Raft 笔记(四) – Leader election
raft 结构体
raft 结构体中和 leader election 相关的状态主要如下:
id: 当前节点的id;Term: 当前term;Vote: 投票给哪个节点;raftLog: 用于获取log最后一个entry的信息;state: 当前节点的状态:leader、follower、candidate等;
Leader election
Election timeout
在集群刚启动时,所有节点的状态都为 follower,等待超时触发 leader election。超时时间由 Config 设置。etcd/raft 没有用真实时间而是使用逻辑时钟,当调用 tick 的次数超过指定次数时触发超时事件。
对于 follower 和 candidate 而言,tick 中会判断是否超时,若超时则会本地生成一个 MsgHup 类型的消息触发 leader election:
// tickElection is run by followers and candidates after r.electionTimeout.
func (r *raft) tickElection() {
r.electionElapsed++
if r.promotable() && r.pastElectionTimeout() {
r.electionElapsed = 0
r.Step(pb.Message{From: r.id, Type: pb.MsgHup})
}
}
消息处理
step 方法是消息处理的入口,不同 state 处理的消息不同且处理方式不同,所以有多个 step 方法:
raft.Step(): 消息处理的入口,做一些共性的检查,如term,或处理所有状态都需要处理的消息。若需要更进一步处理,会根据状态 调用下面的方法:raft.stepLeader():leader状态的消息处理方法;raft.stepFollower():follower状态的消息处理方法;raft.stepCandidate():candidate状态的消息处理方法。
MsgHup 是本地消息(term 为0),用于触发 leader election,非 leader 状态的节点会调用 raft.campaign():
- 成为
candidate,增加term,给自己投票,重置状态:func (r *raft) becomeCandidate() { // TODO(xiangli) remove the panic when the raft implementation is stable if r.state == StateLeader { panic("invalid transition [leader -> candidate]") } r.step = stepCandidate r.reset(r.Term + 1) // 增加 term、重置超时时间、设置 lead 为空、重置每个节点状态等 r.tick = r.tickElection r.Vote = r.id r.state = StateCandidate r.logger.Infof("%x became candidate at term %d", r.id, r.Term) } - 调用
raft.poll()给自己投票,若是单节点的集群,则立刻成为leader; - 给集群内其他节点发送
MsgVote消息,这里只是把需要发送的消息追加到 slice,之后通过Ready交给用户处理:r.send(pb.Message{Term: term, To: id, Type: voteMsg, Index: r.raftLog.lastIndex(), LogTerm: r.raftLog.lastTerm(), Context: ctx})
当收到其他节点发起的投票消息时,处理过程如下:
- 成为
follower,并重置electionElapsed: 消息中包含了发起投票节点的term,一般会比当前节点大; - 判断是否能够投票:
// We can vote if this is a repeat of a vote we've already cast... canVote := r.Vote == m.From || // ...we haven't voted and we don't think there's a leader yet in this term... (r.Vote == None && r.lead == None) || // ...or this is a PreVote for a future term... (m.Type == pb.MsgPreVote && m.Term > r.Term) - 根据
msg.Index和msg.LogTerm比较log新旧:func (l *raftLog) isUpToDate(lasti, term uint64) bool { return term > l.lastTerm() || (term == l.lastTerm() && lasti >= l.lastIndex()) } - 返回响应:
- 同意。成功投票会重置自己的
electionElapsed,避免自己触发选举,提高选举效率:r.send(pb.Message{To: m.From, Term: m.Term, Type: voteRespMsgType(m.Type)}) if m.Type == pb.MsgVote { // Only record real votes. r.electionElapsed = 0 // 成功投票重置选举超时时间 r.Vote = m.From // 当前 term 只会给一个节点投票 } - 拒绝:
r.send(pb.Message{To: m.From, Term: r.Term, Type: voteRespMsgType(m.Type), Reject: true})
- 同意。成功投票会重置自己的
当 candidate 收到投票响应后,会统计收到的票数,收到 majority 的投票后会变为 leader,并立即发送空的 msgApp 给其他节点:
case myVoteRespType:
// poll() 的实现很简单,使用 map 记录每个节点的投票信息,然后返回 granted 的个数
gr := r.poll(m.From, m.Type, !m.Reject)
r.logger.Infof("%x [quorum:%d] has received %d %s votes and %d vote rejections", r.id, r.quorum(), gr, m.Type, len(r.votes)-gr)
switch r.quorum() {
case gr: // 收到 quorum 的投票
if r.state == StatePreCandidate {
r.campaign(campaignElection)
} else {
r.becomeLeader()
r.bcastAppend()
}
case len(r.votes) - gr: // 收到 quorum 的拒绝
// pb.MsgPreVoteResp contains future term of pre-candidate
// m.Term > r.Term; reuse r.Term
r.becomeFollower(r.Term, None)
}
heartbeat
