Redis源码阅读(四) – list
Redis实现了3种链表:adlist、ziplist和quicklist。
adlist
adlist是朴素的双向链表,结构如下,没什么好说的,代码也很简单:
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
typedef struct listIter {
listNode *next;
int direction;
} listIter;
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
ziplist
ziplist顾名思义,是一种压缩的双向链表,ziplist.c的注释将整体的结构介绍的很详细,同样是由表示链表整体信息的header
和每个元素信息的entry组成,不过ziplist所有信息保存在连续的内存中,每次修改都需要realloc或者memmove,所以效率比较低,是为了节省内存设计的。结构如下:
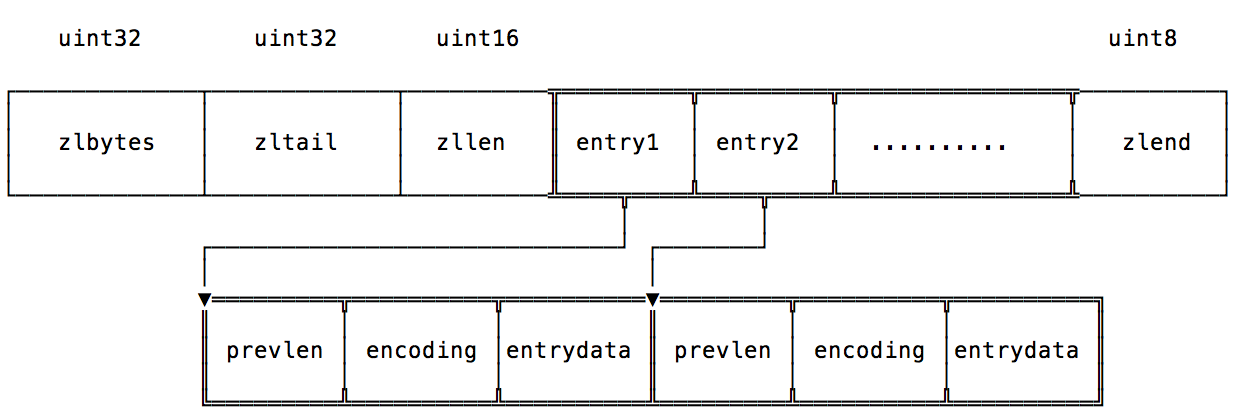
细节都在注释里,这里只整理一下,不过注释中有错误,需要注意下,在prevlen这一块,注释如下。
The length of the previous entry, <prevlen>, is encoded in the following way: If this length is smaller than 255 bytes, it will only consume a single byte representing the length as an unsinged 8 bit integer. When the length is greater than or equal to 255, it will consume 5 bytes. The first byte is set to 255 (FF) to indicate a larger value is following. The remaining 4 bytes take the length of the previous entry as value.
So practically an entry is encoded in the following way:
<prevlen from 0 to 254> <encoding> <entry>
Or alternatively if the previous entry length is greater than 254 bytes the following encoding is used:
0xFF <4 bytes unsigned little endian prevlen> <encoding> <entry>
注释中是说prevlen >= 255 bytes时,会用0xFF + 4 bytes记录,源码中实际是prevlen >= 254时,会用0xFE + 4 bytes记录,
因为0xFF是ZIP_END,无法区分是zlend还是prevlen。prevlen用5 bytes表示时,不代表长度一定大于等于254,这是为了减少realloc和
memmove提高效率。
entry如下:
| encoding | type | size | length |
|---|---|---|---|
| 00pppppp | string | 1 | <= 63 |
| 01pppppp qqqqqqqq | string | 2 | <= 16383 |
| 10000000 + 4 bytes | string | 5 | >= 16384 |
| 11000000 | int16_t | 3 | - |
| 11010000 | int32_t | 5 | - |
| 11100000 | 24 bit number | 4 | - |
| 11111110 | int8_t | 2 | - |
| 1111xxxx | 0 - 12 | 1 | - |
ziplist还会在特殊情况进行优化,比如使用zipTryEncoding()将字符串转换为integer。ziplist限定了endian,
一般只有在网络传输时才会限定endian,这里是因为ziplist有一些特殊大小的数据,如11100000 + 24 bit number,若使用big-endian会有问题。
quicklist
quicklist是由ziplist构成的双向链表,是为了既有ziplist节省内存的优点,又为了提高效率。主要结构如下:
/* quicklist is a 32 byte struct (on 64-bit systems) describing a quicklist.
* 'count' is the number of total entries.
* 'len' is the number of quicklist nodes.
* 'compress' is: -1 if compression disabled, otherwise it's the number
* of quicklistNodes to leave uncompressed at ends of quicklist.
* 'fill' is the user-requested (or default) fill factor. */
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned int len; /* number of quicklistNodes */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
* We use bit fields keep the quicklistNode at 32 bytes.
* count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually < 32k).
