Redis源码阅读(十) – persistence
Redis是内存数据库,数据全部存放在内存中,一般用于缓存,它的持久化与传统数据库不同。持久化由2部分组成:
rdb: The RDB persistence performs point-in-time snapshots of your dataset at specified intervals.aof: the AOF persistence logs every write operation received by the server, that will be played again at server startup, reconstructing the original dataset. Commands are logged using the same format as the Redis protocol itself, in an append-only fashion. Redis is able to rewrite the log on background when it gets too big.
rdb
触发rdb有2种方式:
SAVE或者BGSAVE主动触发:SAVE会在当前进程中执行rdb,BGSAVE会在子进程中- 配置
save <second> <changes>被动触发,save ""为不使用rdb
当配置了rdb后,serverCron()中会检查是否满足触发rdb的条件:
/* If there is not a background saving/rewrite in progress check if
* we have to save/rewrite now */
for (j = 0; j < server.saveparamslen; j++) {
struct saveparam *sp = server.saveparams+j;
/* Save if we reached the given amount of changes,
* the given amount of seconds, and if the latest bgsave was
* successful or if, in case of an error, at least
* CONFIG_BGSAVE_RETRY_DELAY seconds already elapsed. */
if (server.dirty >= sp->changes &&
server.unixtime-server.lastsave > sp->seconds &&
(server.unixtime-server.lastbgsave_try >
CONFIG_BGSAVE_RETRY_DELAY ||
server.lastbgsave_status == C_OK))
{
serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...",
sp->changes, (int)sp->seconds);
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo(&rsi);
rdbSaveBackground(server.rdb_filename,rsiptr);
break;
}
rdb的执行过程如下:
- 创建管道用于进程间通信
fork()子进程- 关闭监听套接字
- 子进程写
temp file - 完成调用
rename()覆盖原rdb文件 - 通过管道写
cow_size
同样,在serverCron()中也会检查rdb是否完成,更新相关状态。
rdb文件格式
vim中可以用%!xxd查看rdb文件,具体格式可以看Redis RDB Dump File Format,不过版本有点老,
Redis4.0的RDB_VERSION为8。rdb内容如下:
rdb版本:REDIS%04d % RDB_VERSIONAUX field:redis-ver: redis版本redis-bits: 操作系统位数ctime: 当前时间used-mem: malloc分配内存大小repl-stream-db: 当前选择的dbrepl-id: master replication idrepl-offset: master replication offsetaof-preamble: aof-use-rdb-preamble
select db: 当前的db id, 会对每个db记录3 - 6resize db:db size和expire size,用于load时resize dbkey value pair: 包含过期时间RDB_OPCODE_EOFchecksum: 启用rdbchecksum会用crc64()计算,不启用为0
存储格式
一般分为3部分: , 按照上面的顺序记录一下:
, 按照上面的顺序记录一下:
rdb版本: REDIS0008AUX field: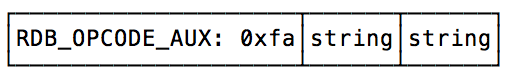
select db:
resize db:
key value pair:
RDB_OPCODE_EOF:0xffchecksum:little-endian uint64_t
Redis在许多数据结构中都用到了ziplist,由于ziplist存储在连续的内存中,save和load只需要完整记录,又方便又快。
load
在Redis启动前需要重新加载数据。在load rdb过程中,Redis只能处理少部分标记了CMD_LOADING的命令,其余的会返回loadingerr。
aof
aof是Redis持久化的另一种方式,基本原理是记录每一条会改变data set的命令,写入aof文件中,当启动时会逐条执行,恢复数据。
在call()中会调用propagate()将命令记录在server.aof_buf中,同样也会将also_propagate()记录的命令写入,also_propagate()主要用于
在命令内部增加命令记录,原因是数据结构的随机性会使不同的命令有不同的结果,需要一些转换。
写入
aof和传统数据库的日志类似,为了数据的可靠性,会在返回给客户端响应前,在beforeSleep()中调用flushAppendOnlyFile()将aof写到磁盘。
feedAppendOnlyFile()将命令追加到server.aof_buf中,真正写入aof文件是调用flushAppendOnlyFile()。为了提高性能,写入文件不会立即写到磁盘上,
会经过多个缓冲区,比如write()调用写入到内核缓冲区,这时会等待操作系统将数据刷新到磁盘。fsync()一般会立即将数据刷新到磁盘中,然而一些操作系统或者硬件的
行为会有不同,但是一般认为fsync()为可以控制的最高保障。Redis不是同步调用fsync(),而是放在一个后台线程执行。配置项appendfsync影响fsync()的行为:
everysec(default): 默认配置,每秒调用一次fsync()no: 从不调用fsync(),依赖操作系统刷新always: 每次都调用fsync(),最高保障,性能会降低
出错
当调用write()出错时,会标记server.aof_last_write_status = C_ERR,此时Redis会拒绝写请求,在serverCron()中重新调用flushAppendOnlyFile(),直到成功写入aof。
aof rewrite
aof是将每条命令记录到文件中,随着命令的增多,文件会很大,导致磁盘空间的浪费,并且加载aof也会变慢。当aof文件大小超过auto-aof-rewrite-min-size指定比例auto-aof-rewrite-percentage时,
Redis会自动进行aof rewrite:
/* server.c:serverCron */
/* Trigger an AOF rewrite if needed */
if (server.rdb_child_pid == -1 &&
server.aof_child_pid == -1 &&
server.aof_rewrite_perc &&
server.aof_current_size > server.aof_rewrite_min_size)
{
long long base = server.aof_rewrite_base_size ?
