Reading Notes
2022
08-03 | Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service (2022) | 9☆
原来 DynamoDB 和 Dynamo 不是一个东西!DynamoDB 的 data model、sharding、replication 等都完全变了。这篇论文的重点是 service,database 和 database service 差了十万八千里,service 需要隐藏各种细节,对上只需要提供稳定的服务即可,对于 DymanoDB 来说,就是不受访问模式/数据量/故障影响的、稳定的延迟。DynamoDB 也是 range partition,每个 partition 是一个 paxos group,每个 storage node 上有多个 partition;是 multi-tenant 架构的,实现了 admission control 来做资源隔离,论文重点介绍了这部分的演进,从 partition 级别的控制到有 burst 和自适应再到有 global 级别的控制;其他部分的优化就不在这里介绍了,感兴趣的就看论文吧,还是很实用的,虽然没有很多细节。最后要感叹一下 DynamoDB 确实牛逼。
08-01 | Dynamo: Amazon’s Highly Available Key-value Store (2007) | 8☆
我才不会告诉你们我从没看过 Dynamo 的论文。Dynamo 在 2007 年的架构影响了一批 NoSQL 的设计,它设计的主要目标是高可用(重点是写)和可选择的 SLA,用到的技术有 consistent hash、vector clock、sloppy quorum、gossip 等,也很复杂了,而且 API 看起来非常不易用。
04-02 | Aerospike: Architecture of a Real-Time Operational DBMS (2016) | 4☆
看这篇论文是因为 Aerospike 声称是 ScyllaDB 的 7 倍吞吐和 1/3 的延迟,但看了论文没什么特别亮眼的地方,线程模型和实现并没有 seastar 好,如果 benchmark 结果确实如他们所说的话,感觉原因出在数据模型和架构上。
04-01 | File Systems Unfit as Distributed Storage Backends: Lessons from 10 Years of Ceph Evolution (2019) | 6☆
介绍了 Ceph 绕过 local file system 直接在 raw storage device 上实现的 storage backend —— BlueStore。local file system 在这种场景下主要有这几个问题:不支持事务或者说个性化功能在 file system 上实现代价比较高、metadata 操作太重(readdir 之类的操作)、应用程序对 I/O 栈的掌控、以及无法很快用上更先进的存储设备接口。BlueStore 的吞吐、延迟和稳定性都比上一代好一倍左右,具体实现看论文吧,没什么特别让人有启发的,值得一提的是再下一代的 storage backend 是基于 seastar 的。
03-31 | Evolution of Development Priorities in Key-value Stores Serving Large-scale Applications: The RocksDB Experience (2021) | 7☆
介绍了 RocksDB 这几年开发过程中的经验教训,没什么特别有启发的,挑几个介绍一下:
- LSM-tree 仍是 SSD 时代好的选择,考虑到 SSD 的价格、读写特性和 FTL 的算法。LSM-tree 通过调整 compaction 策略来选择 RUM。
- RocksDB 的优化目标从写放大到空间放大再到 CPU,因为发现大部分应用场景下 disk 性能不是瓶颈,而且应用包括 RocksDB 也无法充分利用越来越快的 disk,所以转而去优化空间放大、CPU。
- 单个进程或者机器上可能会有很多 RocksDB 实例,全局的资源控制能力也是有必要的。
