Raft 笔记(二) – Basic
Raft 协议
在分布式系统中通常通过 replication 来进行容错,提高系统的可用性。这就带来另外一个问题:如何保证每个 replica 的状态一致。一致性算法(Consensus algorithm)就是为了
解决这个问题,它能够在保证在部分节点出错(非拜占庭错误)或网络分区的情况下,整个集群依然能够像单机一样提供一致的服务。
Raft 就是一种一致性算法,设计的主要目标是 understandability。它主要由下面三个子问题组成:
- Leader election
- Log replication
- Safety
Raft 基本概念
Raft 使用 quorum 实现共识和容错,只有至少 majority 的节点同意了一个 proposal,才会提交该 proposal,同时可以容忍 (n-1)/2 个节点出错。
Raft 的每个节点会处于下面三种状态之一,正常情况下只有1个 leader,其余都是 follower:
- Leader: 接收客户端请求,管理
follower - Candidate: 触发
leader election,竞选成为leader - Follower: 接收
leader或candidate的请求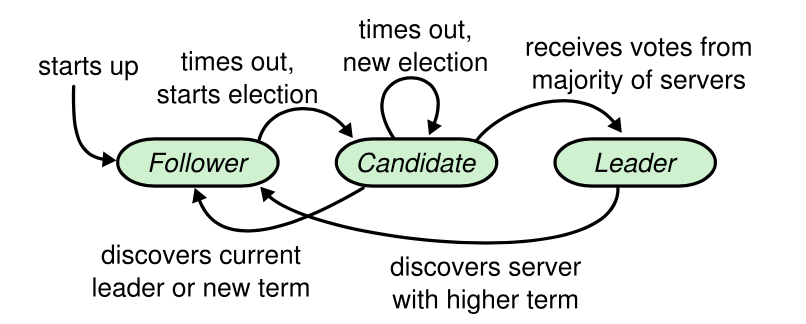
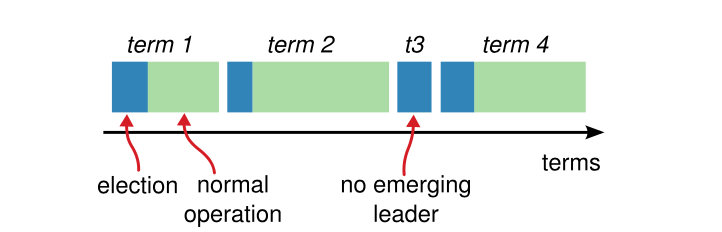
Raft 将时间划分为 term,每个 term 由单个 leader 管理,term 顺序递增,当 candidate 触发 leader election 时会增加 term。term 充当了逻辑时钟的作用,
用于检测消息和自己的状态是否 stale。
Leader Election
每个节点都有一个 election timeout,当收到合法 leader 的消息时,会重置 timeout;若超时,则触发 leader election:
- 增加
term,成为candidate - 投票给自己
- 发送
RequestVote RPC给其他所有节点
在每个 term,follower 只会给一个 candidate 投票,按照 first-come-first-served 原则,除此之外,还需要有其他的限制,防止 stale 的节点成为 leader。
若 candidate 在它竞选的 term 收到了 majority 的投票,就赢得了选举,成为这个 term 的 leader。
leader 为了维持自己的任期,会定时发送 heartbeat 给其他节点(heartbeat timeout)。需要保证 election timeout 比 heartbeat timeout 大,一般为 10 倍。
Raft 保证了每个 term 只会有一个 leader,但有可能会有多个 candidate 同时选举,导致
每个 candidate 都没有收到 majority 的投票(split vote),若 candidate 在 election timeout 中没有新的 leader 产生,则会重新进行 leader election,但这会降低系统的可用性。
为了减少这种情况的发生,Raft 使用 randomized election timeouts:每个节点在开始 leader election 时,会随机设置一个区间范围内的 election timeout。
Log Replication
Raft 使用 replicated state machines 模型,每个节点都维护自己的 log,只要各节点上按照相同顺序存储相同的命令并执行,就会得到一致的状态。
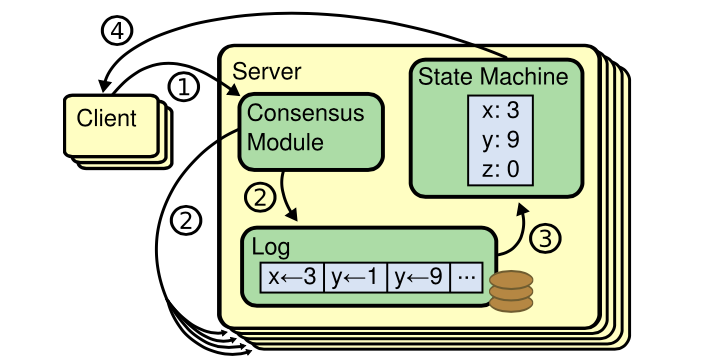
leader 接收客户端请求的流程如下:
- 将客户端请求写入本地
log,发送AppendEntries RPC给所有follower; - 若收到
majority的成功响应后,会commit该entry,apply至状态机; - 返回给客户端响应;
- 后续的
RPC都会携带leader的committed index,follower会提交本地未提交的entries。
为了保证集群内每个节点都有相同的 log,每个 entry 都有相应的 term 和 index,通过 term 和 index 唯一标记了一个 entry:
- 如果
entry含有相同的term和index,则保存着相同的command(leader从不删除entry)。 - 如果
entry含有相同的term和index,则之前的log entries都相同(通过数学归纳法证明)。
现在仔细来看一下 log replication 的过程,leader 保存了每个 follower 的状态:
- next: 下一条发送的
entry的index(初值为leader last log index + 1)。 - match: 已经复制的最大的
log index,用于更新commmit index(初值为0)。
leader 发送 AppendEntries RPC 时会携带前一条 entry 的 term 和 index,follower 会判断是否一致:
- 若一致,则表明
log是相同的,可以进行append。若follower的log中有冲突的,会进行truncate; - 若不一致,则拒绝该
RPC,leader会回退next重发RPC,直到log成功匹配。这里有多种回退策略:- 最简单的,每次拒绝时
next--,总会对的上,这种策略比较慢,一次只回退一个entry。 follower返回冲突的entry的term,和该term的第一条entry的index,这样每个term只需要一次RPC。leader根据自己log采取不同的措施:- 若
leader有该term的log entries,回退next为leader最后一条该term的entry的index; - 没有,则回退
next为follower返回的第一条entry的index。
- 若
- 最简单的,每次拒绝时
- 还有可能
follower没有该index的entry,follower告诉leader自己log最后一条entry的index,之后leader回退next到该index。
当 AppendEntries RPC 成功时,leader 会更新 next、match,并根据 majority 的 match 更新 committed index,应用到状态机。
Safety
上面两个子问题仍然有些问题没有解决,需要增加一些限制条件:
- 新选举出的
leader必须拥有之前所有已经commit的entries。 - 已经被
commit的entry不能被覆盖。
Election restriction
candidate 发送 RequestVote RPC 时会携带自己最后一条 entry 的 term 和 index,节点只会投票给 log 比自己新的 candidate,判断条件如下:
(candidate.lastTerm > me.lastTerm) || (candidate.lastTerm == me.lastTerm && candidate.lastIndex >= me.lastIndex)
这不仅保证了新的 leader 拥有所有已经被 commit 的 entries,而且也是所有 candidate 中 log 较新的。
Committing entries from previous terms
因为上面的 election restriction 比较的是 log 的新旧,并没有比较 committed index,有可能导致已经被 commit 的 entry 被覆盖:
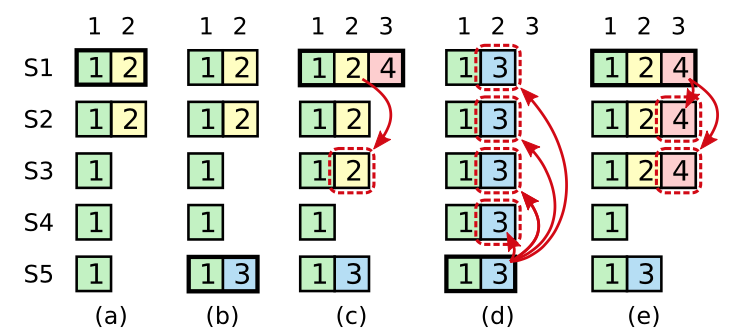
看一下上图的情景:
S1是leader;S1崩溃,S5收到S3/S4的投票成为leader,并在本地log新增了term为 3 的entry;S5崩溃,S1收到S2/S3/S4的投票成为leader,并将entry2复制到majority并提交;S1崩溃,S3收到S2/S3/S4的投票成为leader,并提交term为 3 的entry2,覆盖了之前提交的entry2。
为了解决这个问题,Raft 不会 commit 之前 term 的 entry,只会 commit 当前 term 的 entry,当前的 entry 被 commit 后,之前所有的 entry 也
都被间接 commit 了。再来看一下(e)的情形,S1 提交了 term4 的 entry,entry2 也被间接提交了,S5 就不会再被选举为 leader。
留下评论