Redis源码阅读(五) – dict
Redis使用dict作为数据库的实现,结构如下:
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size; // table size: 2^n
unsigned long sizemask; // size - 1: 2^n - 1 = 111....
unsigned long used; // total entries in table
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
dict的实现很朴素:
- 使用单向链表解决冲突,新加入的
entry添加在相应bucket头部 dictht.size为dictht.table大小,是2的幂,dictht.sizemask = dictht.sizemask - 1,避免了求余
rehash
当装载因子过大时,dict的效率会降低,需要rehash。传统rehash操作是分配一个更大的table,然后将旧table里每一个entry重新加入新table,
当dict键值对数量很多时,会带来很大的延迟。Redis的rehash方法比较特殊,是渐进式rehash。
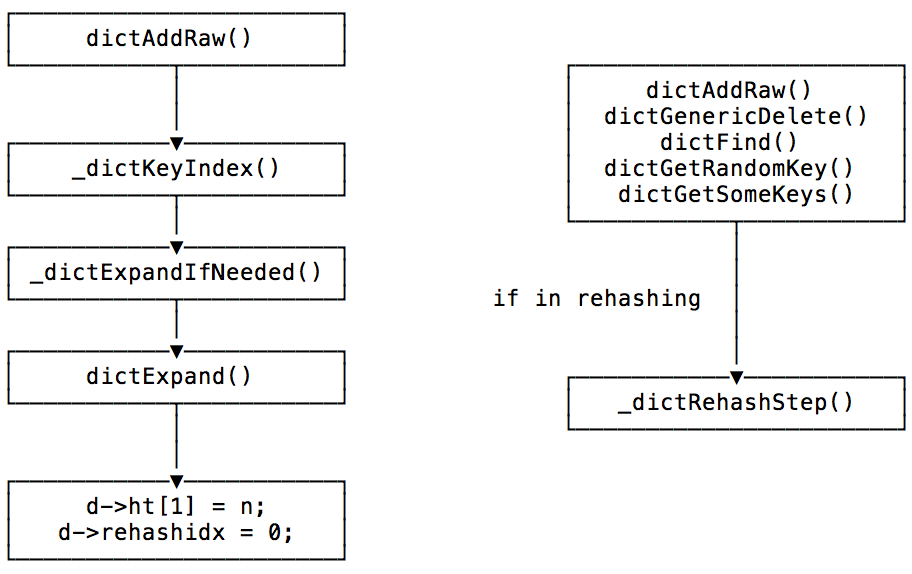
在每次add元素时,都会调用_dictExpandIfNeeded(),判断是否需要rehash。为了避免COW的内存复制,当有子进程时会提高限制条件:
/* Expand the hash table if needed */
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
dictExpand()初始化rehash,分配新table,设置rehashidx:
dict.ht[2]: 分配了2个table,一个个将ht[0]的bucket迁移到ht[1]。当rehash完成后,ht[0]指向ht[1],resetht[1]dict.rehashidx: 下一个需要迁移的bucket索引,-1为不rehash,ht[0]中索引小于rehashidx的元素一定为空。
/* Expand or create the hash table */
int dictExpand(dict *d, unsigned long size)
{
dictht n; /* the new hash table */
unsigned long realsize = _dictNextPower(size);
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
/* Rehashing to the same table size is not useful. */
if (realsize == d->ht[0].size) return DICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}
当需要rehash时,每次操作都会调用一次_dictRehashStep(),将一个bucket从ht[0]迁移到ht[1]:
/* Performs N steps of incremental rehashing. Returns 1 if there are still
* keys to move from the old to the new hash table, otherwise 0 is returned.