- compaction 除了会创建新的 SST 还会删掉旧的 SST,而删 SST 也需要限流,因为删文件也会触发 I/O 或者调用 SSD 的 TRIM 命令,即使是 TRIM 也会影响性能,因为同样有 I/O,可能会触发 SSD 内部的 GC。
- 因为 RocksDB 服务的场景很多、数据量很大,经常会遇到 silent corruptions,所以 RocksDB 有很多 checksum 检测:K/V、WAL、block、file 级别的等,对于数据错误需要尽可能早地检测出来且每一层都需要做。
- RocksDB 目前的接口没办法很好的支持 MVCC 和分布式事务,解决办法是提供 application-specified timestamp 接口,论文里写到用 DB-Bench 压测有 1.2-2.0 倍的吞吐提升。我之前一直以为这东西没什么用,现在看起来对点查之类的比较有用,因为可以直接用 get 而不是 seek,而且 bloom filter 也可以派上用场了。
03-23 | Designing Access Methods: The RUM Conjecture | 7☆
提出了 RUM Conjecture:优化其中两项必定以另外一项为代价。这里的 RUM overhead 指的是放大,即读/更新/空间放大,没有考虑访问模式的代价。还有篇相关的论文 Design Tradeoffs of Data Access Methods 介绍了很多单独为某个方面优化的数据结构和论文,可以当个目录看看。
03-19 | Latch-free Synchronization in Database Systems: Silver Bullet or Fool’s Gold? | 3☆
在相同的 benchmark 框架下对比了 latch-based 和 latch-free 结构的性能和扩展性,结论是半斤八两,想要提升扩展性就要减少共享,TMD。
02-03 |《不拘一格》| 10☆
2020 年新出的介绍奈飞文化的书,更具可操作性。
01-29 |《奈飞文化手册》| 9☆
花了一个下午看完了,醍醐灌顶,奈飞这公司也太酷了,值得为这本书专门写篇博客。
2021
12-19 | KVell: the Design and Implementation of a Fast Persistent Key-Value Store | 8☆
12-19 | SpanDB: A Fast, Cost-Effective LSM-tree Based KV Store on Hybrid Storage | 6☆
SpanDB 在 RocksDB 基础上做了这几个事情:
- 使用 SPDK + 异步流程 + 并行写 WAL 来优化 RocksDB 写 WAL 的性能。RocksDB 写 WAL 在高速盘上会成为瓶颈(我觉得)应该是共识了,因为它是单线程串行写而且还有 write group 同步的开销,会导致无法充分利用高速盘,论文里也提到了用 Optane P4800X 只比 SATA SSD 提升了 23.58%。OLTP 系统想要充分利用高速盘,高的 I/O depth 是必不可少的,所以需要用纯异步来增加盘的压力、并行写 WAL 来增加 I/O depth,这里 SPDK 和异步流程就不介绍了,感兴趣的看论文吧,个人感觉即使不用 SPDK 只用 async I/O 也能达到类似的优化效果,这里只重点介绍一下并行写 WAL。SpanDB 预先给每个 memtable 划分好 WAL 空间,WAL 空间又划分为固定 4KB 大小的 page,并行的写 WAL 请求会被分配不重叠的、连续的 page 从而支持并行写,recovery 通过 metadata page 里记录的每个 memtable 的 WAL 信息和 WAL page 的 LTN 来确定需要回放的 page。
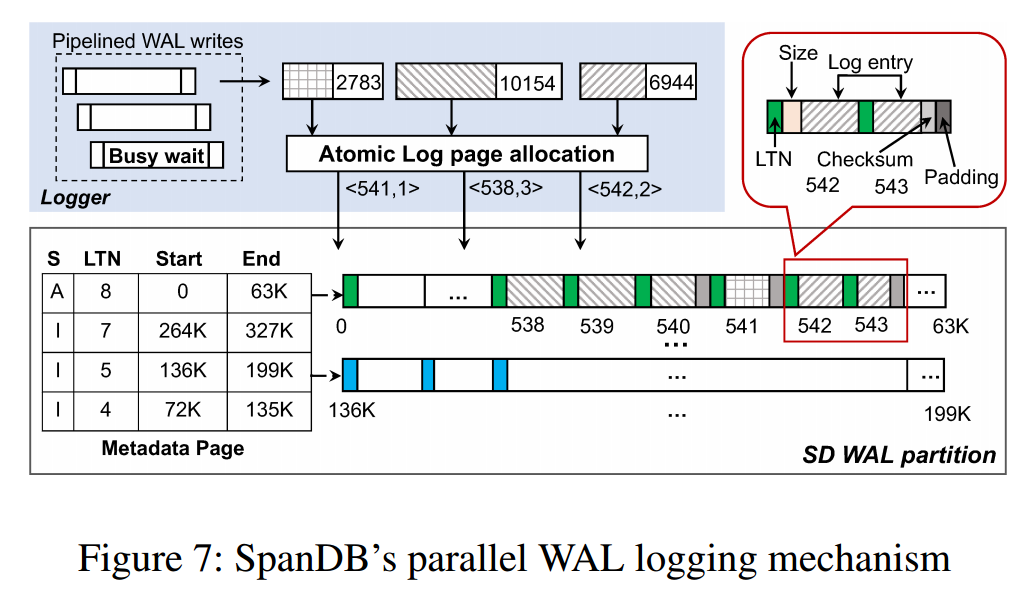
- 为了降低存储成本,只有 WAL 和前几层的 SST 在 SD(speed disk,也就是 NVMe SSD)上,更高层的会放在 CD(capacity disks,SATA SSD 之类的)上,还会根据 SD 和 CD 的压力情况动态调整新 SST 的存放位置。
- 有一定的自适应策略来避免 SD 压力饱和导致影响写 WAL 延迟、减轻 compaction 对 WAL 的影响,但都是非常基础的策略。
