备忘
从大三开学(2015.9)开始学习编程,觉得有必要记录一下学习经历,也能系统的复习一下学过的东西,所以就写了这个东西。本来打算弄个博客的,不过觉得GitHub是个不错的选择,比较常用,也方便,就学习了一下Markdown语法开始行动了。
学习经历
我是东南大学电子科学与技术专业的学生,第一次接触编程是在大一,学院开了一门C++的课。上学期成绩一般般考了80+,下学期上了两次课之后,就再也没去上过了,听不懂,唯一的印象就是老师在那一直念PPT,说面向对象什么的,当时对面向对象也没什么概念。宿舍里有3个人下学期的C++课都不去上,也不去上机,在考试前一周,我们一直在看C++,当时我没有看教材,看的是谭浩强的书,后来才知道谭浩强的书很坑,但这也是我们老师推荐的书。最后成绩还不错,还是80+,当时我们班里25个人挂了12个。后来在短学期的时候有一门MFC设计的课,老师什么也不讲让我们自己做东西,在网上找了个东西糊弄过去了,之后就基本上没再接触过编程。
之后是在知乎上了解到了编程,对我影响最大的是萧井陌萧大,看了他很多回答,当然还有编程入门指南。因为对本专业兴趣不大,感觉也没学到什么东西(不是因为我不学,我成绩还不错,大二基本上都90+,除了马原之类的课),就决定试一下编程,到现在发现编程的确是非常适合我的,我也很有兴趣。从大三开学几周后开始,上课就再也不听课了,看自己的书,有时候也会被老师问一下,就实话实说了,老师们也没什么意见,考试就在考前两三天里面突击一下,我的学习能力还不错,考试没什么问题,基本上都是80+。
学编程最初的路线是跟着编程入门指南走的,先买了《编码的奥秘》,然后买了《计算机程序的构造与解释》、《C程序设计语言》、《深入理解计算机系统》还有《算法导论》,还有一些Python的书,像《Python核心编程》,还有《Flask Web开发》。后面两本书也是因为看了萧大的一篇回答买的,当时花了大概一个月时间在这上面,从现在看来是得不偿失的,不是说萧大说的不好,只是不适合我,我不着急找工作,还有时间来补充基础知识,在开始的时候我也走了不少弯路。
最开始的我太急于求成了,以为把书看完了,书里的东西就是我的了,很多东西也没有在电脑上尝试。我在一个月的时间内看完了《SICP》、《TCPL》和《CSAPP》,看完了却发现剩下的没有多少。后面我就去学习Python了,《Python核心编程》也是,很快的看完了,亲自动手操作不多,还有《Flask Web开发》。学Flask的时候,也在网上学了一遍HTML和CSS,跟着搭了一个博客,虽然搭出来了,但是它的原理我一窍不通,不知道为什么一个@decorator就能让你登上网页,不知道程序为什么要这样写。这时候的我是非常迷茫的,感觉到编程很难,学了那么多东西,花了一两个月时间,却没有收获到什么,感觉自己像是空中楼阁,没有一点根基。后来就决定踏踏实实的补充基础知识,认认真真的看了《SICP》前三章,题目基本上每题都做了,遗憾的是,后来决定只装Linux的时候,把做的习题答案给弄丢了,这本书很有意思,后面两章难度比较有难度,没有再看下去,以后再看。之后是《CSAPP》,课后习题和lab也基本都做了,除了第四章的HDL没有做,lab很有意思,经常要花上一两天时间解决一个,不过做完了也很有成就感,一些答案放在了GitHub上,这本书很好,十分推荐。之后就去看《算法导论》了,不过看了一部分后决定以后再看,我决定先深入一方面再扩宽知识面。就这样大三上学期就结束了。
大三寒假的时候,又买了《Linux/UNIX系统编程手册》、《UNIX编程环境》和《鸟哥的Linux私房菜》。现在看来,后面两本我是不推荐的,现阶段用处不大,也不值得通读一边,当个手册现在也用不到。在等书的过程中,决定一心学习编程,就把系统改为Ubuntu单系统了,之前一直是用虚拟机的,比较卡。买《Linux/UNIX系统编程手册》还是买《UNIX环境高级编程》我是比较纠结的,因为这两本好像内容比较相似,评分也都不错,决定买前一本,是因为比较新。这本书很不错,既能加深《CSAPP》的很多内容,也学习了很多操作系统方面的东西,能让我更好的理解程序内部的东西。也看了一下《UNIX系统编程实践教程》,有点老了,不推荐。
开学之后决定重温一下《C程序设计语言》,第一次看的时候只觉得难度很大,这次看发现了很多有用的东西,比如很多库函数、C语言的预处理替换、UNIX的系统命令还有很多数据结构与算法的东西,的确是一本宝书,不过我觉得这本书不适合入门,一是有点老,二是难度大。后来又看了《C和指针》、《C专家编程》和《C陷阱与缺陷》,也就是传说中的C语言进阶三剑客,看的时候发现很多都已经知道了,所以看的很快,也发现了《C和指针》来入门C语言是个不错的选择,可以搭配《C程序设计语言》一起学习。后来在当当活动的时候买了《TCP/IP详解 卷1协议》和《UNIX网络编程 卷1》。第一本买的是英文书第二版,可能是书看的多了,有点膨胀,以为买英文原版没问题,结果发现这本书太厚了,太详细了,细节太多了,不适合现在的我。我硬撑着配合中文版第一版的pdf看完了,还是第一版比较适合入门,没有那么多的细节。之后就去看《UNP》了,这是本操作性很强的书,需要多动手练习,很多细节需要自己体会。学习的顺序有些问题,在看TCP/IP协议的时候,很多东西不能理解它的用处,在学习了网络编程之后,回头再看才有所体会。之后写了两个小程序放在了GitHub,一个是实现了管道和重定向的shell,一个是简单的键值对网络数据库,都不长,前一个1000多行,第二个不到3000行。这是我第一次尝试写那么大的程序,但是没有遇到什么问题,大概都花了不到1周时间完成的。本来还打算写一个http服务器的,也看了一遍《图解http》,后来感觉时间不太够用,就不准备写了,因为后面还有好多需要学习,大四上也要秋招了,我也比较想去实习。决定写这个的时候,我又借了几本书:《现代操作系统》、《高级TCP/IP编程》还有《UNIX编程艺术》,真是学海无涯,回头是岸啊。
之后的计划是看完借的几本书,写完这个,然后把《算法导论》搞定,不一定要全部看完,因为内容比较多,难度也大,应该需要花2个月时间。之后就转向别的语言学习,还有刷LeetCode,感觉C语言的校招市场比较小,后面的选择有两个:C++和Python,我是比较纠结的,都是我挺喜欢的语言。如果学C++的话,会花费比较长的时间,可能需要到大四下春招,甚至大学毕业才能入门,怕时间来不及,不过许多大厂都是对C++有要求的;而学Python的话可以早一点实习,南京也有不错的公司扇贝,我也挺想去试试的。当然语言什么的肯定都得学,只是现在时间不等人。
学习编程到现在也有8个月时间了(2015.9-2016.5),也有了一些心得。
-
学好
英语,英语好事半功倍,不管是看文档还是看原版书籍还是上公开课。 -
要
选好书,然后要踏踏实实的学习。我因为不明白这个走了几个月的弯路,浪费了几个月的时间。 -
多练习。有句话我很赞同编程是门手艺,需要多写、多练。尤其是开始的时候,一定要多写,光看是没有用的。迭代学习法比较高效,在理论和实践中迭代。 -
多思考和总结。学而不思则罔,思而不学则殆很有道理。 -
对学习的东西要有自己的判断。很多书是面向知识体系的,而不是面向读者的,书里可能有很多东西你基本不会用到,这时候就需要做出选择,掌握那最常用的,不常见的等遇到的时候再学,效率也最高。 -
专注一项。不要“并发执行”,没有那么多精力再去处理别的,不过运动不能落下。 -
要有热情和兴趣。编程是需要终生学习的,如果没有热情和兴趣,是没有办法坚持那么久的。 -
选好方向。方向有很多,前端、后端、安卓、ios等等。早点发现自己的兴趣方向。学Flask的时候,发现我对前端没什么兴趣。对Java天生就无感,ios也没钱买苹果电脑。发现自己对底层的比较感兴趣,就决定上面的路线了。不论哪个方向基础知识都是不能落下的。
如果让我重新来一遍的话,我会从C++开始。熟悉语法,看一些经典的书,像《C++ Primer》、《Effective C++》之类的,第二项就开始学算法和数据结构,我认为写算法能很快提升代码量,尽快熟练编程语言的语法,而且算法不需要特定的计算机基础知识,有些数学和逻辑能力就可以直接开始,是个很好的选择。之后再学习其余的像操作系统、网络、编译原理之类的。毕竟算法非常重要,每个方向都得学一下。不常有人说这句话吗:
程序 = 算法 + 数据结构
起步比较晚,还有很多需要学习的地方,加油!
编程语言
工欲善其事必先利其器
对于程序员来说,编程语言就是手里的武器。虽然很多更重要的是编程语言之外的东西,但熟练掌握一门或几门语言能提升效率,不同的语言擅长的领域也不同。
C
C语言语法不是非常复杂,下面是一些小经验:
自增自减
C语言的操作顺序由运算顺序和优先节决定,并且满足“贪心”规则,尽可能多的将有效操作符组合在一起。单独的前++和后++是相同的,都是将变量的值加1,要注意这不是原子操作。在语句中或函数参数中,使用前置运算符和后置是不同的,前置先变化变量的值,然后使用变化后的值;后置先使用变量的值,之后在改变变量的值。
左值和右值
左值是可以出现在赋值符号左边的东西,右值是可以出现在赋值符号右边的东西。作为左值,需要的是一个存储数据的空间的地址,因为需要将等号右边的值存储在内存中。作为右值,需要的是值。左值必须具有右值所有的限定符,才可以进行赋值。
数据、数据类型和强制类型转换
数据在内存都是以0或1的形式储存的。数据类型一方面决定了数据的存储方式,另一方面也指定了数据的解释方式。C语言是静态弱类型语言(静态:编译时发现类型错误;弱类型:容忍隐式类型转换),允许强制类型转换,也允许部分隐式转换,类型转换改变了数据的解释方式,但是不会改变数据在内存的存在形式。不过也有例外,float和double由于存储的特殊性(例如,IEEE浮点表示),不是单纯的改变解释方式。
无符号数、有符号数和溢出
无符号数在内存里以原码形式存储,有符号数以补码形式存储,这导致了相同字节长度的数据代表了不同的范围。当有符号数和无符号数一起操作时,会隐式地将有符号数强制类型转换为无符号数,最常见的问题出在关系运算符中,比如-1 < 0u将为假。当转换的数据类型有不同的字节长度时,会先改变大小,再改变符号位。由于数据字节长度有限,要注意大数相加或减法溢出的情况。
指针
指针和内存息息相关,所有的指针类型都占8个字节的长度。所有的指针都可以转换为通用指针void *型,当使用时,void *需要转换为特定的类型,因为计算机不知道如何解释void类型。指针类型在内存中存放的值是变量的地址,当使用间接访问*时,可以取出该地值的值。当然也可以对指针类型取地址&,毕竟指针类型也只不过是一种数据类型,存放的值比较特殊而已。指针的加减运算会根据数据类型的大小自动调整。
NULL为空指针,常被设为0或(void *) 0,标准规定在需要指针的上下文中发现0,视为空指针NULL。在有些情况下需要强制转换,类似在exec()中使用(char *) NULL作为变量结尾,因为可变参数需要类型来得到下一个参数,NULL需要与前面的参数类型保持一致。
指针的声明和使用
C语言要求声明和使用的方式尽可能的相似,了解了这一点,复杂的指针声明就不在话下了。
举个例子,void (*signal(int sig, void (*handler)(int)))(int)这是信号设置函数。首先分析void (*handler)(int),右边整体是一个void类型,*handler是一个以int类型为参数的函数,所以handler是返回void的以int类型为参数的函数指针。同样,signal返回的是和handler类型相同的函数指针,所以signal是以int型和一个函数指针为变量的函数,返回的是和变量的函数指针相同类型的函数指针,该函数指针以int型为变量,返回void。
要注意运算符操作顺序,int *func()是返回int型指针的函数,因为()优先级高;int (*func)()是返回int型的函数指针。
常量指针和指针常量
常量指针是指向常量的指针,指针可以指向别的东西,但不能通过指针修改常量的值; 指针常量是指向固定地址的常量,不能修改指针的指向,但能修改指针指向的地址的值。
字符串、字符串常量和字符串数组
在C语言中,字符以ascii码的形式在内存中存储,每个符号占一个字节。字符串由一系列字符组成,以空字符\0'结尾(值为0),在c语言中遇到空字符就意味到了结尾,不管后面是否还有内容,可以利用这个来分割字符串。C语言不允许源代码中一个字符串跨越多行,即到达行尾时仍在某个字符串内部就报错(这里的换行不是\n转义字符,而是回车),可以使用字符串连接解决。
char *ptr = "Hello world!"字符串的值是字符串的起始地址,将这个值赋值给ptr,字符串的值存储在只读存储区.rodata,无法修改字符串的值,这是一个常量指针。甚至可以用字符串和整数相加,得到的值是字符串起始地址之后的地址。
char buf[] = "Hello world!"是字符数组,字符串的值存储在数组中,可以修改。
数组和数组名
数组和指针是不同的,数组为数据分配了空间,指针只是为保存地址分配了空间。数组名是一个常量,值为数组首元素的地址,可以将数组名赋值给指针,不能修改数组名,不是变量,在内存中没有空间存放数组名的值,所以即使&数组名得到的还是数组的起始地址。数组的下标访问其实是通过指针访问的,可以使用数组最后一个元素的下一个元素的地址,但不能使用它的空间,也不可使用数组之前的。
数组分配
一般来说数组大小是固定的,也可以使用malloc()动态分配数组空间。C99支持变长数组,以变量作为栈数组大小,所以可以使用函数传递的参数来分配数组,如int a[n];。
数组初始化
有两种方式进行初始化,一种是长度未知int a[] = {0};会根据初始化元素个数确定数组大小;一种是长度固定,会按照顺序进行赋值,长度不够的补0,所以int a[100] = {0};就将数组初始化为0了。要注意变长数组不能初始化,无法确定数组长度。
多维数组
可以将多维数组视为一维向量,其中的元素还是数组。多维数组需要指定后面的维数,因为需要使用维数来计算元素的偏移量。
静态分配的数组按行主序在内存中分配,同一行的元素占据相邻的内存位置。动态分配类似前面的间接向量,将所有的多维数组降价成向量集合。
函数和函数指针
函数的参数为传值调用,也只有传值调用,没有所谓的传址调用,是将参数的值复制到函数内部的变量上。想要修改实参的值,需要使用指针,函数能够修改实参的值是因为指针的值是实参的地址,修改地址中的数据也就修改了实参的值。
调用函数其实是切换到函数命令的起始地址。当时用函数时,总是将函数名退化为函数指针,用来指定函数在内存中的命令。对于函数名func,(&func)()、(*func)()和func()是一样的。对于函数指针func_ptr,func_ptr()和(*func_ptr)()是一样的。
函数参数的数组和指针
函数参数传递指针有两种方式:*和[],这两种方式是一样的。当传递给函数时,一维数组和指针是一样的,数组名会退化为指针。当传递多维数组给函数时,需要指定后面的长度,以便为地址运算计算元素的偏移量。动态分配的只要传递指针即可,因为都作为向量处理。
结构体
结构体提供了一层封装,将数据组合在一起,甚至可以用函数指针和void *指针来模拟面向对象。结构体可以自引用,即内部结构包含自身,但只能是自身的指针,因为指针的大小是固定的,而未定义完全一个结构体无法知道该结构体的大小。要注意结构体的相互包含现象,需要在之前提前声明,当然也只能包含指针。
struct B;
struct A {
struct B *ptr;
/* ... */
};
struct B {
struct A *ptr;
/* ... */
};
结构体内部为了内存对齐会有填充的空位,有这两个原则:
-
每个成员的起始地址必须是该成员字节数的整数倍。
-
整个结构体在内存中占的字节数是最大成员字节数的整数倍。
-
如果结构体中包含成员结构体,该成员结构体的起始地址为其内部最大成员字节数的整数倍,整个结构体所占的字节数为成员结构体和结构体中最大成员字节数的整数倍。
内存对齐是为了提高CPU的效率,以空间换时间,保证了一个基本数据类型能够存储在一个存储器中,也就只需要一次存储器访问就能获得数据,如果不对齐可能需要多次访问,甚至导致SSE异常。
C99有一种新特性:柔性数组,是以一个空数组结尾的结构体但不能只有空数组,该数组“不占据空间”,sizeof(struct)会返回柔性数组的偏移,但不能sizeof(柔性数组)。如果给结构体在堆上动态分配了多余的空间,后面的空间会以该类型解释。举个例子:
struct test {
int count;
int buf[]; // GNU C 允许长度为0数组,C90需要长度为1,为了可移植性可以使用offsetof(test, buf)获取偏移。
};
struct test *ptr;
ptr = malloc(sizeof(struct test) + n * sizeof(int));
/* 这时buf可以当做是包含n个元素的整型数组 */
当包含柔性数组的结构体是全局变量或静态局部变量时,可以初始化柔性数组元素,类似不包含长度的数组初始化。如果是自动变量,只能分配堆空间使用柔性数组。
联合
联合使得一个变量可以合法地保存多重数据类型中任何一种类型的对象,空间为类型中最大的,只能以第一种类型的值初始化。联合提供了一种bitcast的方式,可以方便的进行类型转换而不改变二进制结构。
匿名结构体和匿名联合
GNU C和C11提供了这种机制:在结构体中声明联合体或结构体时不包含tag和变量名就可以直接使用联合或结构中的成员。
struct anonymous_struct {
struct {
int a;
int b;
};
union {
int c;
char d;
};
} test = { { 1, 2 }, 3 };
/* test.a == 1;
test.b == 2;
test.c == test.d == 3;
*/
全局变量和局部变量(自动变量)
全局变量在函数外部定义,在程序执行之前创建。如果没有显示初始化,会被初始化为0。已初始化的全局变量存放在.data段,未初始化的存放在.bss段。
局部变量或自动变量是在函数内部定义的变量,无法确定没有进行赋值的自动变量的值,也就是说不会被初始化为0。局部变量在函数执行时被创建,函数执行完毕被销毁。局部变量存放在栈中,随着函数调用的结束,该地址内存就无效了,所以不能返回指向函数内部自动变量的指针。
非局部变量(全局变量或静态变量)只能使用常量初始化,包括数字、字符串或地址(全局变量的或者函数的地址)。
static
static有两个作用:
-
在函数内部使用
static声明的自动变量是静态变量,和全局变量类似,会被初始化为0,已显示初始化的存放在.data段,为初始化的存放在.bss段。静态变量在程序整个执行期间都存在,只初始化一次,变量的值在函数调用中保持延续性。形参不能声明为静态变量,因为形参必须分配在栈内,来支持递归调用。 -
限定作用域:使用
static声明的函数和全局变量只在本文件内可见,通常用于辅助头文件接口的实现,外部不可见。
extern
extern多用在头文件中,用于声明变量和函数是在外部定义的的,不会为该变量分配空间。要注意声明要和定义相匹配,指针和数组在这种情况是不同的,因为内存使用方式不同,通常用于在头文件中声明全局变量和函数,然后在.c中定义,如果在头文件中定义可能会发生重定义。
内联函数(inline)
C99中增加了内联函数的标准,不过很多编译器在这之前已经支持内联函数这一特性了,编译器和标准的实现会有些差异。在函数定义中使用inline关键字就会建议编译器在调用该函数时将该函数展开,省掉函数调用的开销(压栈、跳转、返回等)。
The point of making a function inline is to hint to the compiler that it is worth making some form of extra effort to call the function faster than it would otherwise - generally by substituting the code of the function into its caller. As well as eliminating the need for a call and return sequence, it might allow the compiler to perform certain optimizations between the bodies of both functions.