收到 majority 的投票后成为 leader,tick 变为 tickHeartbeat。触发 heartbeat 的逻辑和触发 election 相同。
超时后会处理一个本地消息 MsgBeat,然后给其他节点发送 MsgHeartbeat。
其他节点收到 heartbeat 后会重置超时时间(follower)或成为 follower(同时选举的 candidate),然后返回给 leader 响应。
一些细节
etcd/raft会忽略几乎所有term比自己小的消息;- 改变状态的时候会重置超时时间,并随机设置
election timeout:func (r *raft) resetRandomizedElectionTimeout() { r.randomizedElectionTimeout = r.electionTimeout + globalRand.Intn(r.electionTimeout) } - 每个节点在每个
term只会给一个节点投票,只有在term发生变化的时候清零; leader发送heartbeat时,其余节点只会check消息的term,而不会比较log,这是因为每个term只会有一个有效leader;- 当选举成功后,新
leader会立即发送一个空的MsgApp给其他节点,这是为了及时更新committed index,保证linearizablity(在与客户端交互的时候再详细介绍); - 当
leader收到heartbeat响应后会立即发送滞后的log entries给对端,此时可以认为对端是就绪的:if pr.Match < r.raftLog.lastIndex() { r.sendAppend(m.From) }
优化
只实现基本的 leader election 会有几个问题:
- 可能会同时存在多个
leader:当leader被partition在minority,majority部分会选举出新的leader,旧leader接收不到新leader的消息会认为自己依然是leader; - 一个坏的节点会
disrupt正常工作的集群:partitioned节点超时自增term,网络恢复后重连,导致集群进行不必要的leader election。
Check quorum
在网络分区的情况下,只有 majority 部分的 leader 能正常工作,基于此,实现 check quorum:
- leader 每隔 election timeout 检查其他节点的活跃情况,若少于 majority 活跃,则自动 step down 为 follower。
etcd/raft 的配置支持开启 check quorum:
leader每隔election timeout就进行一次check quorum;- 通过通信来判断节点活跃情况,在每次
check quorum时清理,只要在下次check quorum之前有通信就是活跃的。
// tickHeartbeat is run by leaders to send a MsgBeat after r.heartbeatTimeout.
func (r *raft) tickHeartbeat() {
r.heartbeatElapsed++
r.electionElapsed++
if r.electionElapsed >= r.electionTimeout {
r.electionElapsed = 0
if r.checkQuorum {
r.Step(pb.Message{From: r.id, Type: pb.MsgCheckQuorum}) // check quorum
}
// ...
}
func stepLeader(r *raft, m pb.Message) error {
// These message types do not require any progress for m.From.
switch m.Type {
// ...
case pb.MsgCheckQuorum:
if !r.checkQuorumActive() {
r.logger.Warningf("%x stepped down to follower since quorum is not active", r.id)
r.becomeFollower(r.Term, None) // leader steps down
}
return nil
// ...
}
// checkQuorumActive returns true if the quorum is active from
// the view of the local raft state machine. Otherwise, it returns
// false.
// checkQuorumActive also resets all RecentActive to false.
func (r *raft) checkQuorumActive() bool {
var act int
r.forEachProgress(func(id uint64, pr *Progress) {
if id == r.id { // self is always active
act++
return
}
if pr.RecentActive && !pr.IsLearner {
act++
}
pr.RecentActive = false // 清理活跃状态
})
return act >= r.quorum() // 小于 majority 时 step down
}
check quorum 不能阻止多 leader 的产生,但能够减少同时存在的时间,不会影响集群的正常使用和一致性:
- 新写入旧
leader的命令不会commit; - 若绕过
log replication来读旧leader会有相应的措施保证线性一致性(后面再看); election timeout之后,leader变为follower,之前连到该节点的客户端就会连到新的leader上进行正常的请求。
Pre-Vote
partitioned 节点 disrupt 集群的原因是 term 比其他节点要大,为了减少这种情况,需要有种措施避免 term 的无谓增大。
partitioned 节点的 log 一般会落后于其他节点,不会收到 majority 的投票,基于此,增加了 Pre-Vote 阶段:
- 只有收到
majority的投票,才会增加term进行正常的选举过程; - 若 Pre-Vote 失败,当网络恢复后,该节点收到
leader的消息重新成为follower,避免了disrupt集群。
etcd/raft 的配置支持开启 Pre-Vote:
- 在进行正常选举之前,进行