取得的效果还是不错的,ycsb 测试全面提升,纯写场景 8 倍吞吐且延迟更低,但这篇文章没什么新意,唯一的优点是好落地,类似的优化在工业界应该不少。讲道理这篇文章能中顶会(FAST 2021)我是比较惊讶的,seastar 在 2015 年就把最佳实践告诉了世界,但是 2021 年了真正用上的系统还是没多少,而且提供异步接口的存储引擎适用性并不好,强行嵌入到应用里无法发挥它的最大能量,异步更适合和应用一起在统一的框架下执行,而不是单独内置异步 runtime。
01-01 | Tales of the Tail: Hardware, OS, and Application-level Sources of Tail Latency | 10☆
非常好的一篇论文,涨了不少见识,但想要从中学到很多的话需要自己实践才行。论文研究 tail latency,首先用 queuing theory 计算出特定模型下的理论延迟分布,然后用不同架构的应用测出实际的延迟分布,分析理论和实际的差距并逐一解决,最终得到了近似最优的延迟分布。
首先说下 queuing theory,这是在计算机系统里非常非常有用的理论,感觉所有计算机系统都能套上这个理论(无论是硬件还是软件,有什么地方不需要排队吗?无非是最大并发超出了请求到达的速度,并发肯定是有上限的,当处理不过来时必然会发生排队),大家所熟知的 little’s law 就是 queuing theory 中最简单的一种,但已经能指导很多工作了。
论文研究的是 single queue 系统,也就是请求在单个队列中排队,多个 worker 从中取请求来执行,即 A/S/c queue,A 是请求到达速率的分布,S 是请求处理时间的分布,c 是 worker 的个数。在这篇论文里 S 是固定的,即所有请求处理的时间是相同的,这也符合大多数系统的情况。如果请求个数始终低于系统最大并发数,必然不会发生排队,所以反映出来的延迟就是请求的处理时间,当一瞬间到达超出系统并发上限(c)个请求时,就会发生排队,导致延迟的上升,而且这不仅仅影响当时排队的请求,在被积压请求处理完成前到达的所有请求都会受到影响,也就是延迟的放大。tail latency 的主因是请求到达速率的不均衡,假设请求到达速率是均衡的,那么每个请求排队的时间都相等,反映出来的延迟就是排队请求个数*单个请求处理时间,不均衡就会导致请求的排队时间不同,反映出来的延迟也就不同,所以缓解 tail latency 的方式之一就是要提升系统处理 burst 的能力,包括:
- 降低系统使用率:即使请求到达速率的分布不变,但请求到达的数量变少了,排队也就变少了。
- 增加 worker 数量:即使在相同使用率情况下,worker 越多能容忍的 burst 也就越大。这里有个陷阱就是一定要是 single queue 的系统,如果每个 worker 单独一个 queue,这等价于多个 single queue 系统,延迟分布不会随着 worker 增加而改善,当然吞吐是会增加的。
另外一个影响 tail latency 分布的因素是请求处理策略或者叫调度,FIFO 有着最好的 tail latency,而 LIFO 有着更好的 median latency。
论文里测试了 3 类系统,对应了 3 种模型,包括:
- 来一个连接建一个线程来处理的
Null RPC server。 Memcached:线程数量固定,但分为 TCP 和 UDP 模式。TCP 模式下连接被 partition 到特定线程处理,UDP 模式下每个线程都从相同的 UDP 套接字里接受请求来处理,操作系统保证了请求的 FIFO。Nginx:固定进程数量的 event loop,每个连接也是固定单个线程处理的。
为了分析延迟的来源,论文的做法是给每个请求从 NIC 层就开始记录处理时间。这 3 种系统实际的延迟分布和理论差距都很大,但受不同的因素影响,包括:
- background process:操作系统本身就有一些进程在运行,这些进程会占用应用的 CPU 时间。在默认的 CFS 调度下,即使提升了应用进程的优先级,其他进程的影响还是很大,因为 CFS 调度只是给高优先级进程更多的时间片,无法抢占其他进程,也无法完全消除其他进程的影响。而使用 realtime 调度能几乎消除掉其他进程的影响,因为它支持抢占。
- Non-FIFO Scheduling:这里的调度还是操作系统的调度,当其他进程被绑定到单独的核上时,调度的竞争只会出现在单个核上的多个线程之间,这只会影响