Sometimes it is necessary for the compiler to emit a stand-alone copy of the object code for a function even though it is an inline function - for instance if it is necessary to take the address of the function, or if it can’t be inlined in some particular context, or (perhaps) if optimization has been turned off. (And of course, if you use a compiler that doesn’t understand inline, you’ll need a stand-alone copy of the object code so that all the calls actually work at all.)
inline常与static一起使用:static inline。函数调用想要内联,函数定义需要在相同的翻译单元(translation unit,经过预处理之后的.c源文件)内,因为编译是是按翻译单元为单位分离编译的,
如果只有函数的声明,那么在链接过程中就会像普通函数一样,确定它的地址再进行调用,不会内联展开。而当头文件的接口需要内联时,不能直接在头文件中定义inline函数,当多个文件同时包含这个头文件
时就会出现重定义错误,所以需要在头文件中使用static inline,每个包含这个头文件的源文件有自身的副本,互不可见。
const
const用于定义常量类型,只能在定义时对它进行初始化,不能修改它的值,const修饰的是紧贴在它后面的类型。
要注意用const来修饰指针:
-
char *const p:修饰p,p是指向字符的指针常量,字符可以变,指针不可以变。 -
char const *p和const char *p:前面的是修饰*p,后面的是修饰char,都是字符类型。p是指向字符常量的指针,也就是常量指针。p可以变,但不可以通过p修改内容,可以通过其它的变量指针来修改值,所以p指向的内容也就变了。
当然还有两个都是常量的情况,都不可以改变。const修饰的常量也是可以修改的,但必须通过别的指向相同地址的指针,如果将常量赋值给其余变量时缺少const会有warning。最常见的是在函数形参中指定const char *ptr,防止在函数内部修改值。
volatile
中文翻译为易变的,作用是防止编译器对访问该变量的代码进行优化,也就是防止编译器将变量优化到寄存器中,以后每次读取改变量都会从内存中读取,也就保证了变量的变化会实时的反应。
sizeof()
sizeof()不是函数,是一个运算符,在编译期时求一个类型或是一个表达式的类型的长度,然后使用该常量替换原有的sizeof()语句。
sizeof(表达式)中的表达式不会被求值,只需要知道表达式的类型来获取长度。即使指针p为空,也可以使用sizeof(*p)获取长度,因为*p不求值,只需要知道它的类型。
sizeof(数组)会得到数组的空间大小。字符串会被视为数组,包括最后的空字符。由于sizeof是一个编译时运算符,因此该计算只适用于在编译时大小已知的数组。
sizeof(指针)会得到指针的大小。要注意一点,不可以通过sizeof()获取函数参数数组的大小,因为当数组进行参数传递时,会退化为指针,大小固定。
sizeof(结构体)会包含填充空间的大小,需要确定元素的偏移或大小可以使用:
#include <stddef.h>
size_t offsetof(type, member);
宏#define
宏在预处理阶段会被替换为相应的语句,却又不是简单的替换。宏有下面几个特点:
-
__LINE__为整型,值为当前文件行数;__FILE__为字符串,值为当前文件名。 -
无类型,甚至可以将类型作为宏的参数。
-
宏定义时,参数要用
()包围。C99支持可变参数宏,类似可变参数函数,最后一个参数为...,使用__VA_ARGS__传递,为了预防没有参数的情况,需要使用##__VA_ARGS__,否则是语法错误。 -
因为是语句替换,可能会出现副作用,尤其是出现自增自减情况。
-
不要用宏来进行类型定义。不能处理指针的情况。
-
#用于将参数字符串化,替换为值为实际参数变量名的字符串。##用于连接参数组合成一个token。要注意预处理是在词法分析做完之后实施的,词法分析后的结构是一个个的token,比如#define OP +, 当使用OP=时,会被展开成* =为2个token,可以使用#define OP(o) *##o, 这时会将OP(=)视为一个token。 -
多行语句要用
do {} while (0)包裹成单个语句,续行用\,目的为了防止破坏if结构,可能会导致else不匹配:
#define M() do { a(); b(); } while (0)
/* #define M() a(); b()
or #define M() { a(); b(); }
*/
if (cond)
M();
// do { a(); b(); } while (0);
/* a(); b();
{ a(); b() }; 都导致else缺少对应if
*/
else
c();
typedef
typedef用来给数据类型定义新的名字,定义的方式和普通变量定义相同,新名字在变量名的位置出现,只是在前面增加了typedef,可以用来降低类型的复杂度和可移植性。typedef是由编译器解释的,文本替换功能超过预处理器。C语言编译器支持用typedef给尚未定义的类型起别名,且可以指向同名结构。
要注意新类型和const一起使用的情况:typedef将原有数据类型打包到一个新的类型中,typedef int *int_p,const int_p p为常量指针,而不是const int *p这样的指针常量。
有种用法叫做不透明指针,可以在.h中只给出typedef struct a *a,在.c文件中定义struct a {...};。这也就隐藏了结构体的内容,程序包含该头文件只能使用该结构体的指针,不能反引用即不能查看指针指向结构的内部信息。
命名空间
如果有一个标识符(identifier)有多个声明在翻译单元中是可见的,会使用命名空间来区分不同的实体。
命名空间用于在相同作用域中区分相同的标识符:
-
在相同的作用域内,可以在不同的命名空间中使用相同的标识符名称。否则,编译器会报错重复定义。
-
不同的作用域互不影响各自的命名空间。比如不同的程序块结构和不同的函数中(其实函数也就是程序块结构)。
-
在嵌套的作用域中,当出现内部和外部标识符名称相同的情况下,且都属于同一个命名空间,那么内部的会隐藏外部的标识符。比如函数中的变量会隐藏全局变量,函数中的代码块隐藏外部的函数局部变量。
C语言标准定义了4种命名空间:
-
label names (goto)
-
the tags of structures, unions, and enumerations(diambiguated by following any of the keywords struct, union, or enum)
-
the members of structures or unions; each structure or union has a seperate name space for its members
-
all other identifiers, called ordinary indentifiers(变量名、函数名、typedef定义的类型名、enum成员、宏定义)
要注意宏定义,如果出现标识符重名,宏定义会覆盖所有其它标识符,无所谓作用域和命名空间,因为宏在预处理阶段就替换了。
声明、定义和作用域
名字的作用域指的是程序中可以使用该名字的部分。变量和函数都要需要先定义或声明再使用,变量或函数的作用域从声明或定义它的地方开始(和Python不同,Python只要能找到就行,顺序无关):
-
变量声明只适用于全局变量,需要用
extern(否则就是定义,会建立变量并分配空间),用于说明变量的属性,即类型,不会为变量分配空间。 -
函数声明不需要
extern,但也可以显示使用说明是在别的模块中定义的,函数声明一般需要指明函数返回类型和参数类型(参数名无所谓)。如果没有函数声明,则函数将在第一次出现的表达式中被隐式声明为返回int型,且对参数不做任何假设,传参时也会关闭所有参数检查,和声明函数时使用()效果一样,所以无参数时需要使用void进行声明。 -
C语言采用程序块结构,在
{}中可以定义变量,变量的作用域为左右花括号之间,且会隐藏程序块之外的同名变量,也可以使用static定义,只进行一次初始化,函数参数属于函数程序块结构。
声明和定义必须一致(包括类型和链接属性,所以内部变量无法声明,声明具有外部链接属性extern),声明和定义顺序无所谓。可以有多个相同的声明,但只能有一个定义。如果在同一源文件中声明和定义不一致,编译器会报错。但如果是单独编译的,这种不匹配就无法检测,最后的结果和链接有关,是无意义的。
头文件
预处理器会将#include包含的头文件替换为相应的文件内容。以""包围的搜索范围是先在当前文件内,支持相对位置的包含,比如使用. .. /等,之后按照特定的路径寻找。以<>包围的搜索范围为系统设置的路径。可以设置C_INCLUDE_PATH环境变量来增加搜索路径。通常会采用条件编译的方式,避免重复包含头文件。
头文件中应该只有声明没有定义。要注意头文件的相互包含问题,需要去掉其中一个的头文件,使用提前声明。
操作系统
操作系统是一种运行在内核态的软件。它的一个功能是为上层应用程序提供抽象一致的接口,另外一个功能是管理硬件资源。操作系统通过几个基本的抽象概念来实现这两个功能:文件是对I/O设备的抽象;虚拟存储器是对主存和磁盘I/O设备的抽象;进程则是对处理器、主存和I/O设备的抽象。抽象降低了系统的复杂度,使我们免于遭受底层细节的困扰。
系统调用
系统调用是受控的内核入口,借助系统调用,进程可以访问系统资源去执行某些动作。系统调用包装函数通过执行一条中断机器指令(int 80),引发处理器从用户态切换到内核态,执行系统调用编号对应的系统调用。所有系统调用都是以原子操作方式执行的,内核保证了系统调用中的所有步骤会作为独立操作而一次性加以执行,不会被其他进程或线程或信号中断。慢速的I/O或阻塞的系统调用会被中断。从编程的角度看,系统调用和普通的函数没什么区别,但是系统调用需要做的工作更多,开销也会相对较大。系统调用出错通常会设置全局变量errno。
文件I/O
文件就是字节序列。所有的I/O设备,如网络、磁盘和终端,都被模型化为文件,而所有的输入和输出都被当做相应文件的读和写来执行。
现代操作系统的I/O大多采用直接内存存取(DMA),当发出一个I/O请求时,CPU给DMA模块下达命令,之后CPU继续其他工作,比如调度另一个进程运行,当I/O完成
后,DMA模块产生中断通知CPU。所以只有在开始传送和传送结束时CPU才会参与I/O,提高了系统的性能。
所有执行I/O操作的系统调用都以文件描述符,一个非负整数,来指代打开的文件。程序开始运行之前,就打开了前3个文件描述符用来指向标准输入、标准输出和标准错误,其实是程序继承了shell文件描述符的副本。打开新的文件会以当前可用的最小值作为文件描述符的值。
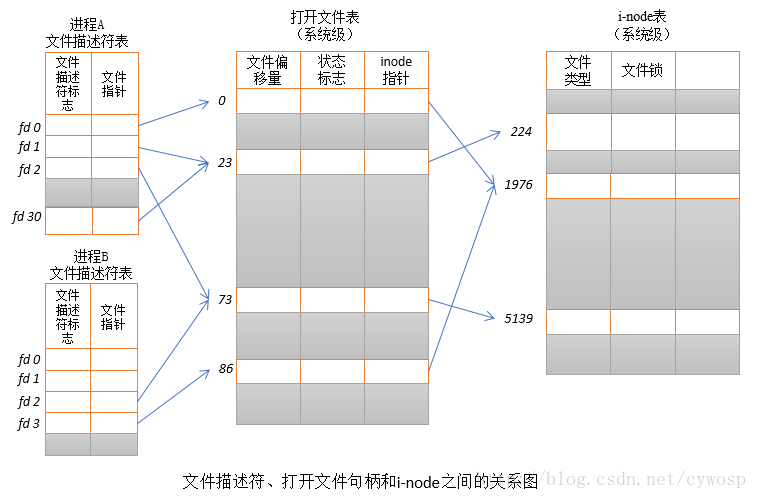
内核为文件维护了3个数据结构:
- 进程级的文件描述符表。内核为每个进程都维护了一个打开的文件描述符表,文件描述符的值就是这个结构数组的下标,结构数组中记录了该文件描述符的相关信息:
-
文件描述符标志
close-on-exec。默认情况下,该标志是关闭的,也就是当进程执行exec()启动新的程序时,之前打开的未设置该标志的文件描述符在新的进程空间内仍保持打开状态,可以通过传递命令行参数通知新的程序使用这些文件描述符。当开启该标志时,文件描述符会被关闭。 -
对打开的文件描述的引用,也就是指向打开的文件描述的指针。
- 系统级的打开的文件描述表。内核对所有打开的文件维护了该系统级的描述表格,表中各条目称为打开的文件描述。一个打开的文件描述存储了与一个打开文件相关的全部信息:
-
当前文件偏移量,调用
read()或write()更新,或使用lseek()直接修改。 -
打开文件时所使用的状态标志,除了
O_CLOEXEC标志,例如O_NONBLOCK。 -
文件访问模式,也就是读写权限。
-
与信号驱动I/O相关的设置。
-
对该文件i-node对象的引用。
- 文件系统的i-node表。每个文件系统都会为驻留其上的所有文件建立一个i-node表,表中的每个i节点对应了磁盘上一个真正的文件,它记录了文件的相关信息:
-
文件类型(普通文件、套接字等等)和访问权限。
-
一个指针,指向该文件所持有的锁的列表。
-
文件的各种属性,包括文件大小以及与不同操作相关的时间戳。
因为这三个数据结构属于不同的级别,有些是进程私有的,有些是内核级别的进程共有,所以有一些注意的情况:
-
文件描述符采用引用计数,只有计数为0时,才会关闭文件,删除打开的文件描述项,引用计数也就是目前有多少个文件描述符指向该文件描述。
-
当使用文件描述符复制时,如
dup()、dup2(),会使同一进程内的不同的文件描述符指向同一打开的文件描述,也就共享了相应的数据,但close-on-exec标志会被默认关闭。 -
当同一进程多次打开同一个文件文件时或不同进程打开相同的文件,文件描述符会指向不同的打开的文件描述,但指向相同的i结点。
-
当使用
fork()创建子进程时,子进程会获得父进程所有的文件描述符的副本,副本的创建方式类似于文件描述符复制,所以父子进程的文件描述符都指向相同的打开的文件描述。 -
当使用描述符传递时,被传递的文件描述符指向相同的打开的文件描述。
当进程的文件描述符共享打开的文件描述时,对偏移量和文件标志的操作会影响到每一个文件描述符。在进程中打开的文件,可以被删除,此时文件仍有效,直到打开该文件的进程结束。
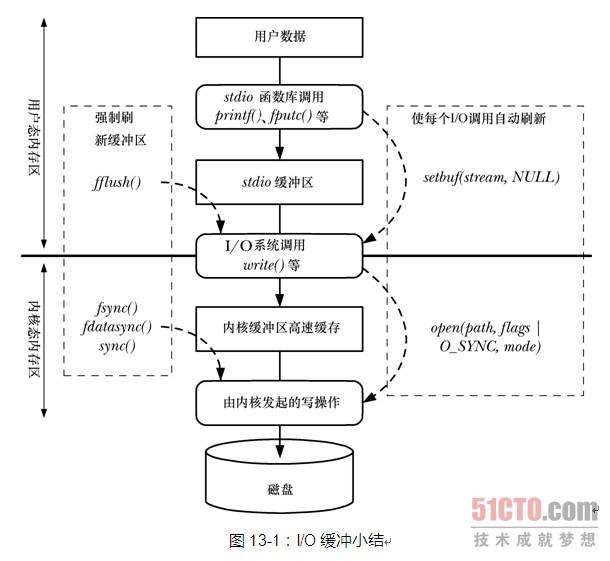
对文件进行读写主要通过系统调用read()/write()或标准I/O函数库stdio:
-
系统调用不是直接在访问磁盘上的数据,而是在用户空间缓冲区和内核缓冲区之间复制数据,等到满足某些条件,内核缓冲区才会和磁盘交互。
-
stdio库在函数内部维护了一个大块的缓冲区,用于缓冲大块数据来减少系统调用,直到满足缓冲条件才会调用系统调用。同一个流的读写缓冲区是共享的,会有一些特殊影响,输入和输出操作不能紧邻在一起,需要插入fflush()或文件定位函数。可以设置三种缓冲方式:-
无缓冲,立即调用系统调用。
stderr默认类型。 -
行缓冲,遇到换行符前将数据缓冲。指代终端设备的流默认类型。
-
全缓冲,缓冲区满才调用系统调用。其余文件默认类型。
-
编译、链接

从C源代码文件到ELF可执行目标文件之间会经历非常复杂的过程,一般会有预处理、编译、汇编和链接这几个过程。使用gcc等编译器会方便程序员进行上述步骤。
预处理:对于c代码而言,使用gcc -E可以产生预处理后的文件.i,预处理主要用来处理源代码文件中以#开始的预编译指令,主要有下面几个过程:
-
删除所有的宏定义
#define,并展开所有的宏。 -
处理条件编译指定,如
#if、#ifdef。 -
处理
#include指令,替换为相应头文件的内容,该过程是递归进行的,所以头文件一般都会指定#ifndef防止重复包含。 -
删除所有的注释。
编译:编译过程将预处理之后的文件进行词法分析、语法分析、语义分析及优化后产生相应的汇编代码文件。可以使用gcc -S产生汇编代码文件.s。
-
词法分析:使用有限状态机算法将所有的源代码字符序列分割成一系列的记号并确定类型。
-
语法分析:对产生的记号进行语法分析,生成以表达式为节点的树,在语法分析的同时,很多运算符号的优先级和含义也被确定下来了。
-
语义分析:语法分析仅完成了对表达式的语法层面的分析,但是不了解这个语句是否真正有意义。语法分析只能处理静态语义,也就是编译期间可以确定的语义。
-
中间代码生成:将语法树转换为中间代码,并进行优化。中间代码一般是顺序执行的序列,每个语句只有最基本的命令,容易生成对应的汇编代码。中间代码一般是三地址码。
前面的过程是编译器前端,负责产生机器无关的中间代码。之后的过程是编译器后端,将中间代码转换为目标机器的代码,机器往往不同,所以产生的最终代码也不相同。
- 目标代码生成和优化:将中间代码转换为对应的汇编代码,然后再优化汇编代码。
汇编:将汇编语句转换为对应的机器指令。可以使用gcc -c产生目标文件.o。目标文件(ELF)中包含机器指令代码、数据,还包含一些链接时需要的信息。目标文件将这些信息按不同的属性,以节的形式存储。有三种目标文件:
-
可重定位目标文件:需要与其他可重定位目标文件链接在一起创建一个可执行目标文件。
-
可执行目标文件:可以直接拷贝到存储器中执行。
-
共享目标文件:特殊形式的可重定位目标文件,可以在装载或运行时动态地装载到存储器中链接。
目标文件中主要有这几个段:
.data:保存已经初始化了的全局变量和局部静态变量。.rodata:保存了只读数据,比如const修饰的变量和字符串常量。.bss:保存了未初始化的全局变量和局部静态变量。未初始化的全局变量和局部静态变量默认为0,.bss段只为这些变量预留空间,并不分配实际的空间大小,可以节省磁盘空间。.text:保存了程序的机器代码。
链接:分离编译使得模块化开发成为可能,提高了开发效率。不同的目标文件一般总是需要引用别的目标文件中的函数或变量,链接就是将各种代码和数据部分收集起来并组合成为一个单一文件的过程。
链接有两个主要任务:
- 符号解析:目标文件定义和引用符号,符号解析将每个符号的引用刚好和一个符号定义联系起来。解析有下面几个规则,其中函数和已初始化的全局变量是强符号,未初始化的全局变量是弱符号:
- 不允许强符号对多次定义。
- 如果一个符号在某个目标文件中是强符号,在其他文件中都是弱符号,选择强符号。
- 如果一个符号在所有的目标文件中都是弱符号,那么选择占用空间最大的哪个。
- 重定位:编译器和汇编器生成地址从0开始的代码和数据段。链接器通过将每个符号定义和一个虚拟地址联系起来,并使符号的引用指向这些地址,从而重定位这些段。
