ScyllaDB 学习(二) – seastar 简介
seastar 是 ScyllaDB 使用的框架,从官网介绍可以看到 seastar 是为现代硬件设计的高性能框架。
Seastar is an advanced, open-source C++ framework for high-performance server applications on modern hardware.
High-level Goals
什么是现代硬件呢?先来看几张图,图来自 Under the Hood of a Shard-per-Core Architecture。
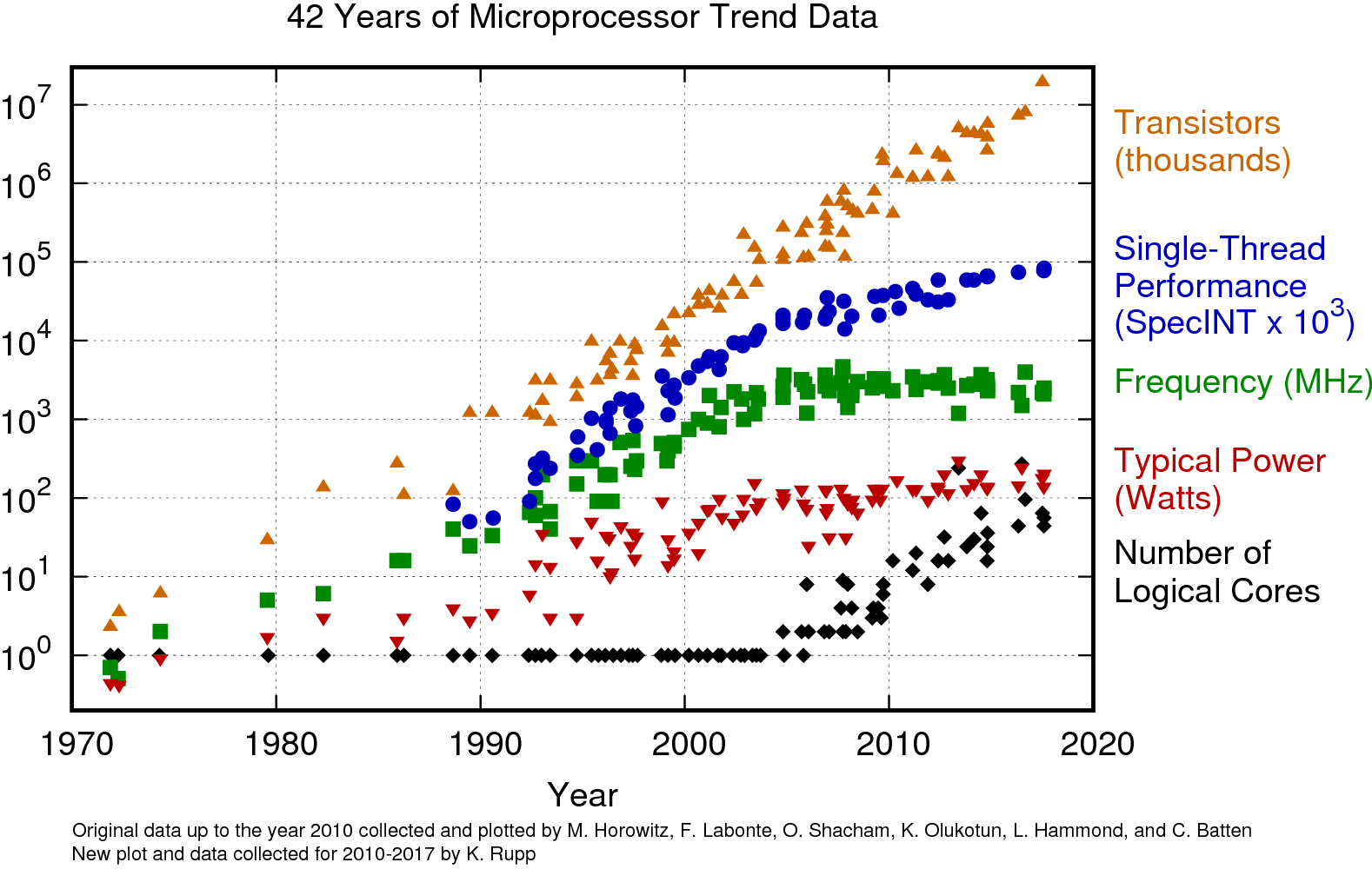

单核的性能已经进入平稳期,CPU 朝着数量越来越多发展,其他硬件发展也很快,盘的容量、吞吐和 IOPS 越来越高,网络也不再是瓶颈,而传统架构的软件已经无法很好的利用现代硬件资源。seastar 就是因此设计的,它的目标是(来自 ScyllaDB: No-Compromise Performance):
- Efficiency:
- Make the most out of every cycle
- Utilization:
- Squeeze every cycle from the machine
- Control:
- Spend the cycles on what we want, when we want
Efficiency 指充分利用每个 CPU cycle,获取尽可能高的 IPC,也要避免资源浪费,只把资源用在有用的地方,包括避免 memory copy、cache coherence、context switch、locking 等。Utilization 是因为大部分软件的单机扩展性都不好,无法利用到大型机器的所有 CPU、IO 资源,只能用小型机器或者拆分进程,企图用集群的扩展性掩盖单机扩展性的问题,但进程实例越多,也意味着故障发生的概率越高、更难运维,所以 seastar 目标是单个进程内也是随资源线性扩展的。Control 是因为系统内通常会有各种 background jobs 和 foreground jobs 竞争资源,比如 compaction,所以 seastar 目标是能控制任务的资源使用,实现 self-tunning/workload-conditioning 从而获取 consistent latency。