Null RPC server,因为只有它是多个线程在一个核上。在默认的 CFS 调度下,线程还是按时间片来调度,所以先到的请求也可能后处理完成,因为线程被调度出去了,所以线程数过多的影响不仅仅是 context switch 的开销,还有调度的影响。解决办法同样是用 realtime 调度,因为相同优先级的线程是 FIFO 调度,请求也就是 FIFO 处理了。 - Multicore:这点不是探讨实际和理论的差距的,而是验证在相同使用率的情况下,提高 worker 数量是否可以缓解 tail latency。因为论文里的测试是预先建立好连接,所有请求都发给这些连接,所以像 TCP 模式的
Memcached和Nginx都无法从中获益,因为连接固定由单个线程处理,而Null RPC server和 UDP 模式的Memcached就会从中受益。如果使用短连接来测试的话,Nginx也会有提升。 - Interrupt Processing:这点非常有趣,我也是第一次知道,还学习了下 linux 是如何处理网络包的,在这里也记录一下。当网络包到达 NIC 时会用 DMA 拷贝到 RAM 中然后触发 hardware interrupt 通知 CPU 来处理,如果设备支持
Receive Side Scaling(RSS)或者有多个 RX queue,这些硬件中断会分发到不同的 CPU 处理,从而提升接收网络包的速度,irqbalance进程就是干这事的。上面的操作是在 interrupt handler 上下文中执行的,这时可能会屏蔽硬件中断,导致中断丢失,为了减少屏蔽的时间,一些耗时较长的操作会延后来执行,这种机制的一种实现方式是softIRQ,linux 会创建核数个ksoftirqd线程来处理这些操作,网络包经过协议栈的处理就会在这些线程执行。默认情况下执行硬件中断的 CPU 会唤醒自己的ksoftirqd线程来处理网络包,但如果打开了Receive Packet Steering(RPS),可能会唤醒其他 CPU 的ksoftirqd线程来处理网络包。这意味着一个网络包可能会经过 3 个 CPU 才能真正被应用线程处理到:处理硬件中断的 CPU -> 处理软件中断的 CPU -> 处理该套接字的 CPU。这套流程会导致请求处理时间受 context switch 和 CPU cache pollution 的影响而不再固定,也会导致请求处理不再是FIFO的,因为后来请求的包处理可能占用了处理先到请求的 CPU。解决办法是使用 dedicated CPU 来处理中断,应用线程不再受到中断的影响,保证了请求的FIFO调度,但缺点是会影响吞吐,毕竟应用可用的 CPU 数量变少了。Solarflar 有篇 Filling the Pipe: A Guide to Optimising Memcache Performance onSolarFlare®Hardware 介绍了调优Memcached的步骤,其中就包含了这部分的详细操作流程。 - NUMA:这个就老生常谈了,TiDB 也经常遇到这个问题。linux 默认的 NUMA 内存分配策略是往死里分配一个 NUMA node 的内存,用完了再分配一下个的,而且应用内存划分不好的话,即使内存分配均匀了也会导致频繁的跨 NUMA node 的内存访问。解决办法就是绑核+多实例部署,TiDB 就是这么干的,但 TiKV 我们没强制要求这样做,我怀疑
是 TiKV 延迟太高导致这部分延迟占比可忽略不计🤣TiKV 的线程组碰巧比较符合 NUMA 这种模式,因为各线程组 workload 比较固定,也几乎不会访问相同的内存。 - Power Saving Optimizations:这又是一个我从来没注意过的点。当系统使用率较低时,CPU Power Saving Optimizations 会极大的影响 tail latency,包括 CPU 部分停止工作和降频等。解决办法当然是关掉这功能。
非常好的论文,从理论出发,却发现实践得不到预期的结果,毕竟理论和实践间还隔着一道鸿沟,最终逐步优化得到了近似理论值的结果,非常 solid,体现了非常高的工程素养。TiKV 目前还没到深入那么底层来优化的程度,因为本身延迟就不低,优化这些不会影响太多,在更高层的优化才能带来更多的提升。但这篇论文也很具有指导意义,比如使用 queuing theory 来计算理论延迟,当然 TiKV 不是那么简单的 single queue 系统,其中涉及到很多级流水线,每级流水线都是一个 queuing system,queuing system 串联起来肯定会产生更复杂的模型。TiKV 目前对请求的处理策略也不好,不能保证 FIFO,最典型的就是 batch system,后来的请求很可能会插队,而且还有如此多的线程。现在的我肯定没能力来完全解决这些问题,还需要多多学习,我目前只能做到下面这句话:
Combine theory and practice: nothing works and don’t know why.
01-01 | The Impact of Thread-Per-Core Architecture on Application Tail Latency | 6☆
这篇论文是研究 thread-per-core 发现的,因为非常仰慕 scylladb,它纯靠实现上的优化吊打相同架构的 Cassandra。这篇论文没讲什么东西,主要工作是实现了一个 shared-nothing thread-per-core 的纯内存 K/V 存储,然后和 Memcached 在各种调优网络中断的情况下比较 tail latency。远不如 Tales of the Tail: Hardware, OS, and Application-level Sources of Tail Latency,打 6☆ 的原因是让我发现了这篇论文😂。thread-per-core 架构有一些天然的优势,比如对 cache 非常友好、没有 context switch、没有线程同步等。但应用想要充分体现这些优势需要有特殊的资源管理策略、纯异步的编程方式,而且 thread-per-core 很容易被单个线程限死住,比如 workload 有倾斜,导致处理集中在单个线程上。如何做好这些都是值得深入研究的。
2020
11-14 | CRaft: An Erasure-coding-supported Version of Raft for Reducing Storage Cost and Network Cost | 3☆
用 (k,m)-RS code 来减少 raft 复制的网络和磁盘开销,只需要复制 1/k 大小即可,为了保证 liveness,复制过程有额外的约束和复杂度。抛开复制的复杂度而言,follower 上只有部分的 log,也就没办法 apply 到状态机,当 leader 发生切换时,需要从其他 follower 上恢复出完整的 log 再 apply,这个代价是不可忽视的。从这点来说,感觉不太实用,尤其对于 TiKV 这种 leader 变更很频繁的系统。
08-02 | Systems Performance: Enterprise and the Cloud | 8☆
信息量非常大的一本书,介绍了非常多的分析工具,短时间内难以消化只能粗略过一遍,但前几章介绍的性能分析方法已经非常有用了。
我觉得迈向 senior 程序员必不可少的一步是提升查问题和分析量化的能力。查问题可能指程序功能或性能不符合预期,以我为例,我查功能问题最常用的方式是加 log,当然这可能是查分布式系统问题最好用的办法,或者是用 gdb,但同样的工具在不同水平的人手上会有天差地别的效果。分析量化既可以是宏观地分析整个系统的瓶颈或者是做容量规划,也可以是在实现细节上使用最佳的实现方式,更为重要的是能够预估收益,而不是胡乱做优化。这也是我一直欠缺并迫切需要加强的地方。
07-12 | Operating Systems: Three Easy Pieces | 9☆
我读过很多操作系统相关的书,比如《操作系统概念》、《现代操作系统》、CSAPP(我倾向于把它也归为操作系统的书)、TLPI,这算是第五本。为什么会读那么多呢?因为操作系统实在是太重要了,只有更了解操作系统才能写出更好地代码、更快地排查问题,而且我们平时会遇到一些操作系统同样会遇到并已解决的问题,就可以从中吸取经验教训。另一个原因是常读常新,在不同的时间节点会有不同的收获。
OSTEP 最值得称赞的是它的叙述方式,不像很多书直接告诉你解决办法,而是先抽象问题、设定目标、一步步迭代并解决问题,可以让读者了解现代操作系统为什么需要这么做并学习解决问题的思路。如果非要说缺点的话,那就是缺乏「术」的介绍而且练习太少,对于在校学生来说需要搭配其他书籍或课程来学习,比如 CSAPP、MIT 6.828。
书虽好,但我也不会无缘无故就花时间在这上面,原因其实是后面准备开一系列和操作系统紧密相关的坑,希望这本书能作为大纲来指导路线,它也确实做到了。
