance(m)
for _, rs := range rss {
req := rs.req
if req.From == None || req.From == r.id { // from local member
r.readStates = append(r.readStates, ReadState{Index: rs.index, RequestCtx: req.Entries[0].Data})
} else {
r.send(pb.Message{To: req.From, Type: pb.MsgReadIndexResp, Index: rs.index, Entries: req.Entries}) // follower 发送的 ReadIndex
}
r.readOnly.advance(m) 会返回 m 对应的 ReadIndex 之前的所有的 ReadIndex,即还未收到 majority resp 的。因为 readOnly.readIndexQueue 按顺序保存 ReadIndex,且
r.readOnly 会在 r.reset() 中重置,能够保证之前的 ReadIndex 仍是在 leader 状态下处理的。
在 Ready 中返回给用户 ReadState,index 为 readIndex,RequestCtx 为 rctx。当状态机执行到 applied index >= index 时,返回结果给对应客户端。
// ReadState provides state for read only query.
// It's caller's responsibility to call ReadIndex first before getting
// this state from ready, it's also caller's duty to differentiate if this
// state is what it requests through RequestCtx, eg. given a unique id as
// RequestCtx
type ReadState struct {
Index uint64
RequestCtx []byte
}
同样可以通过 follower 处理读请求,1-3 步仍要由 leader 处理,然后 leader 发送 MsgReadIndexResp 告诉 follower 对应的 readIndex,由 follower 执行 4-5 步,可以分摊部分 leader 的压力:
func stepFollower(r *raft, m pb.Message) error {
// ...
case pb.MsgReadIndex:
if r.lead == None {
r.logger.Infof("%x no leader at term %d; dropping index reading msg", r.id, r.Term)
return nil
}
m.To = r.lead
// 根据 leader 的 read option
r.send(m)
case pb.MsgReadIndexResp:
if len(m.Entries) != 1 {
r.logger.Errorf("%x invalid format of MsgReadIndexResp from %x, entries count: %d", r.id, m.From, len(m.Entries))
return nil
}
r.readStates = append(r.readStates, ReadState{Index: m.Index, RequestCtx: m.Entries[0].Data})
}
}
优化
现在每次读请求都需要发送 heartbeat,可以通过 batch 优化:多个读请求只发送一次 heartbeat。raft-thesis 中这样写道:
To improve efficiency further, the leader can amortize the cost of confirming its leadership: it can use a single round of heartbeats for any number of read-only queries that it has accumulated.
线性一致性不要求读的结果就是 invoke 时的状态,更新的状态也可以,所以可以等待多个 ReadIndex 请求再处理。若是读请求都发送给 follower,然后 batch 起来,leader 只需要发送少量 heartbeat 即可由
follower 处理大量读请求,既提高了读的性能,也分摊了 leader 的压力,提高了写的性能。
etcd/raft 没有实现 batch,不过下面的注释也提到了 batch 优化:
// thinking: use an interally defined context instead of the user given context.
// We can express this in terms of the term and index instead of a user-supplied value.
// This would allow multiple reads to piggyback on the same message.
