Faster: A Concurrent Key-Value Store with In-Place Updates
FASTER 是微软实现的 k/v 存储引擎,提供 Read、Upsert、Rmw 和 Delete 接口,对 key/value 的类型没限制,支持 persistence 和 recovery。
在 2.60GHz Intel Xeon CPU E5-2690 v4 CPUs, 2 sockets and 14 cores (28 hyperthreads) per socket, 256GB RAM, 3.2TB FusionIO NVMe SSD drive 的单机上开启 56 线程压测可达每秒
1.6 亿次操作:纯读操作,纯内存,key/value 都是 8 bytes integer。
Faster 的代码也在 github 上开源了,不过只是个原型,论文里也有很多没解决的问题。
Architecture
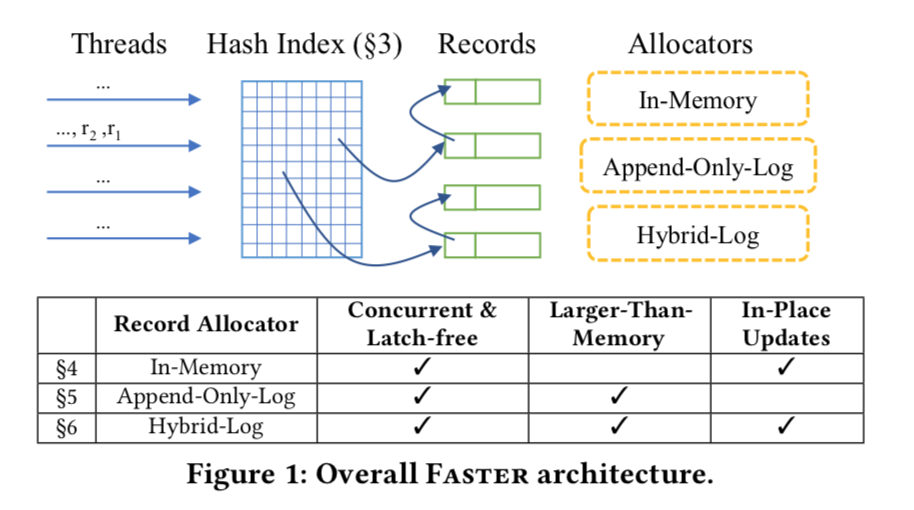
FASTER 整个架构分为 4 个部分:
code-generationepoch protection frameworklatch-free hash tablehybrid-log
使用
FASTER 的使用比较麻烦,内部的很多机制如 epoch protection framework、disk i/o 等都需要用户配合使用:
- 线程开始时调用
Acquire注册该线程。 - 线程调用一系列命令。
- 线程要定期调用
Refresh和CompletePending操作。 - 最后调用
Release解除线程的注册。
C++ 的实现如下,StartSession 为 Acquire,StopSession 为 Release:
// Register thread with FASTER
store.StartSession();
// Process the batch of input data
for(uint64_t idx = 0; idx < kNumOps; ++idx) {
RmwContext context{ AdId{ idx % kNumUniqueKeys}, 1 };
store.Rmw(context, callback, idx);
if(idx % kCheckpointInterval == 0) {
Guid token;
store.Checkpoint(nullptr, hybrid_log_persistence_callback, token);
printf("Calling Checkpoint(), token = %s\n", token.ToString().c_str());
}
if(idx % kCompletePendingInterval == 0) {
store.CompletePending(false);
} else if(idx % kRefreshInterval == 0) {
store.Refresh();
}
}
// Make sure operations are completed
store.CompletePending(true);
// Deregister thread from FASTER
store.StopSession();
Code-generation
FASTER 对 key/value 的类型没要求,而且支持 Rmw,所以需要用户提供相应的逻辑。FASTER 通过 code-generation 生成代码调用用户提供的接口。