server.aof_rewrite_base_size : 1;
long long growth = (server.aof_current_size*100/base) - 100;
if (growth >= server.aof_rewrite_perc) {
serverLog(LL_NOTICE,"Starting automatic rewriting of AOF on %lld%% growth",growth);
rewriteAppendOnlyFileBackground();
}
}
aof rewrite流程如下:
- 创建子进程,根据内存里的数据重写
aof,保存到temp文件 - 此时主进程还会接收命令,会将写操作追加到旧的
aof文件中,并保存在server.aof_rewrite_buf_blocks中,通过管道发送给子进程存在server.aof_child_diff中,最后追加到temp文件结尾 - 子进程重写完成后退出,主进程根据子进程退出状态,判断成功与否。成功就将剩余的
server.aof_rewrite_buf_blocks追加到temp file中,然后rename()覆盖原aof文件
aof rewrite过程中,Redis同样接收命令,在feedAppendOnlyFile()中会将写命令同时写入server.aof_buf和server.aof_rewrite_buf_blocks,老的aof文件同样被追加,同时创建事件通过管道给子进程
发送server.aof_rewrite_buf_blocks的数据,子进程在rewriteAppendOnldyFileRio()中每写入AOF_READ_DIFF_INTERVAL_BYTES数据后就会读取一次。在重写完后,会将diff数据追加到文件中,这里为了避免
主进程一直在发数据,通关管道来通信:
/* Ask the master to stop sending diffs. */
if (write(server.aof_pipe_write_ack_to_parent,"!",1) != 1) goto werr;
if (anetNonBlock(NULL,server.aof_pipe_read_ack_from_parent) != ANET_OK)
goto werr;
/* We read the ACK from the server using a 10 seconds timeout. Normally
* it should reply ASAP, but just in case we lose its reply, we are sure
* the child will eventually get terminated. */
if (syncRead(server.aof_pipe_read_ack_from_parent,&byte,1,5000) != 1 ||
byte != '!') goto werr;
serverLog(LL_NOTICE,"Parent agreed to stop sending diffs. Finalizing AOF...");
/* Read the final diff if any. */
aofReadDiffFromParent();
在主进程serverCron()中同样会检测子进程结束,调用backgroundRewriteDoneHandler(),进行后续处理:
- 写最后的
diff数据 rename()文件。rename()有时会是个昂贵的操作,会执行文件的删除操作,close()同样也是,当文件已经被unlink()时,但还有文件描述符指向该文件,文件不会被 立即删除,直到最后一个文件描述符close()。Redis使用后台线程执行真正的删除操作。
比较奇怪的是aof rewrite过程用到了2个临时文件:
rewriteAppendOnlyFileBackground()里temp文件为:temp-rewriteaof-bg-{pid}.aofrewriteAppendOnlyFile()里temp文件为:temp-rewriteaof-{pid}.aof,最后rename为temp-rewriteaof-bg-{pid}.aof- 在主进程
backgroundRewriteDoneHandler()中rename(temp-rewriteaof-bg-{pid}.aof, server.aof_filename)
为什么子进程不用一个文件,在主进程最后rename呢?没找到原因,不过猜测可能有时序的问题。
aof-use-rdb-preamble
rdb文件小,加载速度快,然而丢数据比aof多,aof更可靠,但文件大,加载慢。没有理由不把rdb和aof结合起来,和数据库类似,先加载数据,然后执行redo/undo日志。
Redis4.0新增了一个配置aof-use-rdb-preamble:
When rewriting the AOF file, Redis is able to use an RDB preamble in the AOF file for faster rewrites and recoveries. When this option is turned on the rewritten AOF file is composed of two different stanzas:
[RDB file][AOF tail]
When loading Redis recognizes that the AOF file starts with the “REDIS” string and loads the prefixed RDB file, and continues loading the AOF tail.