链接可以执行于编译时,叫做静态连接;可以执行于装载时,叫做动态链接;可以执行于运行时,叫做显式运行时链接:
- 静态链接:静态链接器(ld)以一组可重定位目标文件作为输入,将所有文件的相似段合并,比如所有输入文件的
.text合并到输出文件的.text。- 一组相关的目标模块打包成一个单独的库文件,称为静态库,也叫存档文件(.a),可以方便的用作链接器的输入,链接器只拷贝被引用到的目标模块。
- 静态链接,比如使用静态库,会使可执行目标文件包含所有被链接进程序的目标文件的副本。当有多个可执行目标文件使用了同样的目标模块时,每个文件都拥有独立的副本,造成了磁盘空间的浪费,同时每个进程都会独立地加载目标模块,造成了主存和虚拟内存的浪费。
- 如果需要修改静态库中的模块,需要所有使用该模块的可执行目标文件都必须要重新链接并合并这个变更。
- 动态链接:动态链接用来解决静态链接的问题。静态链接是在装载前链接,动态链接是在装载的时候进行链接,在运行时进行符号解析和重定位。
- 首先需要生成共享库,使用
gcc -fPIC -shared可以生成共享目标对象。-shared产生共享对象,-fPIC生成地址无关的代码。 - 使用共享库并不只有动态链接,也会将共享库的一些重定位和符号表信息静态链接到可执行目标文件中,但并不会拷贝其余的代码和数据节,也就节省了磁盘空间。
- 动态链接在运行时进行符号解析和重定位,如果是第一个需要共享库中的模块的程序启动时,库的单个副本会被加载到内存,后面使用相同共享库的进程启动时,会共享相同的代码段,但变量不共享,每个进程会拥有独立的库中定义的全局和静态变量的副本,但也节省了虚拟内存。
- 需要共享代码,所以需要生成地址无关的代码,可以使得库代码在任何地址加载和执行,因为共享库在每个目标文件中的地址可能不同。
- 与静态链接程序相比,程序运行时需要多花费一定时间进行动态链接。同时PIC代码也会带来性能开销,需要使用额外的寄存器进行数据引用,延迟绑定(lazy binding)技术将函数地址的绑定推迟到第一次调用该过程时,第一次调用时开销大,之后每次调用开销就会很小。
- 目标模块并没有复制到可执行文件中,而是在共享库中维护的,所以可以无需重新链接就可以更新目标模块。
- 首先需要生成共享库,使用
- 显式运行时链接:应用程序可以在运行时要求动态链接器装载和链接任意共享库,并且可以在不需要该模块的时候将其卸载。这种方式使得程序的模块组织更灵活,可以用来实现插件、驱动等功能。需要用到的函数有:
#include <dlfcn.h>
void *dlopen(const char *filename, int flag);
void *dlsym(void *handle, char *symbol);
int dlclose(void *handle);
const char *dlerror(void);
进程、虚拟地址空间
进程是执行中的程序的实例,是由内核定义的抽象的实体,该实体分配用以执行程序的各项系统资源。进程最关键的特征是它拥有独立的虚拟地址空间,内核创建了数据结构用于维护进程状态信息,如进程ID、虚拟内存表、打开的文件描述符表、信号等等。
当需要运行可执行目标文件时,会通过调用装载器/加载器(execve)来运行它。装载器将可执行目标文件的代码和数据从磁盘拷贝到存储器中,创建虚拟地址空间,然后跳转到程序指令的入口处来运行程序:
-
首先需要创建虚拟地址空间:创建页表结构,建立虚拟地址空间到物理空间的映射关系。
-
读取可执行文件头,创建虚拟地址空间和可执行文件的映射关系。除了头部信息,加载过程中没有任何从磁盘到存储器的数据拷贝,直到CPU引用了一个被映射的虚拟页才会利用页面调度进行拷贝。
-
将CPU指令寄存器设置成可执行文件入口,启动运行:
<_start>: /* 启动代码 */
call __libc_init_first
call _init
call _atexit /* 注册终止时运行的程序 */
call main /* 调用main程序 */
call _exit /* 返回控制给操作系统 */
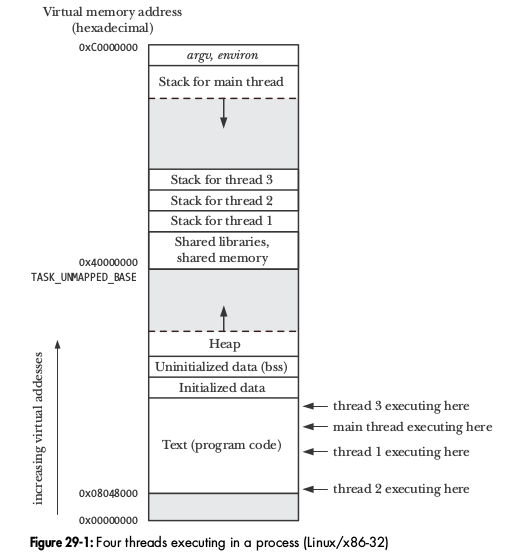
典型的Linux-32位机上的进程内存结构如图:
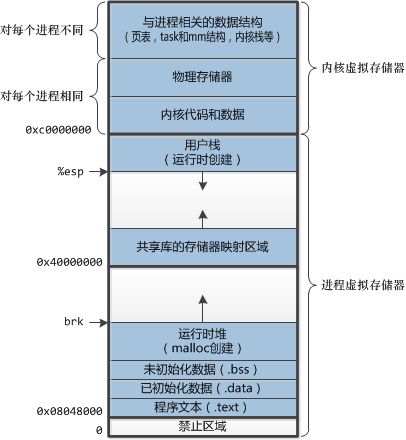
其中.data、.text、.bss等段和可执行目标文件中对应,不过.bss段中的内容在虚拟内存中分配了空间。在最上方是内核映射到进程虚拟空间的,程序无法访问。最主要的段是栈和堆:
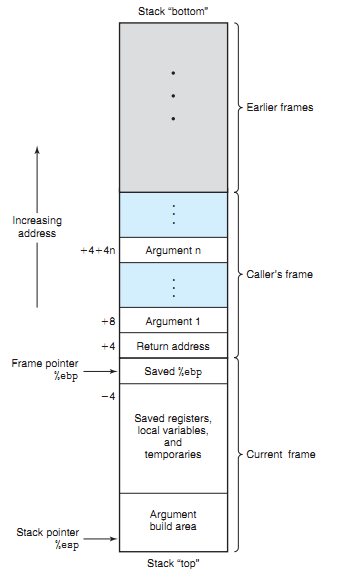
- 栈:栈是一个动态增长和收缩的段,从内存的高地址处向下增长,地址低的为栈顶。栈由栈帧组成(32位),每调用一个函数,就会在栈上新分配一帧,当函数返回时就将此帧移去。%ebp指向当前帧的起始处(高地址),不变。%esp指向栈顶(低地址),动态变化。64位去掉了帧指针,只有栈指针。
栈保存了下面信息:
-
在栈最开始的地方,也就是地址最高的地方,保存了命令行参数和系统环境变量。
-
函数实参和局部自动变量:在调用函数时自动创建,在函数返回时销毁。C语言参数从右到左进栈,参数紧密排列在栈空间,可变参数就是利用最后一个不可变参数的地址加上参数的大小来决定下一个参数的地址(va_start),同时根据参数类型获得大小读取值(va_arg)。64位中,函数参数前六个通过寄存器传递。
-
函数调用的信息:程序计数器和函数返回地址等,用于从函数调用中返回到之前状态。
- 堆:在运行时动态内存分配使用的一块区域。堆顶部叫做”program break”,可以通过
brk或sbrk来调整 。不是每次调用malloc()之类的函数都会增长堆的顶部,通常是直接增加一块内存(虚拟内存页的倍数),之后在这一大块内存中分配需要大小的内存。
有下面几个注意点:
-
动态内存分配保证字节对齐,总是适宜于高效访问任何类型的C语言数据结构,所以大多以8字节或16字节边界来分配内存。
-
当分配的空间比较小时,会按需分配多个虚拟内存页大小,然后将剩余空间的空间置于空闲内存链表中。当分配的空间大于
MMAP_THRESHOLD时,会使用mmap匿名映射进行分配。可以分配的大小取决于物理内存(RAM)大小、交换区和系统资源限制(RLIMIT_AS)也就是虚拟内存大小。 -
分配的空间实际是虚拟内存,符合虚拟空间的按需页面调度,只有当访问该页时才会进行页面调度。在Linux中,返回成功,不保证内存可用,因为只有当访问时才会发现错误,防止系统
out of memory,当系统内存耗尽时,OOM Killer会选择杀死某些进程。 -
malloc()返回的是未经初始化的内存,calloc()返回初始化为0的内存。malloc(0)在Linux上返回一小块可以用free()释放的内存。 -
realloc()用于增加或减小内存的大小,增加的部分不会进行初始化。当紧邻原内存块后面的空闲内存大小不足时,realloc()会移动内存,任何之前指向该内存块内部的指针在调用realloc()之后不再可用,需要使用起始地址+偏移量来操作。realloc(ptr, 0)等效于free(ptr)+malloc(0),而realloc(NULL, size)等效于malloc(size)。 -
堆中的内存不会被自动释放,除非当进程终止时。当没有指针指向已分配的内存时,就造成了内存泄露。所以好习惯是当不再需要该内存块时就调用
free()显示释放。 -
alloca()将从当前函数的栈帧上分配空间,分配的内存会随着栈帧的移除自动释放掉。
Linux使用虚拟地址空间来管理进程的内存结构,虚拟地址不是真正的地址,需要将虚拟地址映射为实际的物理地址。系统将进程使用的虚拟内存划分为小型的、固定大小的页,将主存划分为与虚存页相同的页帧。仅有部分页被缓存在主存的页帧中,未被缓存的保存在磁盘中。当进程需要访问的页不在主存中时,就发生了页错误,内核即刻挂起进程,从磁盘中载入该页面到主存。
内核为每个进程维护了一张页表,用来描述进程每页的实际物理地址,要么在主存中的地址,要么在磁盘上的地址。
磁盘和存储器之前传送页的活动叫页面调度。现代系统大都采用按需页面调度,只有当不命中发生时才换入页面。
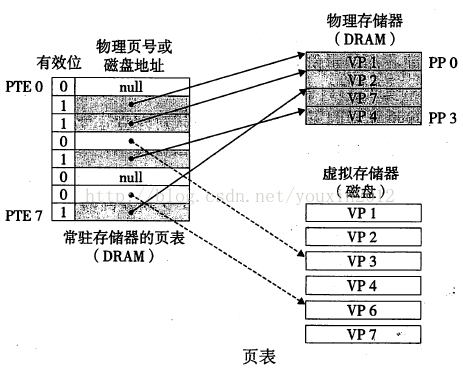
虚拟内存管理使进程的虚拟地址空间与主存物理地址空间隔离开来,有许多优点:
-
进程与进程、进程与内核相互隔离,互不影响。为每个进程提供了一致的地址空间,简化了存储器管理。
-
当不同进程的页表条目指向相同的物理地址时,就实现了内存共享。可以用来实现共享库的代码共享,实现进程间通信等等。
-
实现内存保护机制,给页表条目标记可读、可写等权限。
-
使用主存作为磁盘的缓冲,可以提高程序加载和运行的速度。磁盘的修改采用写回策略,只有当页面被置换出去后才会更新存储器。
-
进程使用的内存大小可以大于主存容量。因为只有一部分活动的需要驻留在主存中,剩下的存放在磁盘中,充分利用了主存,可以容纳的进程数量也就增多了。
-
交换空间(磁盘等)在物理内存被充满时被使用。如果系统需要更多的内存资源,内存中不活跃的页就会被移到交换空间去。交换空间位于硬盘驱动器上,比物理内存慢。
在编程的时候要注意局部性,来高效的使用CPU和主存,因为页错误的处理会比较耗时:
-
空间局部性:程序倾向于访问在最近访问过的内存地址附近的内存。
-
时间局部性:程序倾向于访问之前访问过的内存地址。
进程调度和切换
进程调度和切换由操作系统内核决定。操作系统为每个进程分配进程控制块用于进程的控制,其中包含如进程状态,进程调度信息,进程的上下文,寄存器等数据,当发生进程切换时需要保存进程 相关数据,以便在未来恢复进程的执行。
操作系统维护了多个队列来进行进程调度和切换。切换进程可以在操作系统从当前正在运行的进程中获得控制权的任何时刻发生,也就是在内核态时发生。
主要由下面几种事件引发状态切换:
-
时钟中断:分配给进程的执行时间(时间片)超时,这时会发生进程调度,可能会调度其余进程执行,具体由操作系统决定。
-
I/O中断:I/O事件完成会通知操作系统,操作系统将阻塞在相应事件的进程转为就绪态。
-
缺页异常:在磁盘和主存中进行I/O导致进程阻塞、切换。
-
陷阱:如段错误、除零错误。
-
系统调用:系统调用一般不发生进程切换,除非系统调用阻塞。
中断的产生不代表一定会发生进程切换,这和操作系统相关,进程切换涉及许多方面,如保存进程上下文、修改进程状态、进程在队列中转移、内存管理等等。
Linux有多种进程调度方法,默认的是循环时间共享,每个进程轮流使用CPU一段时间,进程优先级不起决定性影响。
还有两种来支持实时进程调度的方法:
-
SCHED_RR:按优先级顺序执行,相同优先级的进程在同一队列使用循环RR方式执行。 -
SCHED_FIFO:不存在时间片,按优先级顺序执行,相同优先级的先入先出执行。
实时进程调度使用了严格的优先级策略,可以控制进程被调用的顺序,也支持更高优先级进程的抢占。
信号
信号是事件发生时对进程的通知机制,会中断程序的正常流程,执行特定的逻辑。产生信号有两种方式,一种是软件中断,程序调用函数可以产生信号;一种是硬件中断,硬件检测到一个错误条件并通知内核,比如被零除或者引用了无法访问的内存区域。当调用函数发送信号或硬件异常时,会立即传递信号,这也是信号的同步生成。当信号的产生与进程的执行无关时,就是异步生成,异步生成产生的信号会在由内核态到用户态的下一次切换时传递给进程,比如进程时间片的开始时,系统调用完成时。
信号有两种:
-
标准信号:主要由内核产生通知进程,一般都会有默认行为。标准信号中有两个信号
SIGUSR1和SIGUSR2可以供程序员使用。当阻塞多次某个标准信号时,到进程可以接收时,只会收到一次该信号。阻塞的多个信号传递顺序没有规定,Linux按照信号编号的升序来传递信号。 -
实时信号:实时信号主要用于程序员自定义使用。实时信号采取队列化管理,当解除阻塞时,如果在阻塞期间产生了多次某信号,将会多次传递。实时信号还可以指定伴随数据给信号处理器。将优先传递值比较低的信号。
发送信号
产生信号有下面几种方式:
- 在终端键入某些字符会发送信号给前台进程组:
Ctrl+C发送SIGINT,终止进程。Ctrl+Z发送SIGTSTP,停止进程,可在之后发送SIGCONT继续运行。Ctrl+\发送SIGQUIT,终止进程并产生核心转储文件,可以使用gdb的backtrace查看进程调用栈。
-
在终端使用
kill默认发送SIGTERM终止进程。 kill(2)系统调用发送标准信号:
#include <signal.h>
int kill(pid_t pid, int sig);
pid为发送信号的目标进程,sig为要发送的信号。当pid大于0时,发送给pid指定的进程;pid等于0,发送给调用进程同组的进程;pid等于-1,发送给可以发送的任意进程,除了init进程和本身;pid小于-1,发送给进程组ID为pid绝对值的进程。当sig等于0时,可以用来检测对应PID进程是否存在。
-
raise(2)向调用进程发送信号。 -
alarm(2)计时结束后发送SIGALRM,alarm(0)会解除设置。可以用来实现系统调用的定时。 -
sigqueue(2)发送实时信号。
阻塞信号
多个信号使用一个叫做信号集的数据结构来表示,类型为sigset_t。需要使用sigemptyset(2)或sigfillset(2)进行初始化,使用sigaddset(2)或sigdelset(2)添加或删除信号。
#include <signal.h>
int sigprocmask(int how, const sigset_t *set, sigset_t *oldset);
int sigpending(sigset_t *set);
int sigsuspend(const sigset_t *mask);
#define _POISX_C_SOURCE 199309
int sigwaitinfo(const sigset_t *set, siginfo_t *info);
int sigwait(const sigset_t *set, int *sig);
sigprocmask()用来修改信号掩码和获取现有掩码。how可以是SIG_BLOCK将信号集加入到信号掩码中,SIG_UNBLOCK移除,SIG_SETMASK设置。只获取掩码可以设置set为NULL,将忽略how参数。
sigpending()用来获取阻塞中的信号,可以使用sigismember()检查set。
sigsuspend()挂起进程,更改信号掩码并等待信号的到来,需要设置信号处理程序,相当于原子的执行:
sigprocmask(SIG_SETMASK, &mask, &prev_mask);
pause();
sigprocmask(SIG_SETMASK, &prev_mask, NULL);
sigwaitinfo()和sigwait()挂起进程,直到set中的信号到达,不需要设置信号处理函数,在使用前需要将set中的信号阻塞,否则会丢失,当set中的信号正在等待,函数会立即返回。
信号处理函数
有两种方式设置信号处理函数,一种是使用signal(2),另一种是用sigaction(2),SIGKILL和SIGSTOP无法更改设置:
-
signal(2)主要用来设置默认操作SIG_DFL和忽略信号SIG_IGN。 -
sigaction(2)更通用也更灵活。
#include <signal.h>
int sigaction(int sig, const struct sigaction *act, struct sigaction *oldact);
struct sigaction {
/* 信号处理函数或SIG_IGN或SIG_DFL */
void (*sa_handler)(int);
/* 阻塞的信号集。当执行信号处理函数时,将会阻塞这些信号,直到从信号处理函数中返回解除阻塞。其中该信号会自动被阻塞,不会递归中断自己。
*/
sigset_t sa_mask;
/* 控制信号处理过程的选项,最常见的有:
SA_RESTART 重启被中断的系统调用,不是所有的系统调用都会被重启,当系统调用被中断时,会返回EINTR。
SA_RESETHAND 调用处理器函数之前设置为SIG_DFL
SA_NODEFER 不会自动添加被设置信号到掩码中
SA_SIGINFO 接受信号附加信息
*/
int sa_flags;
/* ... */
};
需要注意在信号处理函数中调用的函数,有两个概念:
- 可重入函数:一个函数被重入,意味着在执行这个函数的时候,又一次进入了该函数。函数被重入,有两种方式:一是函数递归的调用自身;二是多个线程同时执行该函数,这里的线程代表着不同的逻辑流,比如信号处理函数和主程序、比如多线程。如果一个函数被重入后不会带来任何不良影响,这个函数就是可重入的,也就是说同一个进程的多条线程可以同时安全地调用该函数。一个函数若是可重入函数需要满足下面几个条件:
-
不操作共享变量,比如全局变量和局部静态变量,仅依赖于提供的参数。将不可重入函数转变为可重入函数可以增加新的参数,由用户来提供需要操作的变量。
-
不调用不可重入的函数,如
malloc()。 -
不依赖于锁。比如
malloc()是线程安全函数,但是是不可重入的,在函数内部用锁对共享资源访问进行控制。一般来说,所有的可重入函数都是线程安全的,线程安全函数是可重入函数的真子集。
- 异步信号安全函数:当从信号处理器函数内部调用时,可以保证其实现是安全的。如果某一函数是可重入的,或者信号处理器函数无法将其中断时,就称该信号是异步信号安全函数。
信号处理函数只有在中断了不安全函数的执行,且处理器函数自身也调用了这个不安全函数时,这个函数才是不安全的。要保证信号处理函数的安全性,最好的办法是绝不调用不安全的函数。
由于信号处理的复杂性,一种常见的用法是设置全局标志,然后在主程序中检查并处理。对变量的读写通常不是原子操作,需要几个步骤,比如从内存中读取值,改变值,然后再放到内存中。为了保证读写操作的原子性,在信号处理器函数和主程序之间共享的全局变量应声明如下:
/* sig_atomic_t保证了对变量的读取和赋值为原子操作,但运算操作不是,自增自减也不是。
*/
volatile sig_atomic_t flag;
多进程
在许多情况下,创建多个进程将任务分解会很有帮助。使用fork(2)系统调用可以创建一个子进程:
#include <unistd.h>
pid_t fork(void);