在 C++ 中是用模板实现的,是为了避免虚函数的性能损耗。 以 Read 操作为例:
FASTER的Read接口如下,需要传入用户定义的类RC(Read Context):template <class RC> inline Status Read(RC& context, AsyncCallback callback, uint64_t monotonic_serial_num);RC需要实现几个implicit interface:/// The implicit and explicit interfaces require a key() accessor. inline const AdId& key() const { // 返回要查找的 key return key_; } inline void Get(const value_t& value) { // 将 key 对应的 value 保存在 result *result_ = value.num_clicks; } inline void GetAtomic(const value_t& value) { *result_ = value.atomic_num_clicks; }- 在
FASTER内部调用会调用RC的接口:inline const key_t& key() const final { return read_context().key(); } inline void Get(const void* rec) final { const record_t* record = reinterpret_cast<const record_t*>(rec); read_context().Get(record->value()); } inline void GetAtomic(const void* rec) final { const record_t* record = reinterpret_cast<const record_t*>(rec); read_context().GetAtomic(record->value()); }
Epoch Protection Framework
提高 scalability 的关键是避免线程间的同步,因为当核数越来越多时,同步的代价越来越大。FASTER 的绝大多数操作是不需要同步的,
当需要同步时使用 Epoch Protection Framework 实现线程间状态的 lazy coordination:
- 使用
atomic variable维护全局递增的Epoch,可以被任意线程读取、增加。 - 每个线程定期从全局的
Epoch中获取thread-local epoch。 - 当所有线程的
thread-local epoch都大于某个epoch时,该epoch是安全的。 - 增加全局
Epoch时可以注册<Epoch - 1, trigger action>,当Epoch - 1安全时,trigger action会被调用。
举个例子,多线程情况下如何安全的释放内存。最常用的方法是 refcount,当 refcount 为 0 时释放内存,但是 atomic variable 在核数多时,同步代价就很大,性能很差,而且 refcount 不是
通用的解决办法,还会增加内存使用。用 epoch 解决办法如下:
- 当需要释放内存时,一个线程增加全局的
Epoch并注册<Epoch - 1, free old memory>。 - 所有线程定期调用
Refresh增加自己的thread-local epoch。 - 当