Pre-Vote:func (r *raft) Step(m pb.Message) error { // ... switch m.Type { case pb.MsgHup: if r.preVote { r.campaign(campaignPreElection) } else { r.campaign(campaignElection) } // ... } follower首先变为preCandidate,不会增加自己的term:func (r *raft) becomePreCandidate() { // TODO(xiangli) remove the panic when the raft implementation is stable if r.state == StateLeader { panic("invalid transition [leader -> pre-candidate]") } // Becoming a pre-candidate changes our step functions and state, // but doesn't change anything else. In particular it does not increase // r.Term or change r.Vote. r.step = stepCandidate r.votes = make(map[uint64]bool) r.tick = r.tickElection r.state = StatePreCandidate r.logger.Infof("%x became pre-candidate at term %d", r.id, r.Term) }Pre-Vote和正常投票流程相同,但是其他节点收到Pre-Vote消息时不会改变自己的状态,且可以给多个Pre-Vote的candidate投票:func (r *raft) Step(m pb.Message) error { // Handle the message term, which may result in our stepping down to a follower. switch { case m.Term == 0: // local message case m.Term > r.Term: // ... switch { case m.Type == pb.MsgPreVote: // Never change our term in response to a PreVote case m.Type == pb.MsgPreVoteResp && !m.Reject: // We send pre-vote requests with a term in our future. If the // pre-vote is granted, we will increment our term when we get a // quorum. If it is not, the term comes from the node that // rejected our vote so we should become a follower at the new // term. default: r.logger.Infof("%x [term: %d] received a %s message with higher term from %x [term: %d]", r.id, r.Term, m.Type, m.From, m.Term) if m.Type == pb.MsgApp || m.Type == pb.MsgHeartbeat || m.Type == pb.MsgSnap { r.becomeFollower(m.Term, m.From) } else { r.becomeFollower(m.Term, None) } }- 当
preCandidate收到majority的投票后,进入正常的投票流程。
一些注意点:
- 成为
PreCandidate不会设置r.lead = None; Pre-Vote不会增加term,但发送的MsgPreVote的term为竞选的term;- 当给
Pre-Vote投票时,发送的MsgPreVoteResp的term是接收到的MsgPreVote的term而不是本地的term,因为本地term一般会比 竞选的term小,节点会忽略落后的消息; - 单个节点可以给多个
Pre-Vote节点的投票; Pre-Vote失败回退为follower,term不变;Pre-Vote成功不能保证该节点会成为leader,有可能在Pre-Vote成功后集群其他节点写入了新的entry或者发生split vote,此时会回退为follower, 重新进行Pre-Vote。
Leader lease
Pre-Vote 只解决了 log 落后的节点不会自增 term 导致集群 disrupt,但是仍有可能节点 log 没有落后但仍发起 Pre-Vote(这种场景真实存在,在后面 cluster membership change 中会遇到):
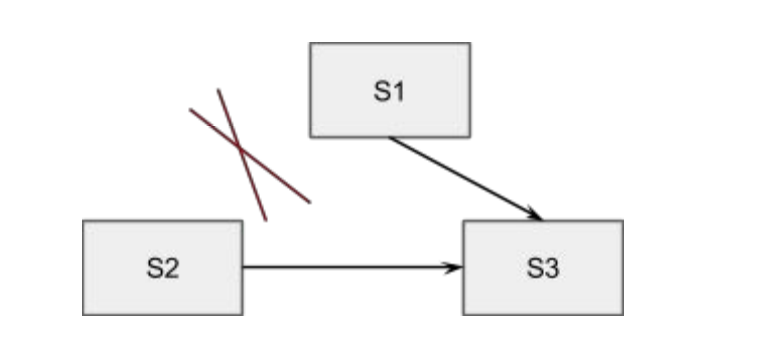
- 有
S1 S2 S3三个节点,S1为leader且三个节点log相同; - 发生网络分区,其中
S1 S3互通,S2 S3互通,S1 S2不通; S2发起Pre-Vote,收到S3投票后,进行正常election,成为新的leader。
解决这个问题的方法是 leader lease, 节点不应该在集群正常工作的情况下给其他节点投票:
- 当节点在 election timeout 时间内接收到了 leader 的消息,就不会改变自己的 term 也不会给其他节点投票。
leader lease 需要开启 check quorum:
check quorum是从leader角度判断自己是否合法;leader lease是从follower角度判断leader是否合法。
若只有 leader lease 而没有 check quorum,会有下面这种情况:
- 5 个节点的集群,
S1为leader,S2-S5为follower; - 发生了网络分区
S1 S2互通,S2-S4互通,S5不通; - 在没有
leader lease的情况下,S2-S4会选举出新的leader;但开启了leader lease,S2会忽略其他节点的投票消息,不会选举出新的leader; - 所以从
S2-S4看,S1 S5故障,无法保证在majority正常的情况下集群正常工作。
etcd/raft 中开启 check quorum 就开启了 leader lease:
inLease的情况下,节点忽略投票消息:func (r *raft) Step(m pb.Message) error { // Handle the message term, which may result in our stepping down to a follower. switch { case m.Term == 0: // local message case m.Term > r.Term: if m.Type == pb.MsgVote || m.Type == pb.MsgPreVote { force := bytes.Equal(m.Context, []byte(campaignTransfer)) inLease := r.checkQuorum && r.lead != None && r.electionElapsed < r.electionTimeout if !force && inLease { // If a server receives a RequestVote request within the minimum election timeout // of hearing from a current leader, it does not update its term or grant its vote r.logger.Infof("%x [logterm: %d, index: %d, vote: %x] ignored %s from %x [logterm: %d, index: %d] at term %d: lease is not expired (remaining ticks: %d)", r.id, r.raftLog.lastTerm(), r.raftLog.lastIndex(), r.Vote, m.Type, m.From, m.LogTerm, m.Index, r.Term, r.electionTimeout-r.electionElapsed) return nil } } // ... }