Lease read
使用 ReadIndex 避免了 log replication,但是仍需要发送 heartbeat 来确保 leadership 的有效性。Lease read 通过 lease 机制可以避免 heartbeat 的开销,直接返回结果,但这种方式依赖时钟,不能保证线性一致性。
raft-thesis 中做法如下:
leader通过heartbeat来保持lease: 记录下发送heartbeat的时间start,当收到majority的响应后,就认为lease的有效期延续到start + election timeout / clock drift bound, 在这个时间范围内不会产生新的leader。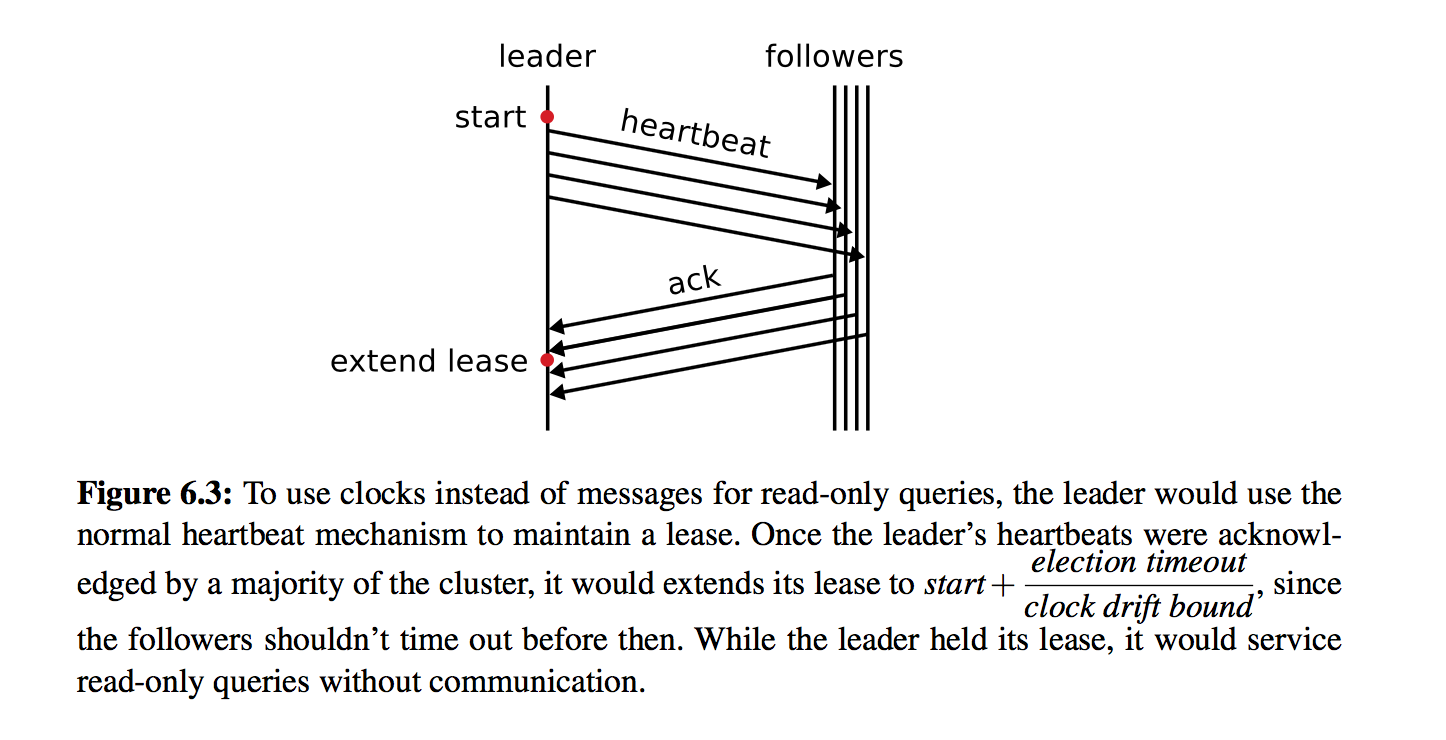
- 在
lease期限的读请求不用和其他节点通信,直接认为当前leadership是有效的,只是绕过了heartbeat来确认leadetship有效性,其余的处理和ReadIndex相同。 - 要注意
leadership transfer会导致新leader更早的产生,需要终止lease。
这种机制只能保证收到了 heartbeat 的节点不会发起选举,但是未收到的节点仍有可能超时成为新的 leader。为了防止这些节点成为新的 leader 要同时开启 check quorum 才行,raft-thesis 中没提到这点。
etcd/raft 实现
流程和 ReadIndex 类似,只是少了 heartbeat 的过程:
- 直接返回
ReadState:switch r.readOnly.option { case ReadOnlySafe: // 保存当前 committed r.readOnly.addRequest(r.raftLog.committed, m) r.bcastHeartbeatWithCtx(m.Entries[0].Data) case ReadOnlyLeaseBased: ri := r.raftLog.committed if m.From == None || m.From == r.id { // from local member r.readStates = append(r.readStates, ReadState{Index: r.raftLog.committed, RequestCtx: m.Entries[0].Data}) } else { r.send(pb.Message{To: m.From, Type: pb.MsgReadIndexResp, Index: ri, Entries: m.Entries}) } lease通过之前提到的 check quorum 实现,没有用heartbeat来更新lease,只要接收到节点resp就认为节点是活跃的, 每election timeout检查一次lease,并维持lease到下一个election timeout。- 不过
leadership transfer并没有终止lease。
留下评论