Epoch - 1安全时,能够保证没有线程会访问之前的内存,可以安全释放。
对全局 Epoch 的修改是 write-release,读取是 read-acquire,所以修改 Epoch 之前的操作都会对之后读取 Epoch 的线程可见,从而实现了状态的同步。而且每个线程增加 thread-local epoch 都是
主动调用 Refresh,是在操作的边界,保证了 epoch safe 时没有线程在访问之前的状态,之后的操作都会访问最新的状态。
FASTER 的实现也很简单:
- 全局的原子变量
current_epoch。 - 数组保存所有线程的
thread-local epoch,不是原子变量,使用acquire/release语义遍历来计算safe epoch。 - 固定大小的数组保存
<epoch, trigger action>对,epoch使用原子变量,起到锁的作用,使用CAS实现插入并保证唯一执行。
Latch-free Hash Table
FASTER 的索引是 latch-free hash table,而且支持 resize。和一般的 hash table 实现相同,使用 hash(key) 找到 hash bucket,使用链表解决冲突。
hash table 天然并发友好,因为不同 bucket 间不需要同步。
FASTER 使用 cache-aligned 数组保存 hash buckets,每个 hash bucket 是 64 字节,包含 8 个 hash entry,使用 tag 区分 entry:
- 前
7个分别指向链表尾部的Record,Record header会保存上一个Record地址。 - 最后一个为
overflow bucket entry指向相同索引不同tag的hash bucket,用于解决hash entry的冲突。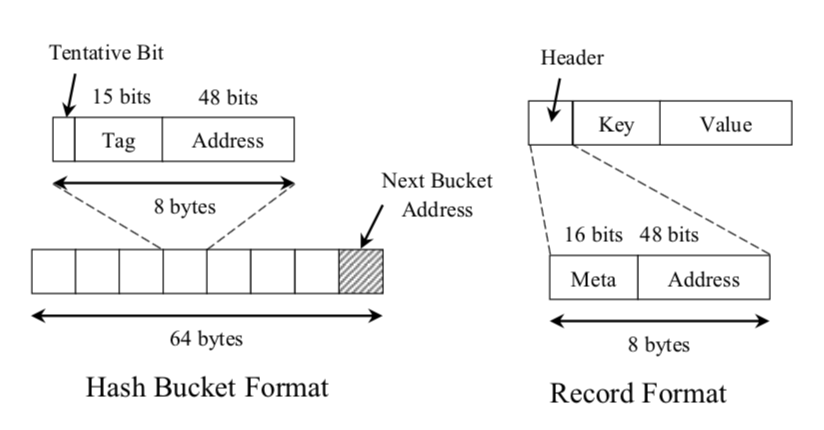
查找 key 的过程如下:
- 计算
key hash,key hash也和hash bucket entry的格式对应:struct KeyHash { union { struct { uint64_t address_ : 48; uint64_t tag_ : 14; uint64_t not_used_ : 2; }; uint64_t control_; }; }; address & (size - 1)找到对应的hash bucket。- 遍历
hash bucket比较tag找到对应的hash entry。 - 遍历
hash entry指向的链表,找到相同的key的Record。
hash bucket 内部还要划分 hash entry 的原因是:因为 hash bucket 间不需要同步,所以要按 cacheline 对齐来避免 false sharing,至少要 64 字节,
若每个 hash bucket 指向一个链表就太浪费内存,所以这里划分了 8 个 entry,还能减少 hash collision 提高性能。
hash entry 和 record header 中使用 48 bits 保存地址,而我们都知道 64 位机器的指针大小为 64 位,这是因为:
64位机器一般使用少于64 bits的物理地址,比如Intel使用48 bits。- 为了实现
latch-free,要使用原子操作设置hash entry,而64位机器最多提供64 bits的原子操作,但我们需要一些bits来实现一些逻辑,如entry的tentative bit。
插入的过程很简单,先找到对应的 entry:
- 若
entry存在,则CAS设置entry指向新的Record链表尾即可,失败的话就重试。 - 若
entry不存在,则找到空闲的entry设置。但这里不能直接CAS,因为有可能导致相同的tag使用多个entry:T1找到g5为空闲,准备设置。- 其他线程删除
key将g3清空。 T2插入相同hash的key,找到g3为空闲,导致使用了不同的entry。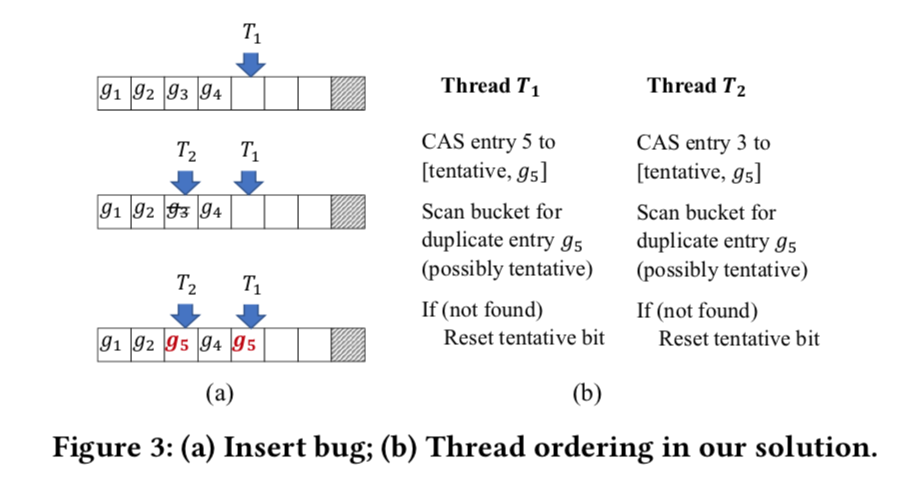
FASTER 使用 tentative bit 实现了 two-phase insert 来解决这个问题:
CAS设置空闲entry时,先设置tentative bit,该entry目前无法使用。- 重新遍历
bucket查找是否有相同tag的entry:- 有:清理
entry,重试。 - 没有:重置
tentative bit,完成。
- 有:清理
相当于乐观锁,先插入,然后看是否冲突,冲突则回滚重试。
Hybrid-log
latch-free hash table 搭配不同的 Record Allocator 即可实现多样的存储,如搭配 malloc 就是内存数据库但不支持持久化和恢复。需要注意的是即使 index 是并发安全的,
不代表数据访问是并发安全的(隔离性、memory safety 等),这些需要其他策略来保证,比如采用 append-only + MVCC。而在 FASTER 中,
具体的逻辑是由用户实现的,比如之前的压测场景,value 是 8 bytes integer,可以保证更新和读取操作是原子的,FASTER 内部使用 epoch protection 来保证 memory safety。更复杂的场景可以
使用 record-level lock。
当 Record Allocator 分配 logical address 而不是 physical address 即可支持大于内存的存储,如论文里提到的 Append-Only-Log:
- 从固定大小的
circular buffer分配Record内存,buffer划分为固定大小的page,Record Address代表<page, offset>。 - 所有的写、更新操作都新分配内存,更新
index(append-only)。 - 当进入新的
page时,之前的page可以写到磁盘。 - 写到磁盘的
page会被循环使用,Head Offset和Tail Offset确定在内存的范围。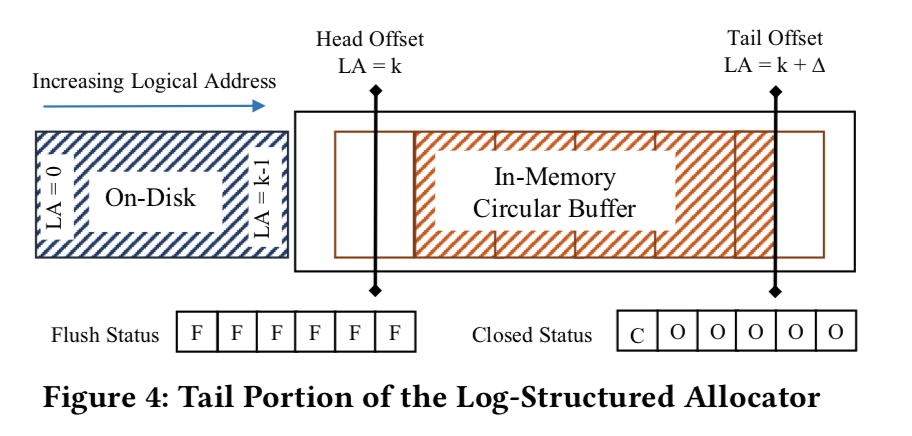
若读取的 Address 小于 Head Offset 就会从磁盘中读取,磁盘中数据格式和 buffer 一样,所以通过 <page, offset> 即可找到数据。FASTER 使用 direct i/o 来减少内存拷贝,async i/o 来避免阻塞,
每个线程 i/o 操作的结果会保存在 concurrent queue 中,需要用户主动调用 CompletePending 处理。
当 Tail Offset 增大进入新的 page 时,之前的 page 可以写到磁盘,但是要保证该 page 的所有写操作完成(因为内存分配出去不代表线程都更新完成了)。当 Head Offset 增大要复用之前的 page 时,要保证这个 page 没有其他线程访问且已被写到磁盘。
这都是通过 epoch protection framework 实现的:
- 进入新的
page时,注册<epoch, flush page>。当epoch安全时,可以保证该page所有操作都完成。 - 要复用