06-21 | CockroachDB: The Resilient Geo-Distributed SQL Database | 6☆
真的是巧,今年 TiDB 和 CRDB 都发了论文。不过友商的这篇论文只能打个6星(我们的论文也打不了高星😂),因为篇幅有限,还想要面面俱到就只能各部分浅显的介绍一点,不如他们官方文档和博客写的详细和有深度。强烈推荐他们的文档和博客,非常全面和易读,不管是从技术方面还是写作方面都值得学习。
05-12 | Clock-SI: Snapshot Isolation for Partitioned Data Stores Using Loosely Synchronized Clocks | 7☆
见 Clock SI。
04-06 | Calvin: Fast Distributed Transactions for Partitioned Database Systems | 5☆
这篇论文说实话没太看懂,给我的感觉是实现了非常特殊的状态机,状态机的输入是事务操作,所以只要用 paxos 之类的协议提交输入后事务状态就确定了,不需要走如 2PC 之类的 distributed commit protocol。
Calvin 是在单机存储之上实现的,数据分布在不同的 partition,每个 partition 是一个 replication group,用 paxos 之类的协议来复制。而 replica 在 Calvin 中指的是包含所有 partition 单个副本的多个节点,也就包含了所有数据。Calvin 中每个节点分为 3 层:
- Sequencer 接收客户端请求,对事务进行排序,把 transaction inputs 复制到 partition 副本。这层是分布式的,每个节点可以接收任意请求,不会按照 partition 来接收请求。不同 Sequencer 接收的请求无法排序,而且少量 transaction inputs 带来的复制代价比较大,所以 Calvin 采用的是 epoch 机制:每个 Sequencer 在 epoch 期间 batch 所有输入,再复制到 Sequencer partition 副本, 然后各 Sequencer partition 副本把 transaction inputs 下发给各 replica 内所有参与的 Scheduler,这样各 Scheduler 就可以收集到单个 epoch 来自所有 Sequencer 的输入,从而确定整个 epoch 输入的顺序(比如按照 Sequencer ID 来排序)。当然 Sequencer 提交了不一定事务就能成功提交,要看 Scheduler 执行的结果。
- Scheduler 使用确定的 lock 算法保证从 transaction inputs 并发执行也能得到确定的结果。因为是 RSM 所以要求确定的输入得到确定的结果,否则各个 replica 就不同了,这里复制的是 transaction inputs,而不是具体的操作,一个个串行执行当然可以得到确定的结果,但是性能很差,并发执行一般不能得到确定的结果,比如 serializable 级别的数据库能保证并发执行的事务是按照某种顺序串行执行的,但不会要求是哪种固定的顺序,也不要求每次都一样。Calvin 采用的是另一篇论文的 deterministic locking protocol,既能并发执行 transaction inputs 还能得到确定的结果。但为了确定性,Calvin 要提前知道事务所有的操作,所以不支持 Dependent transaction,也就是后面操作要基于前面结果的事务。那搞成 OCC 不就得了,客户端缓存所有的操作,事务提交时再发送给 Sequencer,Scheduler 采用的是 2PL 确定性算法,执行时要再检查 dependent read set 是否被修改了。
- Storage 没什么可说的,但是为了得到确定的结果,部分操作必须串行执行,所以卡在一个地方,剩下的都会卡住。Calvin 为了避免卡在 disk 上,会在 Sequencer 收到请求时预测需要的数据并预热,还会 delay 发送请求给 Scheduler。