fork()会返回两次:在新创建的进程中返回0,子进程可以调用getpid()获得自己的进程ID,调用getppid()获得父进程ID。在父进程中返回子进程的ID,可以通过不同的返回值来区分父子进程。父子进程的调度顺序是未知的。
fork()创建的子进程是父进程的翻版,同时内存不共享,拥有独立的虚拟地址空间,要注意文件描述符的处理。为了提高创建进程的速度和减少内存的浪费,采用了两种技术:
-
内核将每个进程的代码段标记为只读,父、子进程的页表项指向相同的页帧实现共享代码段。
-
对于可变的段,如数据段、堆栈等,采用写时复制(copy-on-write)技术。父子进程在开始时,页表项指向相同的物理页帧,当需要修改某些虚拟页时,内核将拷贝该页分配给进程。
进程终止
进程终止可以使用exit(2)库函数或者_exit(2)系统调用。exit()会执行一些动作:
-
调用通过
atexit()和on_exit()注册的退出处理程序。 -
刷新stdio流缓冲区。通常只有一个进程调用
exit(),其余的调用_exit()。 -
调用
_exit()系统调用。
进程回收
当子进程终止或停止会向父进程发送SIGCHLD信号,子进程有两种状态:
-
孤儿进程:当父进程在子进程之前退出时,init进程会接管子进程,并处理进程结束后的清理工作。
-
僵尸进程:子进程终止,并且没有被父进程调用
wait()或waitpid()进行回收。子进程终止时仍会保留一些信息,内核为僵尸进程保留了进程表中的一条记录,其中包含了子进程ID、终止状态、资源使用数据等等,之后可以由父进程获取退出信息。
僵尸进程的回收:
-
显示的忽略
SIGCHLD信号:signal(SIGCHLD, SIG_IGN);。虽然SIGCHLD默认就是忽略,显示的设置会将之后终止的子进程立即删除,不会转化为僵尸进程,但不会改变已有的僵尸进程。 -
使用
wait(),该系统调用有许多限制,当没有子进程退出时会一直阻塞,只能等待任意子进程。 -
使用
waitpid()。waitpid()可以获取进程终止、停止或恢复执行的信息,最常见的用法是在信号处理程序中使用,并使用非阻塞的回收,因为SIGCHLD不会排队处理,需要一次性处理多个僵尸进程:
#include <sys/wait.h>
/* pid和kill()系统函数一样
status可以获取子进程状态,之后可以用一系列宏来检测
options设置选项,最常用的是WNOHANG,非阻塞执行,当没有子进程终止时会返回0
waitpid()会返回成功回收的僵尸进程的PID,当没有相应的子进程时,会返回ECHLD错误
*/
pid_t waitpid(pid_t pid, int *status, int options);
/* 要保留errno,因为waitpid()可能会修改
-1 为等待所有子进程
*/
saved_errno = errno;
while (waitpid(-1, NULL, WNOHANG) > 0)
continue;
errno = saved_errno;
执行新程序exec()
使用exec()系列系统调用,将新程序加载到现有进程的内存空间,丢弃原有程序,调用成功不会返回。
#include <unistd.h>
int execve(const char *pathname, char *const argv[], char *cosnt envp[]);
int execle(cosnt char *pathname, const char *arg, ...);
int execlp(const char *filename, const char *arg, ...);
int execvp(cosnt char *filename, char *const argv[]);
int execv(const char *pathname, char *const argv[]);
int execl(cosnt char *pathname, cosnt char *arg, ...);
系统调用有多种组合:
l代表list,所以命令行参数以列表形式。v代表vector,以数组的形式传递命令行参数。e是environment,可以传递环境变量,可以使用extern char **environ;p是path,从当前路径和PATH环境变量来寻找文件。
要注意需要用(char *) NULL作为最后的元素。
在原进程中打开的文件描述符在新程序中仍有效,除非设置close-on-exec选项,通过这个特性,shell实现了重定向和管道。同时原进程的信号掩码和挂起的信号集合也会被继承。
进程间通信IPC
由于进程之间是相互独立的,需要一些特定的办法进行通信。根据功能可以分成三类:
- 通信:在进程之间进行数据交换。
-
数据传输分为字节流和消息两种,字节流的有管道、FIFO和流套接字,消息的有消息队列和数据报套接字。
-
共享内存和内存映射。
-
- 同步:用于在进程和线程操作之间的同步。
-
进程:信号量和文件锁。
-
线程:互斥量和条件变量。
-
- 信号:信号也可以用来通知其他进程,也可以用信号的值进行数据传输。
管道和FIFO
管道用于在相关的进程中进行数据传输:
#include <unistd.h>
int pipe(int pipefd[2]);
调用成功时,pipefd[2]中保存着两个打开的文件描述符:一个读端(pipefd[0]),一个写端(pipefd[1])。管道是单向的字节流,需要双向的字节流可以使用socketpair(),管道可以通过该函数实现。每个进程使用一个,并将另一个关闭,因为只有pipefd[0]全部被关闭时才能读到0,也可以用这个方法同步多个进程。
FIFO与管道类似,最大的差别是FIFO在文件系统中拥有一个名称,可以在非相关进程之间进行通信,也叫做具名管道。
#include <sys/stat.h>
int mkfifo(const char *pathname, mode_t mode);
mkfifo()在文件系统中创建具名管道,之后可以用open()打开。打开一个FIFO会同步读取进程和写入进程,也就是open()会阻塞到读写两端都打开才返回。
管道和FIFO的内核空间是有限的,当写入小于PIPE_BUF字节时,是原子操作。
内存映射
mmap()系统调用在调用进程的虚拟地址空间中创建一个新内存映射。
#include <sys/mman.h>
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
addr一般设为NULL,由内核选择合适的地址,length为映射的大小,内核会以分页大小来分配,prot用于设置权限,flags用于设置私有和共享映射。
私有映射(MAP_PRIVATE):对映射内容的变更对其他进程不可见,对文件映射来讲,不会改变底层文件,采用写时复制技术。
共享映射(MAP_SHARED):对映射内容的变更对所有共享该映射的进程可见,对文件映射来讲,变更会发生在底层文件上。
文件映射使用文件的内容来初始化映射区域,还有一种匿名映射(MAP_ANONYMOUS)将初始化映射区域为0。
映射共享有下面两种情况:
-
多个进程映射了同一个文件的同一个区域,会共享相同的物理内存分页。
-
父子进程会共享相同的物理分页。
使用munmap()可以解除映射区域。
文件锁
文件锁是专门为文件设计的同步技术。有两种方法可以加锁,一种是使用flock(),另一种使用fcntl()。使用这两个方法创建的都是劝告式锁,也就是一个进程可以忽略文件上的锁进行操作,要想锁起作用,需要每一个进程都加锁。在任一时刻,可以有多个进程读取同一个文件,也就是可以获取多个读锁或共享锁,但只能有一个进程写文件,也就是只有一个进程可以获取写锁或互斥锁。
多线程
线程是允许应用程序并发执行多个任务的另一种机制,也叫轻量级进程。它是运行在进程上下文中的逻辑流,是操作系统能够进行运算调度的最小单位。编译时需要设置-pthread选项。
同一进程的多个线程共享进程的内存空间,内核为每个线程创建一个线程栈,和进程相比有两个优点:
-
线程之间可以方便、快速的共享信息,不过需要同步。
-
线程的创建比进程快许多,因为进程需要使用写时复制技术,需要复制一些属性。
创建线程
在进程开始执行时,只有一条主线程。使用下面函数可以创建线程。
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start)(void *), void *arg);
新线程执行(*start)(arg)。其中函数返回类型和参数类型都是void *,所以可以传递任意类型的数据。thread返回线程ID,新线程可能在设置thread之前执行,新线程要获取自己的线程ID,可以调用pthread_self(),pthread_t数据类型不透明,不能当做整型之类的类型,该类型也可以是一个结构。attr用于设置线程的属性,如线程栈的位置和大小、线程可链接或分离状态等。
终止线程
线程可以使用下面几个方法终止:
-
线程start函数执行return返回。
-
线程调用
pthread_exit():
#include <pthread.h>
void pthread_exit(void *retval);
调用该函数与在start函数中return效果一样,意思是在线程内部调用的任何函数内调用该函数都会退出线程。线程的返回值不能指向线程栈内部的地址,因为在线程结束时,线程栈的状态不能确定。
-
调用
pthread_cancel()取消线程,线程默认设置为可取消。 -
任意线程调用
exit()或主线程return,将使进程退出,导致进程中所有的线程终止。主线程调用pthread_exit(),其他线程继续进行。
连接已终止的线程
#include <pthread.h>
int pthread_join(pthread_t thread, void **retval);
若线程未分离,在终止时将产生僵尸线程,浪费系统资源。调用该函数将等待由thread标识的线程终止并回收资源,retval保存线程终止的返回值。这个函数类似于进程的waitpid(),不过有下面几点不同:
-
线程关系是对等的。进程中的任意线程可以调用
pthread_join()连接任意线程。 -
无法连接任意线程,需要指定
thread标识,不过使用条件变量可以完成。
线程分离
#include <pthread.h>
int pthread_detach(pthread_t thread);
调用该函数将使线程分离,不能再用pthread_join()获取返回状态:pthread_detach(pthread_self());。分离的线程终止不会化为僵尸线程,会由系统自动清理移除。
线程同步:互斥量
由于线程共享地址空间,线程对同一资源的访问会造成意想不到的结果,所以需要进行同步。
临界区指访问某一共享资源的代码片段,并且这段代码的执行是原子的,可以通过互斥量来实现。
互斥量有两种分配方式:
-
静态分配初始化(全局变量或
static局部变量):pthread_mutex_t mtx = PTHREAD_MUTEX_INITIALIZER;。 -
动态分配初始化(在栈中或堆中):
#include <pthread.h>
int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t *attr);
int pthread_mutex_destory(pthread_mutex_t *mutex);
在下面几种情况需要动态初始化:
-
动态分配堆中的互斥量。
-
互斥量是在栈中分配的自动变量。
-
使用非默认属性的静态分配互斥量。
当不需要动态分配的互斥量时需要使用pthread_mutex_destory()销毁,只有当互斥量处于未锁定状态,且后续无任何线程企图锁定它时,销毁才是安全的。
若互斥量在堆中,要在free之前销毁。静态分配的不需要销毁。这是因为mutex是一种数据结构,静态分配的会使它一直有效,而动态分配的可能会导致内存泄露需要手动销毁。
互斥量的类型:
-
PTHREAD_MUTEX_NORMAL:和默认类型相仿,不具有死锁检测功能。
-
PTHREAD_MUTEX_ERRORCHECK:对互斥量的操作执行错误检查,运行速度慢,适合于调试。
-
PTHREAD_MUTEX_RECURSIVE:同一进程可以多次加锁同一互斥量。
互斥量加锁解锁:
#include <pthread.h>
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);
一个互斥量只能被一个线程加锁,其余的线程调用pthread_mutex_lock()将阻塞,直到被释放。已加锁互斥量的线程再次加锁该线程会造成死锁。释放未锁定的互斥量或释放由其他线程锁定的互斥量将出错。当线程退出时不会自动释放锁,如果线程被取消(cancel)时没释放锁也会导致死锁。可以设置清理函数来释放资源。
互斥量死锁:
当使用多个互斥量时可能会发生死锁,即线程都在等待已加锁的互斥量释放。 最简单的办法是当多个线程对一组互斥量操作时,总是以固定资源获取顺序对互斥量进行锁定。
互斥量性能:
互斥量对大部分应用程序性能无显著影响。互斥量的实现采用了机器语言级别的原子操作,只有发生锁的争用时才会执行系统调用。
线程同步:条件变量
条件变量允许一个线程就某个共享变量的状态变化通知其他线程。不使用条件变量需要线程轮询检查变量状态,造成CPU资源的浪费,使用条件变量会使线程休眠直到接收到另一个线程的通知。条件变量必须结合互斥量使用,条件变量就共享变量的状态变化发出通知,互斥量提供对共享变量的互斥访问。
和互斥量一样,条件变量也有静态分配和动态分配:
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
#include <pthread.h>
/* 唤醒至少一条遭到阻塞的线程 */
int pthread_cond_signal(pthread_cond_t *cond);
/* 唤醒所有阻塞的线程,主要用于处于阻塞的线程根据变量执行不同的任务 */
int pthread_cond_broadcast(pthread_cond_t *cond);
/* 只有正在等待时才会接收通知,等待之前的通知会消失。*/
int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex);
pthread_cond_wait()相当于执行下面步骤,其中前两步是原子操作:
- 解锁互斥量
mutex。 - 阻塞线程,直到另一线程就条件变量cond发出信号。
- 重新锁定
mutex。
通知的过程:
pthread_mutex_lock(&mutex);
/* 操作变量 */
/* 这两步可以任意顺序 */
pthread_cond_signal(&cond);
pthread_cond_unlock(&mutex);
检查条件变量:
/* 需要用while,因为通知时会有锁的竞争,不能确定哪个线程会醒来,可能会更改变量
*/
pthread_mutex_lock(&mutex);
while (变量不满足)
pthread_cond_wait(&cond, &mutex);
实现连接任意终止线程:使用全局变量保存线程ID和状态,当线程退出时修改状态,并通知条件变量,主线程可以检查所有的线程状态进行回收。
线程安全
若函数可同时供多个线程安全调用,则称之为线程安全函数。实现线程安全有多种方式:
-
调用安全:调用函数前后加锁解锁。
-
函数安全:将共享变量与互斥量关联起来。
-
使函数可重入:无需使用互斥量,重点在于避免对全局和静态变量的使用。可以用调用者分配的缓冲区作为参数或者使用线程特有数据和线程局部存储。
线程特有数据
使用线程特有数据可以无需修改函数接口就实现已有函数的线程安全,线程特有数据使函数为每个调用线程分别维护一份变量的副本。要注意线程特有数据不是为了在线程中分配私有的数据,因为线程栈都是独立的,是为了在线程内部调用的函数分配线程私有数据实现线程安全。
#include <pthread.h>
int pthread_once(pthread_once_t *once_control, void (*init)(void));
int pthread_key_create(pthread_key_t *key, void (*destructor)(void));
int pthread_setspecific(pthread_key_t key, const void *value);
void *pthread_getspecific(pthread_key_t key);
线程特有数据的实现方法如下:
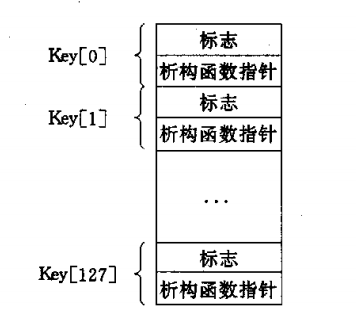
- 在进程范围维护一个全局数组,存放线程特有数据的键信息:该键是否被使用,还有该键对应的析构函数指针,在线程结束时,会将与键关联的值作为参数调用析构函数。使用
pthread_key_create()返回的其实是该全局数组的索引,并设置对应数据。
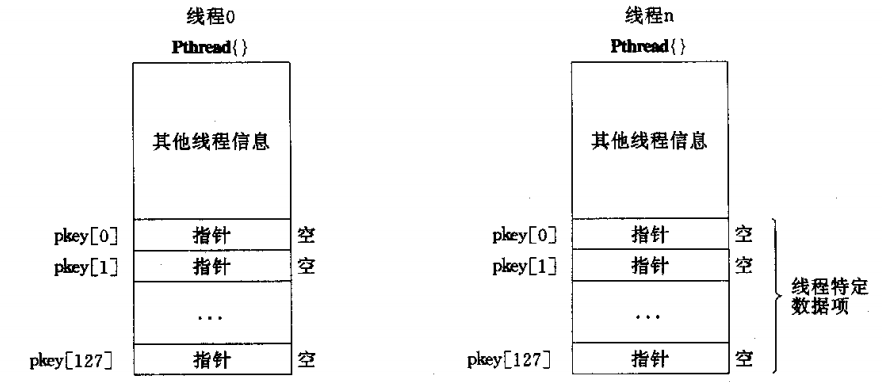
- 每个线程包含一个指针数组,存有为每个线程分配的线程特有数据块的指针。指针会被初始化为NULL,需要使用
pthread_getspecific()检查是否为NULL,然后使用pthread_setspeific()关联值。
多线程程序有时有这样的需求:不管创建了多少线程,有些初始化动作只能发生一次。如果在主线程这样做易如反掌,只要在创建新线程之前初始化就可以。但是许多库函数为了实现线程安全,在函数内部使用了互斥量等,互斥量需要被初始化,但每次调用该函数都会被初始化一次,这就有了问题。使用pthread_once()可以解决这个问题,实现一次性的初始化。线程特有数据也有同样的需求,键只被第一次调用产生的线程初始化。
常见的用法如下,省略错误处理:
/* 初始化一次性量 */
pthread_once_t once = PTHREAD_ONCE_INIT;
pthread_key_t key;
/* 析构函数,用来释放线程特有数据,通常线程特有数据是堆上分配的内存 */
void
destructor(void *buf)
{
free(buf);
}
/* 初始化键,需要按照once的要求包装函数 */
void
create_key(void)
{
pthread_key_create(&key, destructor);
}
/* 在函数中 */
void *