page时,注册<epoch, set page closed-status>。当epoch安全时,可以保证该page没有线程访问。
Append-Only-Log 的缺点是当写入很多时,page 的写磁盘就会成为瓶颈。Hybrid-Log 支持了 in-place update 能够解决 update-intensive 的场景:
- 减少数据拷贝。
- 减少
page的分配也就减少了状态同步和磁盘i/o。
in-place update 的困难在于 FASTER 为了性能,没有 WAL,采用的是 Hybrid-Log 即 WAL,但 Recovery 要求 Monotonicity,in-place update 很难保证,举个例子:
- 按顺序写
page到磁盘。 - 一个更新操作更新了下一个待写入到磁盘的
page,然后该page写到磁盘。 - 若此时机器挂掉,就不符合
Monotonicity了(新的写入保存了,之前的写入没了)。
Hybrid-Log 为了解决这个问题将整个 Circular Buffer 划分为 3 个区域:
Stable:数据在磁盘上。Read-Only:只读区域,等待写入到磁盘上成为Stable。Mutable:update in-place。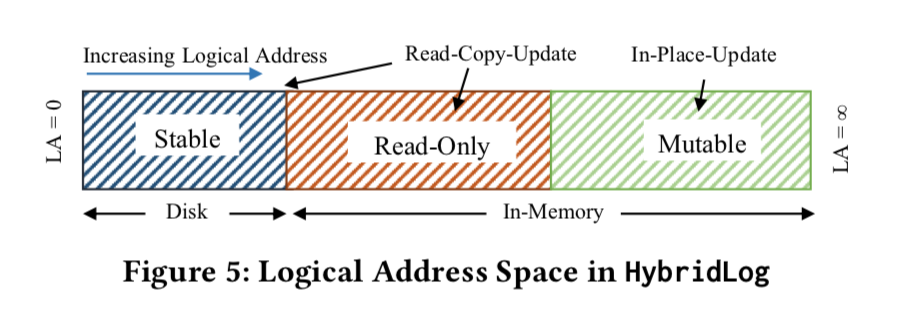
更新 Read-Only 区域的数据采用 RCU 在 Mutable 创建新的数据,从而保证了所有的更新都在 Mutable 区域,而 Mutable 要先变成 Read-Only 才能写到磁盘,所以能够保证 Monotonicity。
其实就相当于 Mutable 区域是 in-place update 的 memtable,Mutable 转为 Read-Only 就是 memtable compaction 只不过这里不是由其他线程写到磁盘,而是工作线程使用 async i/o 写。
因为完全的 latch-free 仍有许多细节需要考虑,比如论文里提到的 fuzzy region。
其他
FASTER的hash table支持resize,但是是阻塞的,每个线程负责一定数量的bucket。而且rehash不是准确的,当遇到在磁盘上的Record时为了效率会添加到所有可能的hash bucket中,索引使用的内存就会增加。FASTER的GC指清理磁盘上的log,实现很暴力,直接增加hybrid-log的begin address清理磁盘上对应的文件(hybrid-log在磁盘上划分为一个个segment file),然后清理hash table中所有address小于begin address的Record。FASTER支持index和hybrid-log的Checkpoint,来加快重启速度,具体实现就是把hash table和hybrid-log都写到磁盘,但因为Checkpoint过程中还会更新,所以仍是fuzzy的。
Summary
FASTER 论文中有很多未解决的问题,开源的实现也只是个原型,有很多局限性:
in-place update局限性很大,只适合update-intensive,而且如果新value大小比之前大,仍然需要分配新的内存。- 对读操作没优化,一种解决办法是读磁盘上的数据时也在
Mutable区域创建一个拷贝。 - 没有
WAL且GC太暴力,FASTER更适合做cache。 - 使用麻烦,接口暴露内部实现。
- 开源实现中很多未实现,如
Delete操作、hash table是纯内存的。 - 许多操作实现为阻塞式的,如
hash table resize。
留下评论