* encoding: 2 bits, RAW=1, LZF=2.
* container: 2 bits, NONE=1, ZIPLIST=2.
* recompress: 1 bit, bool, true if node is temporarry decompressed for usage.
* attempted_compress: 1 bit, boolean, used for verifying during testing.
* extra: 12 bits, free for future use; pads out the remainder of 32 bits */
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
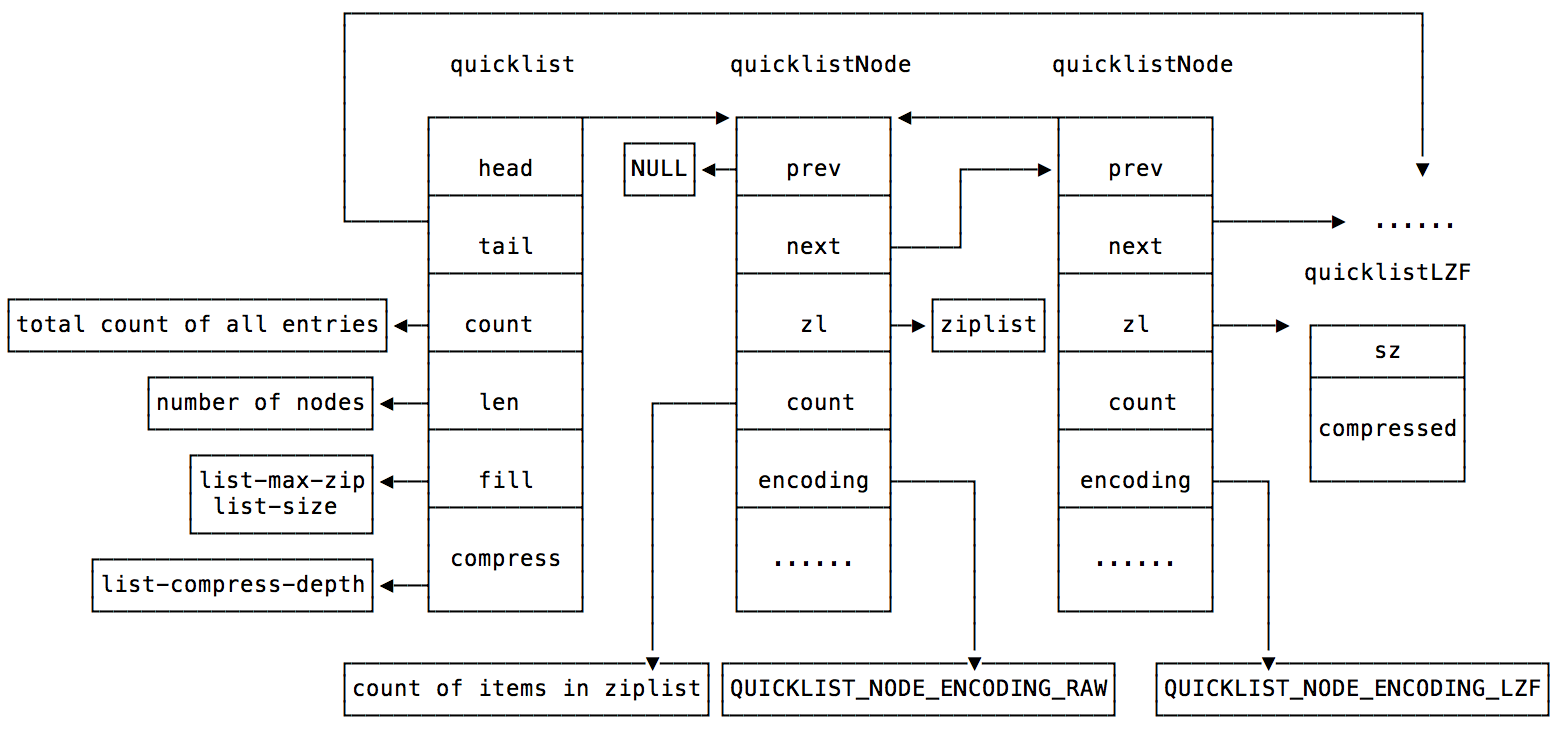
quicklist由多个ziplist组成,每个quicklistNode包含一个ziplist: zl。有两个配置影响了quicklist:
list-max-ziplist-size: 限制了每个quicklistNode中ziplist大小list-compress-depth: 头尾不被压缩的ziplist数目
quicklist使用多个ziplist是为了提高索引效率,只需要找到所在的quicklistNode再对其中的ziplist遍历即可,不需要从头开始遍历。
quicklist除了使用ziplist外,还会对中间的ziplist使用lzf算法压缩,进一步节省内存,list-compress-depth设置了头尾步不被压缩的ziplist数目,
为的是避免为push/pop操作带来overhead,每次使用都需要decompress、compress。
留下评论