论文的目标就是为了避免 2PC,因为在 2PC 过程中持有的锁不能释放,这会严重影响数据库的吞吐。采用 2PC 或者说锁不能执行完就释放的原因是不知道其他节点是否能成功执行,失败的原因有机器宕掉、违反事务隔离级别导致 abort 掉等。机器宕掉不应该导致 2PC 失败,搞成多副本高可用就能解决,但事务自己 abort 掉那就无法控制了,除非能提前知道其他节点执行的结果。现在的分布式数据库大都是按照 partition 来复制数据和执行请求,各个 partition 的执行结果互不知道,所以就需要 2PC,锁的存在时间也比较长:复制的耗时 + 2PC 耗时。Calvin 的思考角度不太一样,数据还是划分为 partition,也是按 partition 来复制,但复制的 transaction inputs 是面向所有 partition 的,所有 partition 的单个副本构成了状态机。使用确定性的 lock 算法保证了相同的输入能得到相同的状态,这样当 transaction inputs 提交后,每个 replica 就可以自己执行了,可以最小化锁的存在时间(没有复制和 2PC 的耗时),所有 replica 最终都会是相同的状态。
04-06 | An Empirical Evaluation of In-Memory Multi-Version Concurrency Control | 5☆
又是一篇在自研平台(Peloton)比较各种 MVCC 实现的论文,比较了 concurrency control、version storage、GC 和 index 的不同实现在不同 workload 下的性能,实现是基于纯内存数据库(越来越多的论文侧重于纯内存数据库了,毕竟硬件越来越牛逼),感觉还是什么都没说。。
现在大多数数据库都用了 MVCC,这部分的实现特别影响数据库的性能,尤其是 TiDB 这种基于 RocksDB 的 LSM-tree 的,scan 要做归并排序,如果版本特别多的话要跳过很多版本才能找到下一个有效数据,GC 来不及的话就会特别影响性能。TiKV 为了减少版本过多的影响,当 next 几次还没找到需要的数据时,会用 seek,很粗暴,效果也不好说。
04-06 | An Evaluation of Distributed Concurrency Control | 3☆
论文基于自研的平台比较了 6 种 serializable 级别的 distributed concurrency control 在典型 OLTP workload 场景下的性能,分别从读写比例、冲突程度、分布式事务涉及的 partition 数量、网络延迟等方面来比较,结论是都不太行,但是这几种协议都是自己实现的,肯定有很多可优化的地方,比较的结果不太准确。提出的解决办法有:1. 用 RDMA 之类的降低网络延迟,但对于跨数据中心场景没有办法;2. 更优的 data partition 策略,尽量将分布式事务变成单机事务;3. 使用更低的隔离级别。怎么说了和没说一样。。
03-15 | Logical Physical Clocks and Consistent Snapshots in Globally Distributed Databases | ?☆
HLC 算法很简单,就是在 physical clock 基础上使用了 logical clock 算法来保证 happened-before 关系。因为现在 TiDB 的悲观事务获取 timestamp 很频繁,我在想办法降低这部分的开销,所以更关心 HLC 如何用在 Snapshot Isolation 数据库上,这个论文里只简单提了一下,对我帮助不大,需要再研究下 cockroachdb 的事务。
03-15 | Time, Clocks, and the Ordering of Events in a Distributed System | ?☆
论文讨论了时间、时钟、事件顺序之间的关系。无法简单的用时间、时钟来确定分布式系统中事件的顺序,不同进程间的事件顺序要靠消息通信来确定,但也只能做到偏序或者说部分全序,因为不相交的事件不需要通信,也就无需确定顺序。若想要实现整个系统的全序对物理时钟有更严格的要求。
03-14 | Database Internals | 6☆
挺新的书,花了 2 周时间过了一遍,尴尬的是大部分我都懂,我不了解的看了也还是不了解。这本书更多的讲述的是「术」而不是「道」,介绍了很多问题的多种解决办法,相对而言还是更推荐 DDIA。不过这本书可以当 CMU15-445 的参考资料,第一部分几乎全覆盖了。
留下评论