func(void *arg)
{
/* ... */
char *ptr;
/* 一次性的初始化键 */
pthread_once(&once, create_key);
/* 获取关联值 */
ptr = pthread_getspecific(key);
if (ptr == NULL) {
/* 分配值,通常是用`malloc()`类函数 */
ptr = malloc(size);
/* 设置值 */
pthread_setspecific(key, ptr);
}
/* 之后ptr就是每线程特有的数据了 */
}
线程局部存储
线程局部存储也提供了每线程的存储,不过使用方法特别简单:只需要在全局或静态变量的声明中包含__thread。使用这种变量,每个线程拥有一份对变量的拷贝,当线程终止时会自动释放掉,要注意下面几点:
-
如果使用了
static或extern,__thread要紧随其后。 -
该变量与一般变量相同,可以初始化,可以取地址,唯一的不同是每线程持有不同的拷贝。
线程与信号
在多线程程序中信号比较复杂,有下面几个点:
-
信号的处置属于进程层面,进程中的所有线程共享对每个信号的处置设置。
-
当收到一个已设置信号处理函数的信号时,内核会任选一条线程来接收这一信号,调用信号处理函数。当收到的信号的动作是停止或终止,则对整个进程有效。
-
pthread_mutex_lock()和pthread_cond_wait()被信号中断会自动重启。 -
信号掩码是线程特有的。刚创建的新线程会从其创建者处继承信号掩码的一份拷贝,使用
pthread_sigmask()可以修改,用法和sigprocmask()一样。 -
信号可以向线程发送:
-
信号产生源于线程上下文中对特定硬件指令的形成,如
SIGBUF、SIGFPE、SIGILL和SIGSEGV。 -
线程写断开的管道时的
SIGPIPE。 -
使用
pthread_kill()和pthread_sigqueue()向特定线程发送信号。
-
线程与exec()
只要有任一线程调用了exec(),进程会被完全替换,除了调用线程之外,其余线程都消失。不会析构线程特有数据,也不会调用清理函数。
线程与fork()
当多线程进程调用fork()时,仅会将发起调用的线程复制到子进程中,其他线程都消失。不会析构线程特有数据,也不会调用清理函数,导致内存泄露。同时子进程保留了父进程的全局变量的状态和所有的Pthreads对象(如互斥量、条件变量等),在fork()期间,这些变量可能会发生改变。所以推荐在多线程程序中调用fork()的唯一情况是子进程直接调用exec()。
线程与errno
在进程中,errno被实现为一个全局的整数。而在线程中,为了避免线程间的errno混淆引发竞争,被实现为宏,展开为一个函数调用,返回一个可修改的左值,且每个线程独有。
计算机网络
TCP/IP
协议是什么?协议就是一种约定,就像我们平时说的语言,是一种规定的、需要遵循的模式。
网络协议这方面我主要看了两本书:《TCP/IP详解 卷一》, 《计算机网络》。前一本是经典,后一本是上课的教材。感觉电子专业课程的安排问题很大,没有安排其他的编程课程就直接学计算机网络了,学了也不知所云。学习网络协议要搭配着网络编程来学,推荐《UNP》。
协议模型
模型主要有两种:
- OSI(开放式系统互连) 7层模型
- TCP/IP参考模型 4层(或5层 最底层为物理层)
OSI模型和协议过于复杂,也很少见,最主要的还是TCP/IP参考模型:
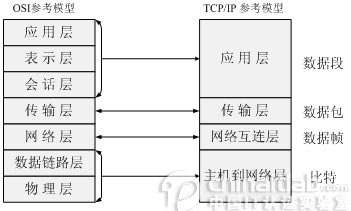
分层的目的是为了降低网络设计的复杂性,每一层都建立在其下一层的基础上。每一层使用不同的协议,并为上一层提供服务。数据从高层向下传输会增加消息头部或尾部,而从低层向上会去掉。每层也实现了不同的功能,以TCP/IP模型为例:
-
数据链路层,有些称为链路层或者网络接口层。主要处理计算机和下面的网络硬件之间的接口。最流行LAN的是以太网(Ethernet),传递的消息称为帧(Frame)。辅助的协议主要有:地址解析协议(ARP)、逆向地址解析协议(RARP),这两个协议是为了IP地址和物理地址(MAC地址)的相互转换。
-
网络层。主要是IP协议(网际协议),传递的消息称为数据报(Datagram)。提供的最主要的功能是路由(routing),也就是将数据从源端发送到目的端。注意和数据链路层区分:数据链路层是在同一个网络下在主机间进行传输,网络层是将数据通过路由器等在不同网络间传输。辅助的协议主要是Internet控制消息协议(ICMP),用来报告意外事件,比如超时、出错等等。
-
传输层。传输层为不同主机上的应用程序提供端到端的通信,需要传输的数据主要就封装在这一层。最常见的协议有两种:传输控制协议(TCP)和用户数据报协议(UDP)。TCP提供了面向连接的、可靠的、全双工的字节流通信;而UDP提供的是无连接的、不可靠的、有消息边界的通信。 TCP传递的数据称为分段(Segment)。
-
应用层。应用层是在传输层的基础上,对数据的格式进行特殊的规定,来实现不同的功能。最常见的有:域名系统(DNS)、超文本传输协议(HTTP)、电子邮件等等。
网际协议(IP)
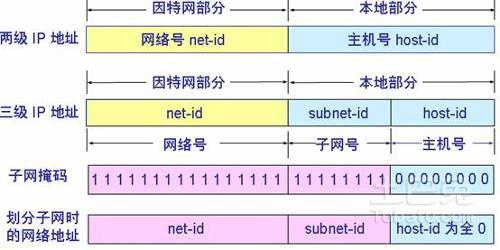
IP协议有两种:IPv4和IPv6,目前最主要的还是IPv4。IP传递的是数据报,提供无连接的尽力而为服务。
IP协议使用IP地址来寻址。IP地址标识的是与物理链路交互的接口(interface),包括主机与物理链路的接口和路由器与链路的接口,IP要求每台主机和路由器接口都拥有自己的IP地址,路由器通常
有多个接口,也就有多个IP地址。
IPv4使用32比特的IP地址,通常表示为点分十进制。一个IP地址划分为两部分:a.b.c.d/x,x为子网掩码,指示了子网地址的位数,剩余的32-x比特用于区分子网内部的设备。
寻址首先找到对应的网络,然后在该网络内部寻址具体的设备,这些独立的网络也就是子网,IP协议使用分层的网络,子网内部也可能继续划分子网,不同的子网间通过路由器通信。
过去IP地址是分为5类ABCDE的,每一类有固定的网络ID位数和主机ID位数,容易造成IP地址的浪费,比如一个C类(/24)子网能容纳2^8 - 1 = 254台主机,而一个B类(/16)子网能共容纳65534台主机,
差距太大,分配C类太小而B类太大,不易控制。现在使用无类别域间选路(CIDR),子网掩码的位数不再固定,更易选择合适的子网位数。
子网地址一般由互联网服务提供商(ISP)提供。一台设备想要联网需要获取其IP地址。路由器接口地址,可以由系统管理员手工配置,也可以使用动态主机配置协议(DHCP)从ISP的DHCP服务器
获取其地址。主机可以手工配置,不过更常用DHCP从路由器运行的DHCP服务器获取IP地址。DHCP还可以获取其他地址,如第一跳路由器地址(默认网关)和本地DNS服务器地址。
DHCP是C/S协议,每个子网一般都拥有一个DHCP服务器,当一台主机连接时,会通过UDP与DHCP服务器交互,自动获取其IP地址。
还有一种地址分配方法网络地址转换(NAT),可以解决ISP分配的子网所支持的IP地址不够用的情况(比如越来越多的设备接入子网)。
在RFC1918中保留了3部分IP地址空间,用于专用网络或具有专用地址的地域,即地址只对该网络中的设备有意义,无法与外部交流。这样可以使许多网络采用相同的子网和IP地址,这些子网
通过NAT使能路由器与外界交互,NAT路由器对外界隐藏了专用网络,相当于一个具有单一IP地址的设备,当有数据报到达时,通过端口号区别子网内部的主机。
互联网控制报文协议(ICMP)主要用于差错报告,比如目的网络不可达等。ICMP通常认为是IP协议的一部分,不过ICMP报文是承载在IP有效载荷上的,类似TCP和UDP。
IP数据报到数据链路层传递时,可能会发生分片,原因是IP数据报的大小超过了数据链路层的最大传输单元(MTU)。
还有一个概念叫做路径MTU,是连接的网络间MTU的最小值。以太网的MTU为1500字节。要避免分片的发生,即使只丢失一片数据也要重传整个数据报,不过使用TCP的话,会重传丢失的数据。
上面提到的都是单播,即点对点,网络层也支持广播和多播:
-
有一个特殊的全为
1的IP地址,即255.255.255.255`,这是广播地址。当一台主机发送一个目的地址为广播地址的数据报时,该报文会被交付给同一个子网中的所有主机。 -
多播采用互联网组管理协议(IGMP)实现,使用
D类地址关联多播组。
数据链路层
数据链路层提供的服务是将网络层的数据报通过路径上的单段链路节点到节点地传送,节点就是主机和路由器。数据在局域网(LAN)中进行传播,LAN是一种集中在一个地理区域的计算机网络,
通常联网是从主机经LAN再经路由器到因特网。最常见的局域网有以太网和802.11无线LAN(WiFi)。
要注意和网络层区分:
-
网络层是选路,确定路线,在不同的网络中传输,依靠数据链路层在链路中传输。
-
子网和
LAN有些相像,不过子网是三层可达,通过路由器在子网之间路由,而局域网是二层可达,通过交换机在节点中通信。子网内部通过局域网通信,不精确的说子网也对应着局域网。
和IP协议一样,数据链路层也有自己的编址。每个节点的适配器或者说网卡都有自己的地址,通常称为MAC地址或物理地址。MAC地址为6字节,通常由16进制表示:XX-XX-XX-XX-XX-XX,
MAC地址标识着节点的硬件设备:适配器,通常是永久的,不会发生变化。而IP地址一般是动态分配的,会发生变化。
为什么链路层还有自己的地址呢?一是IP地址标识了目标主机的地址,而在传输的过程中需要在不同的路由器中传输,使用链路层地址可以标识下一跳路由器,从而实现传输。二是为了分层,保持各层次独立。
对于数据链路层来说,不能理解IP地址,所以需要使用地址解析协议(ARP)在MAC地址和IP地址间转换。当需要发送数据报时,首先在ARP表中查询地址映射,
如果没有就在LAN中发送一个ARP查询分组,使用MAC广播地址(FF-FF-FF-FF-FF-FF),如果目标IP地址在同一个LAN内,与目标IP地址匹配的主机就会将自己的MAC地址响应给源主机,
更新ARP表。如果需要跨子网传递,路由器就会将自己的MAC地址相应给主机。
ARP和DNS有些像,不过DNS是将因特网中任何地方的主机名或域名解析为IP地址,而ARP只能解析同一个子网上的IP地址。
UDP
UDP提供的是无连接的、不可靠的、有消息边界的数据报通信。UDP只是在IP协议上增加了两个东西:校验和和端口,所以应用程序几乎是直接与IP打交道,不提供可靠的数据传输。
UDP是无连接的,并且没有流量控制,可以更好的控制发送时间,并且在一些情况下速度会比较快,比如如果应用程序只涉及到短的请求和应答,UDP性能就会比TCP好很多,因为没有建立连接和释放连接的开销。
由于UDP只是简单的封装IP,所以出错时会返回网络层的ICMP来通知。使用UDP的例子有:域名系统(DNS)、网络文件系统(NFS)和简单网络管理协议(SNMP)。
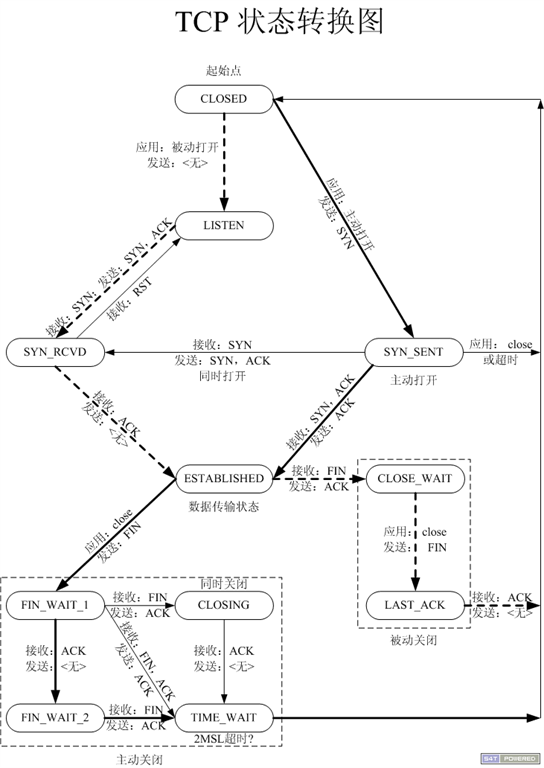
TCP
TCP提供的是面向连接的、可靠的、全双工的字节流通信。为了提供可靠性,TCP提供了几个服务:
- 提供了校验位(Checksum),确保到达目的地的数据不会被破坏;
- 每个分段中分配一个序列号,可以使数据按照顺序组合起来,也解决了接收重复分组的问题。
- 提供了超时、重传和确认机制,保证每个段都会被递交到可达目的地。
- 提供了流量和拥塞控制,防止溢出并提高效率。
- 提供了
TCP传输层的错误通知机制RST,也可以使用IP网络层的ICMP。
TCP不提供安全性,有一种TCP的强化版本叫做安全套接字层(SSL),提供了安全性服务,https就是以SSL为基础。
端口号
网络层IP只提供了主机到主机的交付,进程间数据交付和差错检测是由传输层提供的最基本的服务。传输层将报文交付到正确的进程(套接字)叫做多路分解,将报文从传输层传递到网络层叫做多路复用。
TCP和UDP协议都使用了端口号来标识套接字。可能的、被正式承认的端口号有 2^16 -1 = 65535 个。
端口被分为三类:著名端口、注册端口和动态端口。
- 著名端口是由因特网赋号管理局(IANA)来分配的,并且通常被用于系统进程,用来指定特定的服务。这些端口的一个显著特征就是限定在0~1023,并且在Linux、UNIX平台均需要Root权限才能监听这些端口。
- 注册端口不由IANA控制,不过由IANA登记并提供它们的适用情况。
- 动态端口通常被用来运行各种用户自己写的服务,服务监听在这些端口下不需要特别的权限。
- 动态端口,通常也称为临时端口。动态端口通常被用来在主动发起连接时随机分配使用,在任何特定的连接外不具有任何意义。有一个特殊的端口号0,当绑定该端口号时,内核就分配一个临时端口号给套接字。
传输层使用端口号来区分套接字,对于不同的协议,端口号的处理情况也不同:
- UDP: UDP是无连接的,一个UDP套接字是由
(IP地址, 端口号)标识的。只要UDP报文的目的IP和目的端口号与它一致就会发送到该套接字。UDP也可以连接使用,不过是一种虚连接,不是真正的连接,参看 最后。 - TCP: TCP是有连接的,连接建立后会返回已连接套接字,要和未连接套接字区别对待:
-
未连接套接字: 一般是监听套接字才需要绑定
IP地址和端口号,之后调用listen变为监听套接字。多个监听套接字通过绑定的IP地址和端口号区分。 -
已连接套接字: 由服务器
accept返回得到或客户端connect得到。已连接套接字通过四元组(源IP地址, 源端口号, 目的IP地址, 目的端口号)标识,accept返回的已连接套接字会继承监听套接字的IP地址和端口号。(绑定0除外, 见下面)
-
- 在套接字建立时会选定是
TCP还是UDP,不同协议间的端口号是独立的,互不影响,所以更准确的说,套接字是由(协议, IP地址, 端口号)标识。
当绑定通配地址INADDR_ANY时,当连接建立后(TCP)或发送、收到消息后(UDP),会由内核分配IP地址给套接字;当绑定端口号0时,会立即分配一个随机的端口号给套接字。
当不绑定时,效果和绑定INADDR_ANY和端口号0类似: 当连接建立后(TCP)或发送消息(UDP),会分配给套接字IP地址和端口号;当调用listen时,会给监听套接字分配端口号。
服务端需要绑定固定的端口号,否则会随机分配端口号,导致无法确定套接字。客户端一般不绑定,由内核分配。
SO_REUSEADDR和SO_REUSEPORT
套接字是由(协议, IP地址, 端口号)标识的,不能有完全相同的三元组,否则无法区分,所以当相同类型的套接字绑定相同的IP地址和端口号时,会返回EADDRINUSE: address already in use。
只要有一个不同就可以绑定。
通配地址INADDR_ANY比较特殊,当绑定了通配地址后,就相当于所有的本地IP地址都被它同时绑定了,所有后续的套接字无法再绑定相同的端口号,反之也一样,当有套接字绑定了特定的IP地址后,
也无法再绑定通配地址和相同端口号给套接字。
当有TCP已连接套接字时,也相当于该IP地址和端口号被占用了,也无法绑定重复的。TCP连接套接字是由四元组标识的,而监听套接字是由二元组决定的,不相关,为什么还这样设置呢?
我觉得可能是这样,假如可以绑定相同的IP地址和端口号,在建立连接时会出现重复的四元组,这当然不允许,就会在客户端connect返回错误,而客户端的错误一般不易发现和解决,毕竟客户端是由客户使用,
而服务端是由服务提供者维护的。
TIME_WAIT状态也会导致同样的效果,处于TIME_WAIT状态的连接和已连接套接字一样会继续占用IP地址和端口号,直到进入CLOSED状态。
和TIME_WAIT有关的还有一个时间叫做Linger Time用于发送套接字缓冲区中
还未发送的数据,详见下面的close和SO_LINGER选项。
SO_REUSEADDR可以解决上面的问题,设置该选项主要有两种功能:
-
将通配地址和特定地址区分开: 当通配地址已被绑定时,还可以绑定特定地址,只要不绑定完全相同的地址和端口号,反之亦然。
-
将未连接套接字和已连接套接字区分开: 这两个使用的
IP地址和端口号互不影响,所以当处于TIME_WAIT状态或还有连接时(如连接在子进程中处理,而主进程已退出)可以立即重启服务器。
Linux 3.9添加了SO_REUSEPORT选项。设置该选项可以将任意多个套接字绑定到完全相同的IP地址和端口上,绑定相同地址和端口号的监听套接字由内核实现简单的负载均衡。
对于UDP来说,SO_REUSEADDR和SO_REUSEPORT效果一样。
详细见stackoverfow
要注意标识连接的四元组用完或重复出现的情况,出现的原因可能有绑定了相同地址和端口号的套接字连接到固定地址的服务器,更可能是因为客户端所有地址和端口号都已经用完,比较常出现在
短连接的情况,已关闭连接的TIME_WAIT状态会占用四元组直到耗尽2MSL。此时客户端调用connect会出现EADDRNOTAVAIL: Cannot assign requested address。
在Linux上有需要注意的地方:
-
在
BSD只需要当前要绑定的套接字设置SO_REUSEADDR即可;在Linux上(至少我的电脑上ubuntu 14.04),先前的套接字也需要设置该选项才可以。 -
当绑定了通配地址的套接字调用
listen变为监听套接字之后,设置SO_REUSEADDR也无法再绑定相同的端口号给其余套接字,反之亦然,当有绑定了特定地址的监听套接字时, 也无法再绑定通配地址和相同的端口号给别的套接字。
建立连接
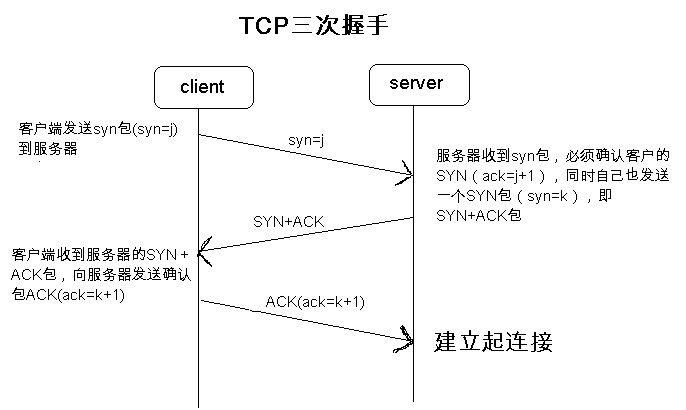
TCP建立连接需要发送三个段,所以也叫做三次握手。连接建立后,内核会为TCP连接分配TCP缓存和状态变量。在建立连接的过程中,还有两个重要的选项会被交换:
- 最大段大小(
MSS)。用于向对端通告每个段所能发送的最大TCP数据量,不包括TCP首部。目的是为了避免IP分片,通常大小为1460。(以太网MTU - IP头部 - TCP头部) - 窗口规模选项。用于通告对端当前套接字缓冲区空间大小,可以使用
SO_RCVBUF选项修改默认大小。通过对端不会发送比收到的窗口规模大的数据量,从而避免接受端发生溢出,实现流量控制。
这两个选项看起来有点重复,其实前一个决定的是每一个TCP分段的大小,后一个决定的是当前能够发送多少数据,而数据是以TCP分段为单位的。
为什么建立连接需要三次握手呢?