关系
check quorum 和 Pre-Vote 作用有些类似,但是互补,一般会同时开启来提高可用性:
check quorum保证了集群正常工作的情况下,不会受到坏节点的影响,但是只要有一个节点term升高,为了使这个节点正常工作,leader election不可避免;Pre-Vote在大多数情况下避免了节点term的升高。
问题
etcd/raft 的实现会忽略 term 低于自己的消息,在使用 check quorum 或 Pre-Vote 时会带来问题:
- 开启
check quorum时,partitioned节点在网络恢复后一直发送投票请求,但是其他节点inLease会忽略它的消息,同时这个节点忽略leader的消息,导致这个节点不能stable。 - 开启
Pre-Vote时,发起Pre-Vote的节点的term比其他节点高,但是log却落后,导致这个节点不能stable。这可能发生在Pre-Vote成功,然后正常vote时, 该节点被partition,同时集群正常工作写入新的log,在网络恢复后,这个节点发起的Pre-Vote不会成功,且会忽略leader的消息,不会stable。 - 还有种情况比较
tricky,发生在变更配置时,Pre-Vote从false变为true,若term高的节点log落后可能会造成集群死锁,不会选举出leader。 比如有 3 个节点,term越高的节点log越旧,导致没有一个节点能够Pre-Vote成功。(见 issue #8501和 pr #8525)。
所以 etcd/raft 会处理上面几种情况下 term 低的消息:
func (r *raft) Step(m pb.Message) error {
// ...
case m.Term < r.Term:
if (r.checkQuorum || r.preVote) && (m.Type == pb.MsgHeartbeat || m.Type == pb.MsgApp) {
// We have received messages from a leader at a lower term. It is possible
// that these messages were simply delayed in the network, but this could
// also mean that this node has advanced its term number during a network
// partition, and it is now unable to either win an election or to rejoin
// the majority on the old term. If checkQuorum is false, this will be
// handled by incrementing term numbers in response to MsgVote with a
// higher term, but if checkQuorum is true we may not advance the term on
// MsgVote and must generate other messages to advance the term. The net
// result of these two features is to minimize the disruption caused by
// nodes that have been removed from the cluster's configuration: a
// removed node will send MsgVotes (or MsgPreVotes) which will be ignored,
// but it will not receive MsgApp or MsgHeartbeat, so it will not create
// disruptive term increases, by notifying leader of this node's activeness.
// The above comments also true for Pre-Vote
//
// When follower gets isolated, it soon starts an election ending
// up with a higher term than leader, although it won't receive enough
// votes to win the election. When it regains connectivity, this response
// with "pb.MsgAppResp" of higher term would force leader to step down.
// However, this disruption is inevitable to free this stuck node with
// fresh election. This can be prevented with Pre-Vote phase.
r.send(pb.Message{To: m.From, Type: pb.MsgAppResp})
} else if m.Type == pb.MsgPreVote {
// Before Pre-Vote enable, there may have a receiving candidate with higher term,
// but less log. After update to Pre-Vote, the cluster may deadlock if
// we drop messages with a lower term.
r.logger.Infof("%x [logterm: %d, index: %d, vote: %x] rejected %s from %x [logterm: %d, index: %d] at term %d",
r.id, r.raftLog.lastTerm(), r.raftLog.lastIndex(), r.Vote, m.Type, m.From, m.LogTerm, m.Index, r.Term)
r.send(pb.Message{To: m.From, Term: r.Term, Type: pb.MsgPreVoteResp, Reject: true})
} else {
// ignore other cases
r.logger.Infof("%x [term: %d] ignored a %s message with lower term from %x [term: %d]",
r.id, r.Term, m.Type, m.From, m.Term)
}
return nil
}
// ...
}
留下评论