Shared-Nothing/Shard-per-Core
想要利用好现代硬件,就要 no locks/shared-memory/synchronization/context-switches/memory-copies,seastar 给出的答案是 shared-nothing 或者叫 shard-per-core 架构,单个进程也像分布式一样做 sharding 从而获取线性扩展性。
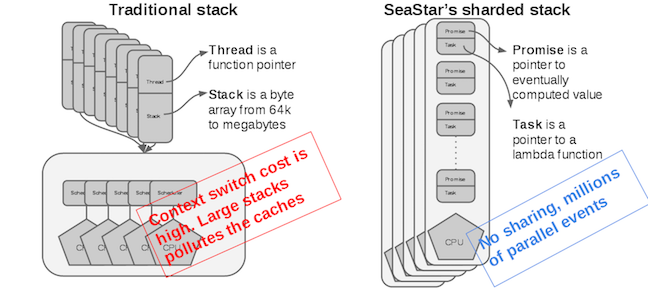
shard-per-core 不是简单的创建核数个线程,再把每个线程 pin 在一个核上就结束的,有很多问题要解决。
Asynchrony, Everywhere
因为每个线程都是完整的工作单元,需要处理茫茫多的执行流,所以不能有阻塞得是纯异步的,coordination 开销也要尽可能小。seastar 实现了 futures, promises, and continuations (f/p/c) 来提供更好的抽象和开发体验。
Memory
memory 越来越大,但 CPU 和 memory 的性能差距也越来越大,memory I/O 很可能成为系统瓶颈,这个问题随着核数的增多也越来越明显,CPU 使用率高也不代表在工作(CPU Utilization is Wrong)。NUMA 就是优化这个问题的一种办法,它把 CPU 和 memory 分成多个 zone(node),不同 zone 之间互联,单个 zone 内的 memory I/O 很快但跨 zone 就很慢,这也导致未针对 NUMA 架构优化的程序在 NUMA 下性能表现不佳。
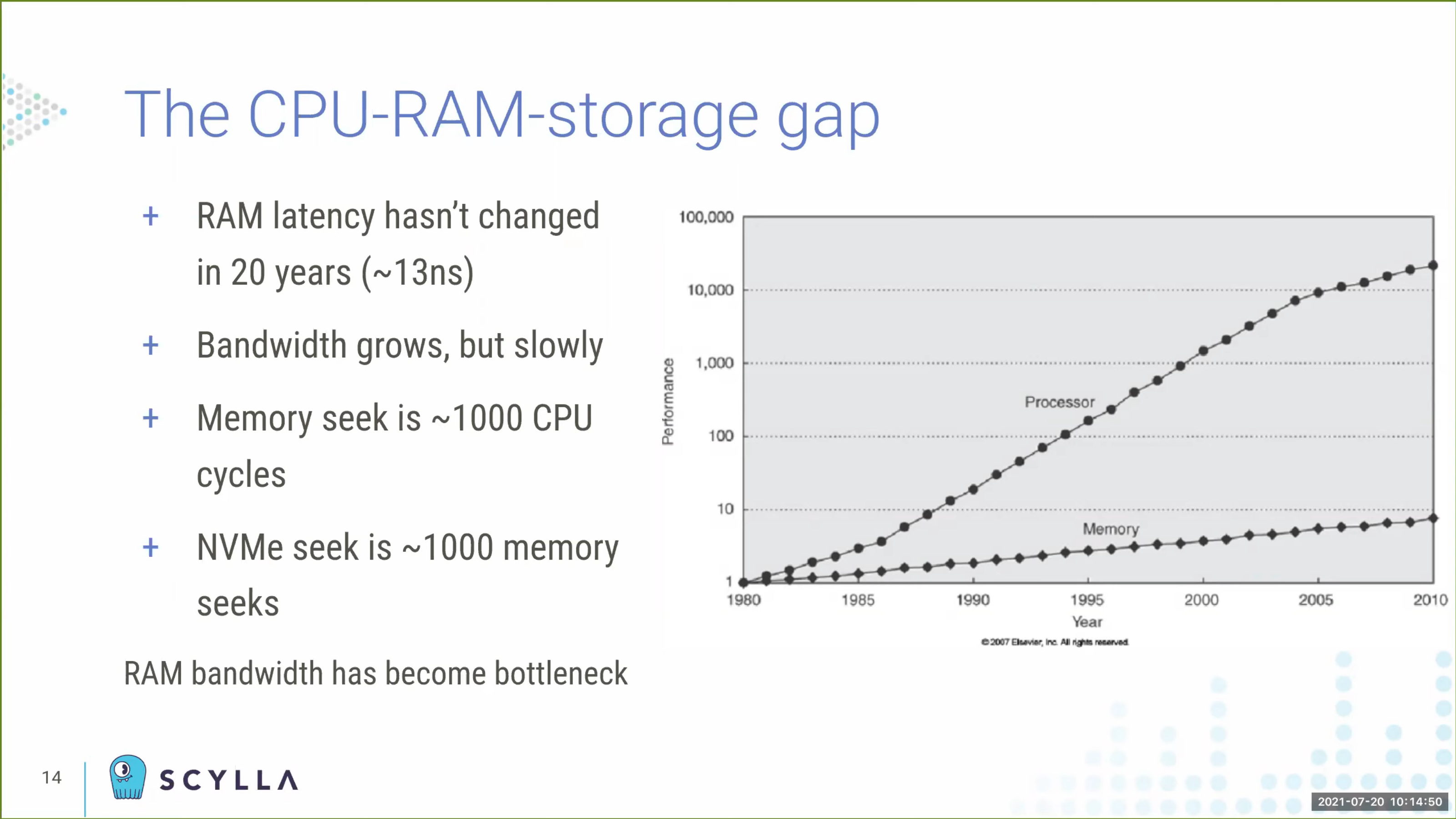
想要利用好 NUMA 就要避免跨 zone 的内存访问,除此之外,由于 seastar 架构的特殊性,现在的内存分配库里的线程同步都是没必要的,所以 seastar 实现了自己的内存分配器,每个线程会独占一部分内存(会考虑 NUMA)进行分配和释放,从而避免同步和实现 NUMA friendly。当需要共享内存时,seastar 为每对线程都创建了 spsc 无锁队列用于消息通信。