-
为了建立可靠的连接,如果只产生两个数据交互,服务器并不能知道连接是否建立成功并可以发送数据、对端能否接受连接。当收到第三个数据段的ACK时,服务器才能确认对方已收到第二个数据段,已成功建立连接。而三次也是理论上能够建立可靠数据交互的最小值,所以不会发送更高次数。
-
为了防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误,比如由于网络延迟直到连接已释放才发送到服务端的连接请求。此时会由于服务端收不到第三个数据段导致超时重传,当重传次数过多时就会返回给进程错误。如果不发送第三个数据段,服务器接收到失效的连接请求之后发送ACK,服务器会认为已经建立的连接,等待无效的客户端发送数据,导致资源的浪费和出错。
释放连接
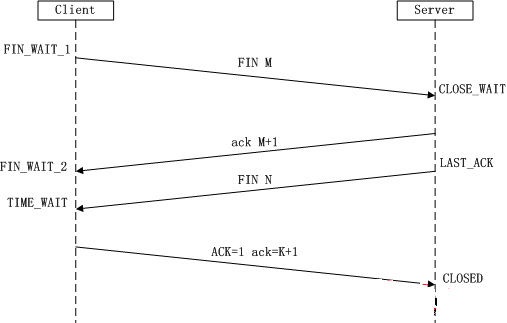
释放连接需要交换4次,也叫做四次挥手。这是因为TCP连接是全双工的,需要每个方向单独进行关闭,当一端结束数据传输时,就发送FIN通知另一端。一个TCP连接在收到一个FIN后仍能发送数据,利用半关闭(shutdown)可以实现。
释放过程中,先发送FIN的一端执行的是主动关闭,当收到对端的FIN并发送ACK时,会进入一个特殊的状态TIME_WAIT。还有可能发生两边同时发送FIN,最后都进入TIME_WAIT状态。这个状态至少需要经过2MSL(最大段生存时间)后,根据实现不同持续在1分钟到4分钟之间,才会到CLOSED状态。它主要有两个作用:
-
可靠地实现TCP全双工连接的终止。因为最后发送的
ACK有可能会丢失掉,对端会再次发送FIN,如果没有这个状态,会响应一个RST,导致对方进入错误状态而不是有序终止状态。当处于这个状态时,每收到一个段都会重启2MSL的计时器。MSL是IP数据报存活的最长时间(TTL跳数限制)也就是TCP段存活的最长时间,TIME_WAIT持续时间至少是超时重传的timeout+ 重传的FIN的传送时间,为了保证可靠,采用更加保守的等待时间2MSL。这个状态不能保证最后的ACK一定被对端收到,只是在等待足够长的时间后,可以认为连接被关闭了。 -
使老的重复TCP段在网络中消逝。因为数据有可能会重复发送或者经过网络延迟直到连接关闭才到达目的地。如果这时没有相应的连接,TCP仅仅丢弃该数据并响应RST。然而,如果主机间又建立了一个具有相同IP地址和端口号的连接(称为前一个连接的化身),就会认为该段是属于新连接的,导致数据混乱。TIME_WAIT状态不允许发起新的化身,并且持续2MSL,就可以确保每成功建立一个连接,都不会受到之前连接的影响。不过也有例外,有些实现当新的SYN的序列号大于之前连接的结束序列号就会成功发起新的化身。
每个连接是由一个四元组决定的,要求不能重新建立相同的四元组连接,TIME_WAIT状态会占用之前的IP地址和端口号直到进入到closed状态。设置SO_REUSEADDR选项可以使用相同的端口号,但是不同使用相同的五元组。
超时、重传与确认
TCP是有状态的,内核保存着缓冲区和许多状态变量。序号Seq是段首字节的字节流编号,确认号ACK是期望收到的下一字节的序号。
TCP采用累积确认,只确认数据流中第一个丢失字节为止的字节,也就是确认收到的ACK之前的字节。
内核保存着发送过的段,直到接收到对端发送的ACK大于其Seq才丢弃,见下面的滑动窗口。
当发送一个段时,会启动一个定时器,当定时器超时时还没有收到对端的ACK就会重传。
重传不意味着数据没有发送到,也有可能是ACK丢失或者在网络中延时过长导致。
如果一直收不到ACK,TCP会持续重传数据段,直到尝试一定次数才放弃,然后返回给应用进程一个错误,通常是ETIMEOUT。
如果发生了可以被检测到的错误会直接返回错误,而不是超时重传。
当收到3个冗余ACK时就会重新发送该Seq的段,而不必等到超时,因为收到3个重复的ACK意味着在Seq这个段之后的段被收到了3次,
有理由相信这个段已经丢失,这就是快速重传机制。
使用Seq和Ack也可以区分冗余的TCP段,当收到的段的Seq小于当前的Ack时,就会知道该段已经接受过了,只返回Ack不再存储数据。
流量控制和拥塞控制
影响数据传输的主要有两方面:网络和应用程序缓冲区空间。
如果TCP突然有大量的段发送到网络中,由于网络的速率一般都不同,快速的网络的数据会积攒在路由器中,可能会导致路由器的缓冲空间耗尽,路由器丢弃数据,导致重传,进一步使网络拥挤。 为了避免这个问题,TCP使用了慢启动和拥塞避免算法,并维护了一个拥塞窗口(cwnd),这是拥塞控制。
内核为每个套接字维护了两个缓冲区:接收缓冲区和发送缓冲区,每个TCP段都会通告对方当前接受缓冲区的可用大小,对端发送的数据不能超出该大小。
与SYN一起发送的窗口大小通告了最大缓冲区大小。TCP使用了滑动窗口的技术,配合ACK来实现高效的数据传输,这是流量控制。
发送窗口由对等方TCP使用,以预防应用程序发送的数据超过接收方TCP缓冲区;拥塞窗口由本方TCP使用,以预防应用程序超过网络所能承受的能力。 任何时候TCP能够发送的最大数据量是发送窗口和拥塞窗口的最小值,以确保两种类型的流量控制都能有效。
慢启动和拥塞避免
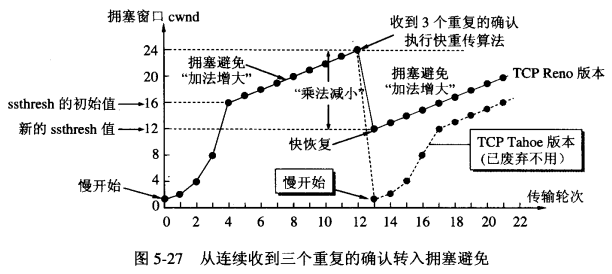
当一个连接建立起来时,无法知道合适的拥塞窗口大小。为了从一开始就避免发生拥塞,慢启动算法将拥塞窗口初始化为一个MSS大小,之后每收到一个ACK就增加一个MSS大小。
实际上,每经过RTT就会使拥塞窗口大小增加一倍,慢启动其实一点也不慢。拥塞窗口一直呈指数级增长,直到发生超时,或者重复确认,或者达到接收方窗口大小。
拥塞避免算法是缓慢增加窗口大小的算法,每个RTT增加1MSS的窗口大小,也就是加性增。
慢启动和拥塞避免是如何来实现拥塞控制的呢?TCP使用了一个变量来控制:门限阈值(Threshold),每次发生丢包时,该值被设置为当前拥塞窗口大小的一半。
起始时,阈值设置非常大,并采取慢启动算法。当发生丢包即拥塞时,对待超时和重复确认采取不同的方法:
-
超时时,拥塞窗口被重置为一个MSS,再次使用慢启动算法,当窗口到达
Threshold时采用拥塞避免算法。 -
重复确认时,拥塞窗口设置为
Threshold,并使用拥塞避免算法,取消了慢启动,这就是快速恢复算法。
滑动窗口
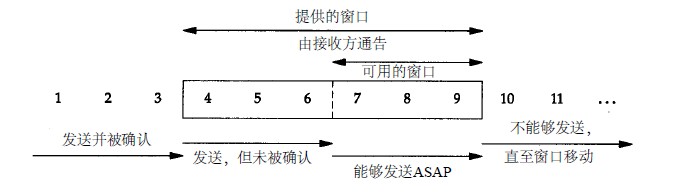
在上面也提到了内核中的缓冲区概念。滑动窗口不是一个新的缓冲区,而是一种算法,用来高效的组织、协调TCP连接两端的缓冲区。
TCP连接的每一方都维护着一个接受窗口,窗口的最左边是期望接收的下一个序列号,最后边是能够接受的最大数据的序列号。
当一个TCP段到达时,任何序列号超出接受窗口的数据(左边已收到的或右边未获得缓冲区的)或在窗口范围内但已经接收到的将被丢弃,除了超出窗口范围的,都会重新确认发送ACK。
TCP段有可能是乱序到达的,就会缓冲在缓冲区中,滑动窗口也不移动,也不会向上层进程返回数据,直到收到期望的数据段,这时会更新ACK,滑动窗口右移,接收后面的数据。 当窗口为0的时候,有两种情况可以继续发送数据段:一是发送紧急数据;二是继续发送只有1个字节的数据段,让接收方通告下一个期望字节和窗口大小。 这是由TCP坚持定时器决定的,当窗口大小为0时,就会启动该定时器,终止时发送一个一个探查段,查询是否有窗口大小更新, 同时也避免了窗口更新消息的丢失导致的死锁,导致一直在等待窗口更新无法发送数据。(因为TCP对于ACK是没有相应的ACK确认的)。
每一端也维护了一个发送窗口。发送窗口分为两部分:已经发送的但没有确认的和可以发送但还没有发送的。为了提供可靠性,TCP发送端直到收到对端的ACK才会将缓冲区的内容踢出去,并向右滑动发送窗口。
Nagle算法、愚笨窗口综合症和ACK延滞算法
Nagle算法和ACK延滞算法是为了减少TCP段以降低拥塞出现的可能性。
Nagle算法的目的是减少小的TCP段的数量,该算法指出在任何时间内至多只能有一个没有确认的“小段”,“小段”也就是大小小于MSS的TCP段。当连接空闲时,如果有数据要发送就会立即发送,如果接下来的数据比较小,就会被收集起来,直到收到前一个的ACK再一起发送出去。数据比较大能充满1个MSS时,一般实现会立即发送。
Nagle算法其实愚笨窗口综合症(SWS)在发送方的表现,还需要在接收方的配合,不要通告小的窗口。假设接收方每次只读取少量数据,导致接受缓冲区只有很小空间,这时对端就会发送一系列小的数据段。所以除非缓冲区空间有了“显著的增长”,否则是不会发送窗口更新消息的。根据实现的不同,空间大小至少为1个MSS或最大窗口的一半大小。
ACK延滞算法是为了减少TCP段的数量,该算法使得TCP在接受到数据后不立即发送ACK,而是等待一小段时间(50~200ms)。如果在这个时间内,自身有数据要发送给对端,就会将这些数据捎带,结合成一个数据段发送给对端。如果没有数据,就会等到计时器超时,发送该ACK。
当Nagle算法和ACK延滞算法在一起时可能会引发问题,会带来很大的延迟:Nagle算法防止数据确认之前发送下一个数据,而延滞ACK要求等到计时器终止才发送ACK。设置TCP_NODELAY选项可以禁用Nagle算法。
Keepalive
TCP不是轮询,不提供网络连接中断的通知,当出现问题时,除非你调用函数交互,否则就会认为一直在保持连接。这样设计的原因一是因为轮询会带来网络带宽的消耗;二是为了提供网络突然中断时仍能维持通信的能力,只要之后网络恢复。
TCP提供了一个Keepalive机制用于检测连接。当在一定时间间隔后,连接没有进行交互,就会发送一个特殊的段给对方,如果连接正常,对方就会响应一个ACK,如果连接不正常,就会产生错误。一般实现的时间是2个小时。设置SO_KEEPALIVE选项可以开启该机制。
网络编程
网络编程的学习主要是通过《UNIX网络编程》来学习的,也看了一下《Effective TCP/IP》和一些项目。网络编程在一个项目中占到的比重一般比较小,更重要的是基于网络的功能的实现,但几乎每一个项目都离不开网络。网络编程细节上的东西也比较多,准备在这里记录一下,主要是TCP,有小部分UDP和UNIX域套接字。IP方面主要是IPv4,但也追求协议无关的编程。
网络字节序和主机字节序
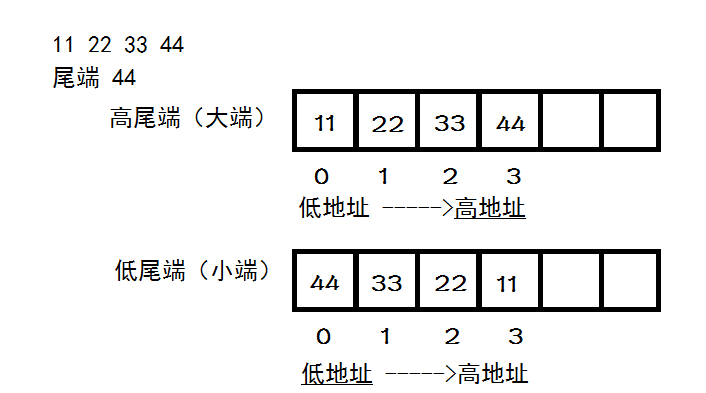
根据体系结构的不同,计算机会以不同的方式存储和解释数据:一种是将低位字节存储在起始地址/将低地址的数据解释成低位字节,叫做小端法(little-endian);另一种将高位字节存储在起始地址/将低地址的数据解释成高位字节,叫做大端法(big-endian)。应用程序发送数据总是从低地址开始一字节一字节的发送数据,所以数据在内存中的存储方式会影响在网络中传输的顺序,而应用接受数据也按照顺序从低地址开始存储,也就是说数据在发送端和接收端的内存存储方式是相同的,但是解释方式不一定相同。网络协议规定了以大端字节序作为网络字节序,提供了一系列的字节序转换函数:
#include <netinet/in.h>
/* s为16字节,l为32字节,即使在64位处理器中,long int为64字节 */
uint16_t htons(uint16_t hostshort);
uint32_t htonl(uint32_t hostlong);
uint16_t ntohs(uint16_t netshort);
uint32_t ntohl(uint32_t netlong);
| h | n | s | l |
|---|---|---|---|
| host | network | short | long |
发送端可以将二进制数据转换为网络字节序发送,然后接收端接收数据后转换为主机字节序,就消除了不同存储方式的影响,但是这不代表没有问题了,因为不同的主机上数据类型的大小也会不同,当考虑结构体时,就更复杂了,在结构的内部还会根据不同的字段对齐规则填充字节。所以相比于传递二进制结构,更好的办法是将所有传输的数据编码成文本形式,因为字符只占1个字节,所以不会有大小端的影响,也没有不同大小的影响。
字节序转换函数的最大用途是在地址结构体赋值中使用:htons(port)转换端口号;htonl(addr)转换地址。
地址结构
由于有多种协议,也就有了多种地址结构。 对于最常见的IPv4套接字来说:
#include <netinet/in.h>
struct sockaddr_in {
sa_family_t sin_family; /* AF_INET */
in_port_t sin_port; /* 16-bit port number */
struct in_addr sin_addr; /* 32-bit IPv4 address */
/* padding... */
unsigned char __pad[X];
};
struct in_addr {
in_addr_t s_addr; /* 32-bit IPv4 address */
};
通常只需要用到sin_family、sin_port和sin_addr,但一般具体实现中还有别的元素,所以需要在使用前置零,使用memset(&addr, 0, sizeof(addr));或者bzero(&addr, sizeof(addr)); 在初始化时,sin_port和sin_addr需要转换为网络字节序,因为这些字段会用在不同主机之间通信,比如附加在TCP和IP头部。要注意地址的访问方法,sin_addr是一个结构,而sin_addr.s_addr是一个32位无符号整数,有些函数对这方面有要求。
IPv6地址是128位的,所以会被存储在一个sockaddr_in6结构中,端口号和地址族和IPv4相同,还有一些其他的元素。
UNIX域套接字地址以路径名来表示,不需要用到端口号:
#include <sys/un.h>
struct sockaddr_un {
sa_family_t sun_family; /* AF_UNIX */
char sun_path[108]; /* Null-terminated socket pathname */
};
当套接字地址结构作为参数传递给函数时,总是以指针传递。为了处理不同类型的指针,最简单的方法是使用void \*指针,但是套接字函数比ANSI C早,所以定义了一个通用的套接字地址结构:
#include <sys/socket.h>
struct sockaddr {
sa_family_t sa_family;
char sa_data[14];
};
它的唯一用途就是用在函数参数传递时进行强制类型转换来消除编译器的警告: bind(fd, (struct sockaddr) &addr, sizeof(addr)); 不能用它来存储不同类型的地址结构,因为它的大小不足以存储所有的数据。
IPv6套接字API新定义了一个通用套接字地址结构,它的大小可以容纳所有的套接字地址结构,即可以将任意类型的socket地址结构强制转换并存储在这个结构中:
#include <netinet/in.h>
struct sockaddr_storage {
sa_family_t ss_family;
__ss_aligntype __ss_align; /* Force alignment */
char __ss_padding[SS_PADSIZE]; /* Pad to 128 bytes */
};
需要用到的只有ss_family,用来确定套接字地址结构的类型,然后强制类型转换到相应的类型再使用。
地址和服务转换
主机地址和端口的表示有下面几种方法:
-
主机地址表示为一个二进制值或一个符号主机名(域名)或展现格式(IPv4为点分十进制,IPv6为16进制字符串)。
-
端口号表示为一个二进制值或一个符号服务名。
二进制格式的地址不易于记忆和使用,人们更倾向于使用点分十进制来表示IPv4地址,也提供了几个二进制形式和点分十进制形式的转换函数:
#include <arpa/inet.h>
int inet_aton(const char *str, struct in_addr *addr);
in_addr_t inet_addr(const char *str);
char *inet_ntoa(struct in_addr inaddr);
上面的函数只提供IPv4地址的转换,这些函数已经被废弃了,需要使用下面的函数,提供IPv4和IPv6地址的转换:
#include <arpa/inet.h>
int inet_pton(int af, const char *src, void *dst);
const char *inet_ntop(int af, const void *src, char *dst, size_t size);
#include <netinet/in.h>
#define INET_ADDRSTRLEN 16 /* Maximum IPv4 dotted-decimal string */
#define INET6_ADDRSTRLEN 46 /* Maximum IPv6 hexadecimal string */
p代表presentation,n代表network:
-
af用来指定IP地址版本:
AF_INET或AF_INET6。 -
void *指针是二进制格式地址参数,需要指向in_addr或in6_addr结构而不是结构体内部的整型(IPv4)或整型数组(IPv6)。 -
char *指向字符串格式地址,其中size为目标缓冲区大小。定义了两个常量,标志了地址的最大长度(包含结尾NULL)。
还有一些功能更强大的函数,提供了主机和服务名与二进制形式之间的转换:
#include <netdb.h>
struct hostent *gethostbyname(const char *hostname);
struct hostent *gethostbyaddr(const void *addr, socklen_t len, int family);
struct servent *getservbyname(const char *servname, const char *proto);
struct servent *getservbyport(int port, const char *proto);
这些函数也已经过时了,需要使用下列函数,来提供协议无关的服务:
#include <sys/socket.h>
#include <netdb.h>
int getaddrinfo(const char *host, const char *serv,
const struct addrinfo *hints, struct addrinfo **res);
void freeaddrinfo(struct addrinfo *res);
int getnameinfo(const struct sockaddr *addr, socklen_t addrlen,
char *host, size_t hostlen,
char *serv, size_t servlen, int flags);
struct addrinfo {
int ai_flags; /* Input flags (AI_*) */
int ai_family; /* Address family */
int ai_socktype; /* Type: SOCK_STREAM, SOCK_DGRAM */
int ai_protocol; /* Socket protocol */
size_t ai_addrlen; /* Size of structure pointed to by ai_addr */