*
* Note that a rehashing step consists in moving a bucket (that may have more
* than one key as we use chaining) from the old to the new hash table, however
* since part of the hash table may be composed of empty spaces, it is not
* guaranteed that this function will rehash even a single bucket, since it
* will visit at max N*10 empty buckets in total, otherwise the amount of
* work it does would be unbound and the function may block for a long time. */
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
unsigned int h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}
当dict相关操作很少时,dict会一直处于rehash状态,导致内存浪费。
配置activerehashing yes会在serverCron() -> databasesCron() -> incrementallyRehash() -> dictRehashMilliseconds()中rehash1ms,至少迁移100个bucket。
rehash 过程中的操作
rehash过程中有2个table,查找操作会按顺序查找这2个table。插入有两种情况:
key存在时,会覆盖原有value,不会改变table。key不存在时,会插入到第二个table中。
scan
scan操作在管理redis中用的比较多。dictScan()操作比较复杂,因为dict在多次scan过程中,可能会发生rehash,需要考虑几种情况。代码如下:
unsigned long dictScan(dict *d,
unsigned long v,
dictScanFunction *fn,
dictScanBucketFunction* bucketfn,
void *privdata)
{
dictht *t0, *t1;
const dictEntry *de, *next;
unsigned long m0, m1;
if (dictSize(d) == 0) return 0;
if (!dictIsRehashing(d)) {
t0 = &(d->ht[0]);
m0 = t0->sizemask;
/* Emit entries at cursor */
if (bucketfn) bucketfn(privdata, &t0->table[v & m0]);
de = t0->table[v & m0];
while (de) {
next = de->next;
fn(privdata, de);
de = next;
}
} else {
t0 = &d->ht[0];
t1 = &d->ht[1];
/* Make sure t0 is the smaller and t1 is the bigger table */
if (t0->size > t1->size) {
t0 = &d->ht[1];
t1 = &d->ht[0];
}
m0 = t0->sizemask;
m1 = t1->sizemask;
/* Emit entries at cursor */
if (bucketfn) bucketfn(privdata, &t0->table[v & m0]);
de = t0->table[v & m0];
while (de) {
next = de->next;
fn(privdata, de);
de = next;
}
/* Iterate over indices in larger table that are the expansion
* of the index pointed to by the cursor in the smaller table */
do {
/* Emit entries at cursor */
if (bucketfn) bucketfn(privdata, &t1->table[v & m1]);
de = t1->table[v & m1];
while (de) {
next = de->next;
fn(privdata, de);
de = next;
}
/* Increment bits not covered by the smaller mask */
v = (((v | m0) + 1) & ~m0) | (v & m0);
/* Continue while bits covered by mask difference is non-zero */
} while (v & (m0 ^ m1));
}
/* Set unmasked bits so incrementing the reversed cursor
* operates on the masked bits of the smaller table */
v |= ~m0;
/* Increment the reverse cursor */
v = rev(v);
v++;
v = rev(v);
return v;
}
dictScan()是无状态的,使用cursor来记住状态,初始时传递cursor = 0,之后每次scan以上次返回的cursor作为参数传递,
完成时返回cursor = 0。cursor是扫描的bucket的索引,每次扫描结束,cursor最高位+1。dictScan()保证扫描到开始时的所有元素,但是有可能会多次扫描,
scan过程中未发生变化
未发生变化时,每次cursor最高位+1,最后所有的bucket都会扫描一遍,所有元素扫描一次。
rehashing
rehashing过程中会使用2个table,原来table中的一些bucket会被清空,迁移到新的table。下面是scan的流程:
t0指向小的table,t1指向大的- 扫描t0索引为
cursor & m0的bucket,扫描t1索引低位为cursor & m0的bucket
table的大小一定是2^n,即使发生了rehash,sizemask发生变化,bucket索引的低几位是不变的,这点很重要。上面第2步确保了每次扫描的bucket的原有
元素一定会被扫描到:
- grow: 当前
bucket若没被rehash,则元素都在t0中;若当前bucket已经rehash到t1中,则元素一定分布在低位相同的bucket中。 - shrink: 这种情况反过来,低位相同的
bucket一定会被rehash到t1的相同bucket中,从小表开始扫,能减少重复。
简单来说就是小表的每个bucket及其rehash相关的大表的bucket都会被扫描到,确保了每个元素都被扫描到。
rehash完成
和未发生变化类似,每次cursor最高位+1,之前扫描的cursor的bucket元素会rehash到其他bucket中,并且不会被重复扫描。
留下评论