This is currently turned off by default in order to avoid the surprise of a format change, but will at some point be used as the default.
在rewriteAppendOnlyFile()中,有如下代码:
if (server.aof_use_rdb_preamble) {
int error;
if (rdbSaveRio(&aof,&error,RDB_SAVE_AOF_PREAMBLE,NULL) == C_ERR) {
errno = error;
goto werr;
}
} else {
if (rewriteAppendOnlyFileRio(&aof) == C_ERR) goto werr;
}
使用该配置,aof rewrite会先做一次rdb,然后将diff以aof形式追加到rdb文件中,文件名字还是server.aof_filename。
loadAppendOnlyFile()中会首先判断aof文件开头,若是以REDIS开头,会先加载rdb,然后在创建fakeClient,执行aof命令:
/* Check if this AOF file has an RDB preamble. In that case we need to
* load the RDB file and later continue loading the AOF tail. */
char sig[5]; /* "REDIS" */
if (fread(sig,1,5,fp) != 5 || memcmp(sig,"REDIS",5) != 0) {
/* No RDB preamble, seek back at 0 offset. */
if (fseek(fp,0,SEEK_SET) == -1) goto readerr;
} else {
/* RDB preamble. Pass loading the RDB functions. */
rio rdb;
serverLog(LL_NOTICE,"Reading RDB preamble from AOF file...");
if (fseek(fp,0,SEEK_SET) == -1) goto readerr;
rioInitWithFile(&rdb,fp);
if (rdbLoadRio(&rdb,NULL) != C_OK) {
serverLog(LL_WARNING,"Error reading the RDB preamble of the AOF file, AOF loading aborted");
goto readerr;
} else {
serverLog(LL_NOTICE,"Reading the remaining AOF tail...");
}
}
load
和rdb一样,在loading过程中,同样会处理少部分命令。
持久化保证
将数据写入磁盘通常需要以下几步:
- 调用系统调用写入磁盘,此时数据在内核缓冲区
- 操作系统将内核缓冲区数据写入
disk controller,此时数据在disk cache disk controller将数据写入物理介质
不同的步骤有着不同的持久性保障,第1步可以容忍进程挂掉,第3步完成可以容忍机器故障,比如断电。但是第3步通常没有办法控制,所以一般有以下两个认识:
- 调用
write()可以保证在进程挂掉的情况下数据的安全性 - 调用
fsync()可以保证在系统出错的情况下数据的安全性
write()操作的耗时我们没法知道,内核缓冲区的大小是有限的,如果磁盘的写入速度比应用的写入速度慢的话,会造成内核缓冲区满,然后阻塞住。fsync()同样是个昂贵的操作,
每次调用都会启动一个写操作,同样的,fsync()也会阻塞住进程,在Linux下还会阻塞其余线程对相同文件的写操作。频繁的调用这2个系统调用会影响应用的性能,这就带来了2个问题:
- 什么时候调用
write() - 什么时候调用
fsync()
Redis是这样做的:
rdb: 每次都会将数据刷新到磁盘。因为rdb次数较少,一般都在子进程做,影响不大。只开rdb的话,可能会丢失几分钟的数据,这根据配置而定。aof: 根据appendfsyn执行。aof的执行次数很多,每条写命令都会追加aof,如果每条命令都刷新到磁盘,会影响性能。采用默认配置,最多只会丢失1s数据。
COW
Redis创建子进程执行rdb和aof rewrite,操作系统为了提高创建进程的速度和减少内存的浪费,采用了两种技术:
- 内核将每个进程的代码段标记为只读,父、子进程的页表项指向相同的页帧实现共享代码段。
- 对于可变的段,如数据段、堆栈等,采用写时复制(copy-on-write)技术。父子进程在开始时,页表项指向相同的物理页帧,当需要修改某些虚拟页时,内核将拷贝该页分配给进程。
内存对Redis来说非常珍贵,所以Redis为了减少COW带来的内存增加,在有子进程的时候会尽量减少dict rehash:
/* This function is called once a background process of some kind terminates,
* as we want to avoid resizing the hash tables when there is a child in order
* to play well with copy-on-write (otherwise when a resize happens lots of
* memory pages are copied). The goal of this function is to update the ability
* for dict.c to resize the hash tables accordingly to the fact we have o not
* running childs. */
void updateDictResizePolicy(void) {
if (server.rdb_child_pid == -1 && server.aof_child_pid == -1)
dictEnableResize();
else
dictDisableResize();
}
留下评论