char *ai_canonname; /* Canonical name of host */
struct sockaddr *ai_addr; /* Pointer to socket address structure */
struct addrinfo *ai_next; /* Next structure in linked list */
};
getaddrinfo函数同时提供了主机和服务的转换服务,函数以host、serv和hints参数作为输入:
-
host可以是一个主机名或一个点分十进制的IPv4地址或十六进制字符串的IPv6地址。注意host也可以是NULL,一般只用来创建监听套接字。 -
serv可以是一个服务名或一个十进制端口号字符串。 -
hints参数用来决定res返回的结果,只能设置下面几个元素:-
ai_family可以是AF_INET或AF_INET6,当指定为AF_UNSPEC时,将返回所有种类的地址结构。 -
ai_socktype指定套接字的类型。指定为SOCK_STREAM,将返回适用于TCP流式套接字使用的地址结构;指定为SOCK_DGRAM,将返回适用于UDP数据报套接字使用的地址结构;指定为0,将返回任意类型。 -
ai_protocal指定协议,一般被设置为0。 -
ai_flags是一个位掩码,用于指定getaddrinfo()的行为,可以为0或者多个选项相或,最常用的选项有:-
AI_PASSIVE用于返回一个适合创建监听套接字的地址结构。当指定了这个选项,host应设置为NULL,通过res返回的IP地址部分将会使用通配地址(INADDR_ANY 或 IN6ADDR_ANY_INIT);如果没有设置这个选项,那么返回的地址将适用于创建主动套接字,如果host为NULL,IP地址将会被设置为回环地址(loopback)。 -
AI_NUMERICHOST强制将host解释为一个数值地址字符串,避免进行名字解析耗费时间(通常会使用DNS服务)。 -
AI_NUMERICPORT对端口号进行上面解释。
-
-
-
res是一个二级指针,需要将一个指针引用传递。它指向一个动态分配的结果链表,因为一个主机可能会有多个地址结构。返回的地址结构可以直接用来调用套接字相关函数。getaddrinfo()是可重入的,需要在调用结束后使用freeaddrinfo()释放掉结构链表。
通常利用getaddrinfo来构造协议无关的程序,一般用法大致为:
struct addrinfo hints, *res, *resp;
memset(&hints, 0, sizeof(struct addrinfo));
hints.ai_family = AF_UNSPEC;
hints.ai_socktype = SOCK_STREAM; /* SOCK_DGRAM */
hints.ai_flags = AI_PASSIVE; /* 服务器端设置,客户端去掉这句 */
/* 客户端指定的地址为需要连接的地址,服务器指定的地址为自身的地址 */
/* 省略部分错误处理 */
getaddrinfo(host, serv, &hints, &res);
for (resp = res; resp != NULL; resp = resp->ai_next) {
fd = socket(resp->ai_family, resp->ai_socktype, resp->ai_protocol);
if (fd == -1)
continue;
/* 服务器端 */
/* 省略设置选项,比如SO_REUSEADDR */
if (bind(fd, resp->ai_addr, resp->ai_addrlen) == 0)
break; /* 成功 */
close(fd);
/* 客户端 */
if (connect(fd, resp->ai_addr, resp->ai_addrlen) == 0)
break;
close(fd);
}
if (resp == NULL) {
/* 错误处理 */
}
/* 服务器端 */
listen(fd, BACKLOG);
/* 释放结构 */
freeaddrinfo(res);
getnameinfo()通过给定一个socket地址结构,返回包含对应的主机和服务名的字符串或者在无法解析名字时返回一个等价的数值。当不需要某一项时,可以指定为NULL,并设置长度为0。
TCP
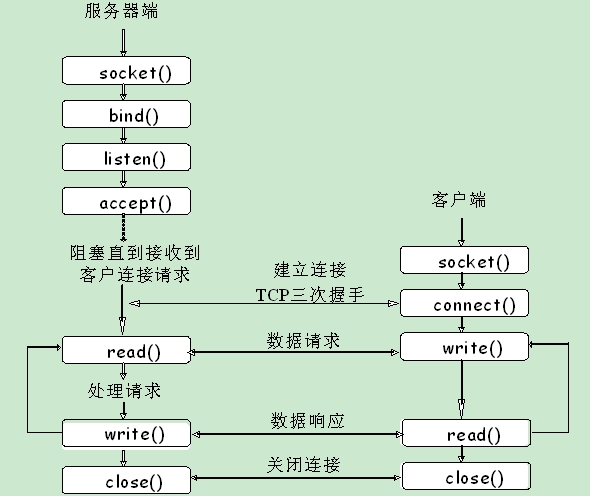
TCP编程的最基本的流程就如上图所示。
socket(2)
服务器端和客户端都需要创建流式套接字,通过socket()系统调用返回一个套接字描述符来完成。
#include <sys/socket.h>
int socket(int domain, int type, int protocol);
/* 创建TCP套接字 */
fd = socket(AF_INET, SOCK_STREAM, 0);
AF代表的是address family(地址族),也有相对应的PF,也就是protocol family(协议族),通常都会有#define AF_INET PF_INET,所以这两个是等价的。TCP是字节流协议,只支持SOCK_STREAM。最后一个参数通常设置为0,会根据给定的前两个参数组合选择适当的系统默认值。在较新版本的Linux中,提供了SOCK_NONBLOCK 和 SOCK_CLOEXEC标记,可以用来创建非阻塞套接字和启用close-on-exec标志。
bind(2)
#include <sys/socket.h>
int bind(int sockfd, const struct sockaddr *addr, sockelen_t addrlen);
bind()调用用来给套接字绑定地址结构,对于TCP来说,是将一个IP地址和端口号赋予给套接字。也可以不绑定地址,这种情况和绑定端口号0及IP地址0等价,会由内核选择IP地址和临时端口。
对于服务器端来说,一般需要绑定一个众所周知的端口,也可以选择绑定一个特定的IP地址,不过一般会绑定通配地址INADDR_ANY也就是0,内核等到套接字已连接(TCP)或已在套接字上发出数据报(UDP)时才选择一个本地IP地址。客户端一般不需要调用bind,不过更好的办法是使用上面的getaddrinfo()创建协议无关的程序:
struct sockaddr_in addr;
memset(&addr, 0, sizeof(addr));
addr.sin_family = AF_INET;
addr.sin_port = htons(port);
addr.sin_addr.s_addr = htonl(INADDR_ANY);
bind(fd, (struct sockaddr) &addr, sizeof(addr));
bind()调用最常见的错误是EADDRINUSE(Address already in use),这是因为绑定了重复的端口号导致的。在之前的网络协议里解释过TIME_WAIT状态和判定连接的五元组,
处于TIME_WAIT状态时或者已经有相同端口号的连接时(例如,服务器接收连接,创建一个子进程处理连接,后来,服务器终止,子进程仍在运行),
不能绑定相同的端口号,设置SO_REUSEADDR选项,可以绑定相同的端口号,只要使用不同的IP地址即可。
在Linux上设置该选项,绑定了通配地址的端口只能有一个实例。服务器通常都会在调用bind前设置该选项:
#include <sys/socket.h>
const int on = 1;
setsockopt(fd, SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on));
connect(2)
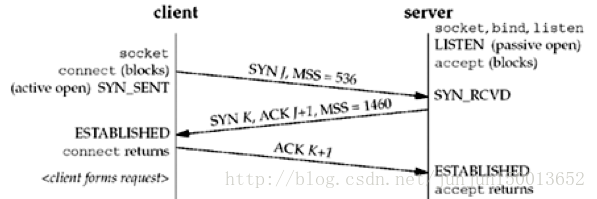
通过socket()调用创建的是主动套接字,这时可以调用connect()来连接到一个被动套接字(监听套接字)。
#include <sys/socket.h>
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
connect()调用成功,套接字变为ESTABLISHED状态,但不代表连接已经被接受,也就是说即使服务器不调用accept(2),connect()也会成功返回,这时客户端仍可以发送数据,数据由TCP排队存储在套接字的接受缓冲区中。
一般情况下,connect会阻塞到建立成功或出错,出错主要有下面几种:
-
ETIMEOUT,客户端没有收到ACK响应,超时重传到一定次数后返回该错误,有可能是网络紊乱导致或者服务器监听队列已满丢弃SYN或者没有网络中没有对应主机导致ARP超时。在Linux上测试,当队列已满还是会完成前两次握手,同时可以向套接字写,具体见下面listen调用。 -
ECONNREFUSED,服务器主机在指定的端口上没有进程在等待连接,服务器主机收到连接请求会响应RST。 -
EHOSTUNREACH和ENETUNREACH,当指定的主机或网络不可达时,就会在路由器上产生ICMP错误,这是发送方超时并重传,直到放弃返回ICMP指定的错误。
listen(2)
listen()将主动套接字转换为被动套接字,也就是监听套接字,可以接收连接,状态从CLOSED状态转换为LISTEN状态。
#include <sys/socket.h>
int listen(int fd, int backlog);
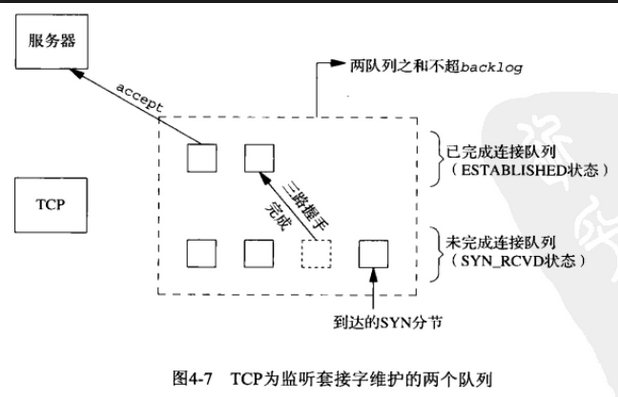
内核为监听套接字维护了两个队列:
-
未完成连接队列,每个SYN段对应其中一项,服务器正在完成相应的TCP三路握手,套接字处于SYN_RCVD状态。
-
已完成连接队列,每个已完成TCP三次握手的套接字对应其中一项,处于ESTABLISHED状态。
backlog用于指定队列的大小,不同的实现有不同的解释方法,一般会是设置的值乘上一个系数,比如1.5。backlog设置为0时,在Linux上仍可以接收1个连接,当backlog过大时,会被截取到限制的最大值,通常会是128。
当连接太频繁时,队列可能会被充满。当两个队列都满时,TCP会忽略后面的SYN,客户端可以重发SYN请求连接。当已完成连接队列已满时而未完成连接未满时,仍有客户连接进来,就会被存放在未完成连接队列,并向客户端发送SYN + ACK段,使客户端的connect()返回成功。当客户向服务器发送三次握手的最后一个ACK时,服务器会丢弃该ACK,因为已完成连接队列没有空间存放新的套接字。由于没有收到ACK,服务器会重传SYN + ACK,持续5次,之后等待已完成连接队列有空间或超时,若超时则将该套接字丢弃。客户端在connect()成功返回后,可以向套接字写不产生错误,这时由于连接没有建立,服务器不会发送ACK,会导致写的数据重传,当连接成功建立就会存储在接受缓冲区,如果超时,就会收到RST并返回错误。但如果没有发送数据,就不会产生RST,即使调用read()也不会产生错误,会一直阻塞下去。
accept(2)
accept()用于从上面的已完成连接队列对头返回下一个已完成连接,如果已完成连接队列为空,会阻塞(默认为阻塞套接字)。
#include <sys/socket.h>
int accept(int fd, struct sockaddr *addr, socklen_t *addrlen);
addr用于返回连接到的对端地址。addrlen是值-结果参数,需要初始化为addr的大小,返回时,值为对端地址结构的大小,可以都设置为NULL。accept()调用成功会返回一个已连接套接字,通过该套接字和对端进行通信。accept()返回的套接字会继承监听套接字的一些选项,主要有TCP_KEEPALIVE、TCP_NODELAY,不继承O_NONBLOCK。
在调用accept()时可能会出现下面几种状况:
-
在调用
accept()前,服务器接收到FIN。当服务器接收该连接时,会成功返回一个套接字并立刻发送FIN和ACK,完成四次挥手,之后对该套接字进行操作会出错,与操作已关闭套接字效果一样,见close(2)。 -
在调用
accept()前,服务器接收到RST,有两种情况:-
在未完成队列里时收到
RST,也就是发送了三次握手的第一个TCP段后,紧跟着发送一个RST。调用accept()返回ENOTSOCK错误。 -
在已完成队列里时收到
RST,也就是完成三次握手,再发送RST,这时调用accept()会成功,但是之后对已连接套接字进行I/O操作,会返回ECONNRESET错误
-
这都是在(Ubuntu 14.04)测试的,有些实现可能会返回ECONNABORTED或忽略这种情况。
getsockname(2)/getpeername(2)
#include <sys/socket.h>
int getsockname(int fd, struct sockaddr *addr, socklen_t *addrlen);
int getpeername(int fd, struct sockaddr *addr, socklen_t *addrlen);
这两个函数用来返回已连接套接的地址。getsockname()返回本端地址,可以用来确定内核分配的地址;getpeername()返回对端地址。
close(2)
close()调用用来关闭套接字,释放连接,并回收描述符资源。
#include <unistd.h>
int close(int fd);
close()默认行为是将套接字标记为已关闭,该套接字描述符不能再由调用进程使用。需要注意的有以下几点:
-
描述符是引用计数的,
close()调用成功将使计数减一,计数为0时,才会向对端发送FIN,关闭连接。先发送FIN的一端执行的是主动关闭,如果四次挥手完成,会进入到TIME_WAIT状态,服务器一般会设置SO_REUSEADDR选项,见bind(2)。 -
如果套接字发送缓冲区中有数据没有发送,会将数据发送到对端,但不等待对端确认就返回,即不能够确定数据是否成功发送到对端。如果套接字引用计数为0,后面跟着正常的TCP终止序列。
-
如果套接字接受缓冲区中有数据没有读,关闭套接字会发送
RST替代正常的FIN序列,这会导致略过TIME_WAIT状态,直接进入CLOSED状态。 -
当对端连接已关闭后,如果继续向对端发送数据,第一次写会调用成功,对端响应
RST,第二次写就会收到SIGPIPE并返回EPIPE错误,SIGPIPE默认是关闭进程,所以经常会设置signal(SIGPIPE, SIG_IGN)。 -
如果对端连接关闭,读套接字会返回0。有些实现会在收到
RST后,返回ECONNRESET错误,例如先向对端已关闭的套接字发送数据,之后再读。在我的电脑上测试不管收不收到RST,都会返回0。 -
设置
SO_LINGER选项会影响close()调用的效果:
#include <sys/socket.h>
struct linger {
int l_onoff; /* Nonzero to linger on close */
int l_linger; /* Time to linger */
};
struct linger linger;
linger.l_onoff = 1;
linger.l_linger = x;
setsockopt(fd, SOL_SOCKET, SO_LINGER, &linger, sizeof(linger));
-
默认情况是关闭的,也就是上述的情况,
close()调用立即返回。 -
当
l_onoff为非零时,则开启该选项。l_linger有两种情况:-
l_linger = 0时,close()立即返回,套接字缓冲区的数据都被丢弃,发送缓冲区的数据不会发送。如果计数引用为0,则向对端发送RST,直接进入CLOSED状态。 -
l_linger != 0时,close()不立即返回,会“逗留”一端时间,用来发送发送缓冲区中的数据,直到发送缓冲区的数据全部被确认或超时。若超时,close()返回EWOULDBLOCK错误,残留的数据被丢弃。之后跟以正常的TCP终止序列。
-
-
设置该选项后,
close()成功返回告诉我们数据已全部成功发送到对端,但不能知道应用进程是否读取数据。不设置则不能保证数据是否被确认。
shutdown(2)
TCP是全双工的通信,可以通过shutdown()系统调用来关闭一个方向的通信:
#include <sys/socket.h>
int shutdown(int fd, int how);
调用该函数可以不管引用计数就发送TCP正常的连接终止序列,也就是说该函数影响的其实是打开的文件描述。根据how参数,可以进行下面三种操作:
-
SHUT_RD关闭当前连接的读部分。不要使用这个参数,它没有实际意义,在很多实现中没有提供期望的行为。在Linux上,即使关闭读部分,仍能读到数据,仍能读到对端在关闭后写入的数据。 -
SHUT_WR关闭当前连接的写部分。当前发送缓冲区的数据会被发送掉,然后发送正常的TCP终止序列。对端程序读取完所有的数据后,会读到0。这是最常用的操作。 -
SHUT_RDWR全双工的关闭操作。
shutdown()调用不会释放套接字描述符和它的资源,仍需要调用close()。
I/O模型
主要有下面几种:
-
阻塞I/O:默认设置,会阻塞在等待数据和数据在内核和用户空间的复制。
-
非阻塞I/O:不等待数据,但会阻塞在数据的复制环节。
-
I/O多路复用:
select()、poll()和Linux特有的epoll。阻塞在这三个系统调用上,返回描述符的可读可写条件。数据输入输出还是需要调用真正的I/O操作。 -
信号驱动I/O:开启套接字的该功能,当数据准备好时会发送
SIGIO信号通知进程,同样需要调用真正的I/O操作。 -
异步I/O:告知内核启动某个操作,让内核完成整个操作后通知进程,包括数据在内核和用户空间的传输,通常也是发送信号进行通知,该类型不会造成进程阻塞。前面几种都是同步I/O,都会造成进程阻塞,因为都会阻塞在数据的复制环节。
内核为每一个TCP套接字都维护了一个发送缓冲区和一个接收缓冲区:
-
写操作是从应用程序缓冲区拷贝数据到发送缓冲区。如果当前发送缓冲区空间不够,就会阻塞直到所有数据复制完毕(默认行为)。数据的传输由内核和TCP/IP协议栈完成,缓冲区中的数据会被分段传输,最大为MSS大小,之后以MTU大小的IP数据报在网络中传输。发送缓冲区中的数据直到收到对端的ACK才会被丢弃。
-
读操作是从接收缓冲区拷贝数据到应用程序缓冲区。如果当前接收缓冲区中没有数据,会阻塞到有数据可读。读操作一般不会返回指定大小的数据,如果数据比较少,会发生部分读。
在TCP三次握手时,会通告对端窗口大小,也就是接受缓冲区的大小,可以通过设置SO_RCVBUF和SO_SNDBUF选项改变默认缓冲区大小。
#include <sys/socket.h>
int buf_size = x;
setsockopt(fd, SOL_SOCKET, SO_SNDBUF, &buf_size, sizeof(buf_size));
要注意设置的顺序问题,因为窗口大小是在建立连接时通告,所以服务器端需要在listen()之前设置;客户端要在connect()之前设置。
影响输出的因素还有Nagle算法,详见上面协议部分。设置TCP_NODELAY选项可以关闭该算法:
#include <sys/socket.h>
#include <netinet/tcp.h> /* for TCP_* */
int on = 1;
setsockopt(fd, IPPROTO_TCP, TCP_NODELAY, &on, sizeof(on));