Kernel
即使用户程序实现了 shared-nothing,但 kernel 是基于 shared-memory 实现的,并不非常 scalable:
- Networking stack:在 Linux posix 网络协议栈下,一个网络包可能会经过 3 个 CPU 才能真正被应用线程处理到:处理硬件中断的 CPU -> 处理软件中断的 CPU -> 处理该 socket 的 CPU,而且用 socket 接口必然会发生 memory copy,所以
seastar除了 posix 协议栈外也提供了用户态协议栈,使用 DPDK 来传输数据。 - Disk I/O:
seastar要纯异步自然就只能用异步 I/O,因为是 14 年开始的项目,当时 Linux 下唯一的选择就只有 AIO,AIO 只能用 direct I/O,所以需要自己实现 cache,不过 page cache 是由操作系统管理的,用户态程序缺少控制,既是线程安全的也不能避免 memory copy(非 mmap),本身就不在seastar考虑范围内。 - Control:
seastar想要能控制所有任务的 CPU、I/O 资源使用,所以基于 control theroy 实现了 CPU&I/O scheduler。CPU scheduler 可以在 future executor 实现。Linux I/O scheduler 因为无法精细控制请求优先级、reorder/merge 导致延迟不稳定等原因也被禁掉了(使用 noop),ScyllaDB会自动 benchmark 当前 disk 获取最佳的并发度用于调优用户态 I/O scheduler。
参考资料
- ScyllaDB: No-Compromise Performance 20 年在 CMU DB 课上的分享,但不完整,看了下和 17 年 InfoQ 上的分享大致一样。
- Under the Hood of a Shard-per-Core Architecture 介绍 shard-per-core 架构需要解决哪些问题。
总结
只能说搞底层的人就是牛逼,一言不合 bypass kernel,但是 full control of the software stack 确实带来了非常大的收益。
留下评论