阻塞输入输出
read(2)/write(2)
最基本的描述符输入输出系统调用。
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, void *buf, size_t count);
readv(2)/writev(2)
有时需要将多个缓冲区的数据同时发送到网络上(原子操作),比如消除Nagle算法的影响。
#include <sys/uio.h>
ssize_t readv(int fd, const struct iovec *iov, int iovcnt);
ssize_t writev(int fd, const struct iovec *iov, int iovcnt);
struct iovec {
void *iov_base; /* staring address */
size_t iov_len; /* size of buffer */
};
参数iov指向iovec结构体数组,每个数组元素包含一个缓冲区和缓冲区大小。
iovcnt用来指明iov中数组元素个数。
sendfile(2)
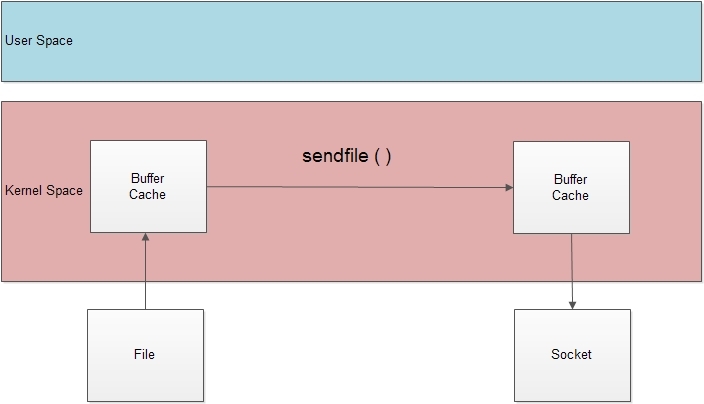
很多程序需要传递整个文件内容,比如Web服务器和文件服务器。
#include <sys/sendfile.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
常见的传递文件操作为调用循环,类似:
while ((n = read(fd, buf, BUF_SIZE)) > 0)
write(sockfd, buf, n);
但这会带来很大的开销,数据在用户态和内核态来回传输,调用系统调用的开销也比较大。sendfile()采用了零拷贝传输,在内核空间内就完成文件内容到套接字的传输。offset为文件起始处偏移量,一般设置为NULL。
sendfile()长和TCP_CORK选项(头文件为linux/tcp.h)一起使用,尤其在Web服务器当中,需要发送HTTP首部和页面数据。设置该选项候,所有的输出会缓冲在一个TCP段中,直到:
- 到达MSS大小
- 取消该选项
- 套接字关闭
- 写入第一个字节后200ms
recv(2)/send(2)
#include <sys/socket.h>
ssize_t recv(int fd, void *buf, size_t len, int flags);
ssize_t send(int fd, void *buf, size_t len, int flags);
这两个系统调用提供了专属于套接字的功能,前三个参数和read()/write()相同,flags最常见的有下面几个(详见 man 2 recv):
-
MSG_DONTWAIT使该次调用非阻塞,如果不能立即完成返回EAGAIN错误。 -
MSG_WAITALL阻塞到读取完指定大小的数据,但是仍很大可能返回不足值,比如出错、中断等等,用途不大。 -
MSG_NOSIGNAL防止写出错产生SIGPIPE信号终止进程。 -
MSG_OOB发送带外数据。 -
MSG_MORE效果同TCP_CROK,只适用于该次调用。 -
MSG_PEEK预览数据,之后可以再次读取。
recvfrom(2)/sendto(2)
#include <sys/socket.h>
ssize_t recvfrom(int fd, void *buf, size_t len, int flags,
struct sockaddr *addr, socklen_t *addrlen);
ssize_t sendto(int fd, const void *buf, size_t len, int flags,
struct sockaddr *addr, socklen_t *addrlen);
recvfrom()最后两个参数用于返回对端的地址,sendto()最后两个参数用于指定目的地址。这两个函数主要用于UDP,因为UDP是无连接的,一般也不用connect(),所以需要指定地址。
recvmsg(2)/sendmsg(2)
这是最通用的I/O函数,基本上所有的调用都可以使用这两个函数。使用方法比较复杂,最大的用途是用来发送辅助数据。
输入输出的注意事项
-
部分读:接受缓冲区中的数据比请求的少时,会返回可读的数据。当读取被信号中断时,不会读取数据,直接返回错误。
-
部分写:发送缓冲区空间不足以传输所有的字节,在传输了部分字节到缓冲区后,调用出错,例如被信号中断、非阻塞写、异步错误。只要成功发送数据到缓冲区就会返回成功的字节数。
- 对端出错。当仅收到
RST时,读写都返回ECONNREST错误;当收到FIN时,读永远返回0(FIN比RST优先级大),写第一次产生RST,第二次产生SIGPIPE信号,返回EPIPE错误;超时,返回ETIMEOUT。举例:- 进程终止导致连接终止,会发送
FIN给对端。 - 主机或网络崩溃,超时或主机或网络不可达。
- 主机崩溃后重启,即没有对应的连接,返回
RST。 - 主机关机,和终止一样。
- 进程终止导致连接终止,会发送
- TCP是字节流协议,没有消息边界的概念。你不知道对端会发送多少数据给你,也不能依赖于有消息边界的通信,除非每一条消息都有固定的长度。一般需要自己设定协议,常见的有:
-
用分隔符标志记录结束。例如HTTP协议,用
\r\n分隔。不过要注意的是如果在数据中需要包含分隔符,需要使用转义字符或者特殊编码。 -
在每一条消息前面附加一个消息头,用来指定后方数据的长度,消息头长度固定,所以读取数据可以先读取固定长度的消息头,然后根据消息头中的数据读取指定的数据量。
-
最好不要传递二进制结构,尤其是结构体,因为有填充的空间。使用字符串编码。
-
使用输入输出系统调用,最好不要使用标准I/O函数。因为标准I/O为了减少系统调用提高效率,在函数内部维护了一个不可见的缓冲区,对于套接字是完全缓冲,如果一定要用也要设置为无缓冲,不过也失去了效率优势。混用也会出现发麻,所以不要使用标准I/O。
-
如果需要确定数据被对端应用程序收到,需要发送一个用户级别的确认。
keepalive
当连接没有数据交互时,没有办法发现对端出错或连接是否终止,直到调用输入输出函数才会将错误返回。设置SO_KEEPALIVE选项可以开启TCP提供的检测机制,一段时间内没有数据交互,就会发送一个TCP探测段,错误处理与发送数据相同。默认的超时时间大约是2小时,比较长,可以设置TCP_KEEPIDLE来更改定时时间。
#include <sys/socket.h>
#include <netinet/tcp.h>
int on = 1;
int time = x;
setsockopt(fd, SOL_SOCKET, SO_KEEPALIVE, &on, sizeof(on));
setsockopt(fd, IPPROTO_TCP, TCP_KEEPIDLE, &time, sizeof(time));
设置的超时时间单位为秒,在Linux上,该时间不是内核级别,是基于每个套接字设置。当使用该选项检测到错误也需要数据交互才能发现,最常用的是使用I/O多路复用返回可读或可写条件来返回错误。也可以自己实现应用级别的心搏机制(heartbeat)。
非阻塞套接字
因为网络服务器一般需要服务多个客户,不可以在一个套接字上阻塞太长时间。可以设置定时机制,使用alarm(2)或者select(2)或设置SO_RCVTIMEO和SO_SNDTIMEO选项或其他定时机制来实现超时机制,不过最常见的还是设置非阻塞套接字。
有下面几种方法设置非阻塞套接字(Linux上):
-
socket(2)调用可以设置SOCK_NONBLOCK选项创建非阻塞套接字。 -
accept4(2)设置SOCK_NONBLOCK选项返回非阻塞套接字,使用该函数需要设置特性测试宏#define _GNU_SOURCE。 -
使用
fcntl,最通用的方法:
#include <unistd.h>
#include <fcntl.h>
int flags;
flags = fcntl(fd, F_GETFL);
fcntl(fd, F_SETFL, flags | O_NONBLOCK);
当使用非阻塞I/O时,如果没有数据可以读入或输出,就返回EAGAIN错误,EWOULDBLOCK和EAGAIN相同。如果可以读入一部分或输出一部分,就返回成功的字节数。
使用非阻塞I/O对缓冲区的操作会比较复杂,如果需要指定数据量,可以编写类似readn()或writen()的函数,用循环来多次调用I/O。
非阻塞accept()
非阻塞的accept()在没有可用连接时返回EAGAIN,使用该版本可以预防阻塞和已连接套接字错误,比如被其他线程先接收连接,这时再调用会阻塞。当accept之前的连接被终止时导致没有可用连接,有的实现会忽略错误导致阻塞在accept,而Linux会将错误码返回。
非阻塞connect()
默认的行为是等到接收到对端的SYN + ACK再返回。如果连接不能立即建立,会阻塞一段时间,直到出错或成功建立连接。使用非阻塞的版本会在不能立即建立连接的情况下,立即返回EINPROGRESS错误,当连接的目标在同一主机上时,会成功返回。最常见的用法是为了同时建立多个连接,例如Web浏览器。
确定连接是否成功建立需要使用select()或poll()或epoll(),监控套接字返回可写条件,不过因为连接出错会同时返回可读和可写,所以在可写时,要检查SO_ERROR:getsockopt(fd, SOL_SOCKET, SO_ERROR, &error, &len),当建立成功时,error为0;建立失败,error为相应的错误,需要关闭套接字,重新创建再连接,不能再次调用connect()会返回EADDRINUSE。当阻塞的connect()被中断时,也需要使用上面的方法。
信号驱动I/O
使用信号驱动I/O需要设置O_ASYNC标志和该套接字的属主,同时还需要建立SIGIO的信号处理器函数。当有输入输出时,就会发送SIGIO信号给进程,信号的频繁出现会使程序变得非常复杂,所以现在用的很少。
I/O多路复用
多路复用是为了实现同时检查多个文件描述符,看它们是否准备好了执行I/O操作。使用非阻塞I/O的轮询也可以实现,但是太耗费CPU。使用多线程或多进程也可以实现,但耗费过多资源,数据通信也会造成麻烦。最好的方法是使用select()或poll()或Linux特有的epoll(),其中epoll()效率最高最常用。
多路复用有两种触发机制,这两种机制很像电平,水平触发类似高低电平,边缘触发类似上升沿或下降沿。只是触发(通知)的方式不同,两者返回的结果是相同的,只要监控的事件可用就会返回:
-
水平触发(LT): 当文件描述符上可以非阻塞地执行I/O系统调用,就通知就绪。也就是在接收缓冲区中有数据就通知可读条件;在输出缓冲区中有空间就通知可写条件。
-
边缘触发(ET):当文件描述符自上次状态检查以来有了新的I/O活动,就通知就绪。当有新的数据到达时,就通知可读条件;当输出缓冲区有数据被发送,也就是空闲空间增大时,就通知可写条件。
边缘触发有可能会出现描述符饥饿现象。当一个描述符上出现大量的输入存在时(一般是个不间断的输入流),就会使进程停留在该描述符的读时间过长,导致其他的描述符处于饥饿状态。水平触发没有这种风险,因为水平触发只需要执行一部分I/O操作。
多路复用常与非阻塞I/O一起使用,原因有下面几个:
-
当需要将缓冲区的所有数据读完时,如果循环使用阻塞I/O,因为不知道数据量,最后会进入阻塞。
-
当使用边缘触发时,必须使用非阻塞I/O,需要尽可能多的执行I/O,直到返回
EAGAIN。因为如果后续该套接字没有I/O事件,就会造成数据的丢失或程序阻塞。 -
如果多个进程或线程在同一个打开的文件描述符上进行I/O操作,文件描述符的状态可能会在通知就绪和执行I/O之间发生改变,造成之后的阻塞。
-
当通知可写时,需要写大块的数据,但发送缓冲区没有那么多空间,就会造成阻塞。
-
有时
select()和poll()会返回虚假的通知,例如当收到的TCP段的checksum出错时,会通知就绪状态,但是数据会被丢弃,导致阻塞。
select(2)
#include <sys/time.h> /* For portability */
#include <sys/select.h>
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
void FD_ZERO(fd_set *fdset);
void FD_SET(int fd, fd_set *fdset);
void FD_CLR(int fd, fd_set *fdset);
void FD_ISSET(int fd, fd_set *fdset);
struct timeval {
time_t tv_sec;
suseconds_t tv_usec;
};
select()出现的时间比较早,有许多问题,效率也不是很高。fd_set为文件描述符集合,通常被实现为位掩码,容量由常量FD_SETSIZE决定,在Linux上是1024,select()只能处理大小小于等于1024的描述符。
提供了4个宏操作fd_set,隐藏了内部的实现细节:
-
FD_ZERO()初始化集合为空。 -
FD_SET()将文件描述符添加到指定集合。 -
FD_CLR()将文件描述符从指定集合移除。 -
FD_ISSET()检查文件描述符是不是指定结合的成员。
select()检查三个文件描述符集合:
readfds用来检测输入就绪。writefds用来检测输出就绪。exceptfds用来检测异常情况。异常情况通常只有在流式套接字上接受到带外数据。
首先需要使用FD_ZERO()和FD_SET()初始化集合。当调用返回时,这三个集合被设置为已就绪的文件描述符集合,需要使用FD_ISSET()检查每一个感兴趣的文件描述符。当需要再次调用select()时,需要重新初始化集合。不感兴趣的集合可以设置为NULL。
nfds至少需要设置为比3个文件描述符集合中所包含的最大的文件描述符大1。内核不会去检查大于这个值的文件描述符。
timeout控制select()的阻塞行为:
-
NULL阻塞。 -
结构体内部值不都为0,计时指定时间。
-
结构体内部值为0,立即返回。
当select()返回时,不管是成功返回还是被信号中断,如果时间没有超时,timeout会被更新为剩余的超时时间。select()返回-1,为出错;返回0,为超时;返回正整数为3个集合中已就绪的文件描述符总数。
poll(2)
#include <poll.h>
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
struct pollfd {
int fd;
short events; /* requested events */
short revents; /* returned events */
};
fds为需要检查的文件描述符集合。结构体中fd为需要检查的文件描述符,设置为负值将忽略该元素。events设定为需要检查的事件,设置为0,将关闭对该文件描述符的检查。revents为返回时发生的事件。主要有下面几个位掩码:
POLLIN有数据可读。POLLPRITCP接收到带外数据。POLLOUT可写。POLLRDHUP对端关闭写部分。POLLNVAL监视的描述符被关闭。(不需要设置)
timeout是以毫秒为单位的时间。设置为-1时,将阻塞;为0,检查一次立即返回;大于0,阻塞指定时间。
返回值和select()类似,-1为出错或中断;0为超时;大于0为fds中revents不为0的数目。
poll()和select()主要有下面几点不同:
-
当监视的文件描述符被关闭时,
select()返回-1和EBADF,poll()返回POLLNVAL。 -
select()对文件描述符有限制,上限大小为1024,poll()没有。 -
select()需要每次重新初始化fd_set,poll()不需要。 -
select()需要检查从0到nfds-1之间的所有文件描述符,即使有些你没有设置。poll()只检查你指定的文件描述符。在集合比较稀疏但大小相差比较大的情况下,select()会比poll()慢许多。
poll()和select()比较相似的也有相同的问题:
-
只支持水平触发。
-
内核需要轮询检查所有被指定的文件描述符,效率会随着文件描述符数量的上升而线性下降。
-
每次调用,都需要传递文件描述符集合到内核,内核检查完毕再修改该集合返回给程序。从用户空间到内核空间来回拷贝数据将占用大量CPU时间。
-
需要检查返回的集合中的每个元素。
select()需要为每个描述符使用FD_ISSET(),poll()需要检查每一个元素的revents。
这些问题主要是由于内核不会在每次调用中记录下需要检查的文件描述符集合,因为通常情况下需要检查的文件描述符集合都是相同的。
epoll(2)
epoll()作为Linux特有的API,与前两个相比有很大提高。
#include <sys/epoll.h>
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *ev);
int epoll_wait(int epfd, struct epoll_event *evlist, int maxevents, int timeout);
struct epoll_event {
uint32_t events;
epoll_data_t data;
};
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;
epoll在内核中维护了一个数据结构,该数据结构有两个目的:
-
记录了在进程中声明过的感兴趣的文件描述符列表————interest list(兴趣列表)。
-
维护了处于I/O就绪态的文件描述符列表————ready list(就序列表)。
首先需要调用epoll_create()创建一个epoll实例,返回一个文件描述符,是该内核数据结构的句柄。size参数用来告诉内核如何为内部数据结构分配初始大小,现在已经不用了,只需要设为一个正数。
epoll_ctl()修改epfd所代表的epoll实例的兴趣列表。fd为要修改的兴趣列表中的文件描述符,不可以是普通文件描述符(EPERM),甚至可以是另一个epoll实例描述符,可以监视修改该实例的兴趣列表。op有下面几种操作:
-
EPOLL_CTL_ADD将描述符fd添加到epoll实例的兴趣列表中。添加一个已存在的文件描述符会出现EEXIST错误。 -
EPOLL_CTL_MOD修改描述符fd设定的事件。如果该描述符不在兴趣列表中,会返回ENOENT错误。 -
EPOLL_CTL_DEL将文件描述符fd从兴趣列表删除。如果该描述符不在兴趣列表中,返回ENOENT。当文件描述符被关闭时引用计数为0,会自动从兴趣列表中删除,不会出错。
ev参数用来指定需要监视的事件,并提供了一个可以传回给调用进程的信息。events是一个位掩码,可以指定这几种事件:
EPOLLIN有数据可读。EPOLLOUT可写。EPOLLPRI有带外数据到达。EPOLLRDHUP对端套接字关闭或关闭写端。EPOLLET采用边缘触发,默认为水平触发。EPOLLONESHOT在完成一次事件通知后禁用检查。重新激活需要使用EPOLL_CTL_MOD不能使用EPOLL_CTL_ADD,因为该文件描述符还在epoll实例中。
唯一可获知发生事件的文件描述符的途径就是通过data字段。可以通过将data.fd设置为该文件描述符,最好在之前初始化一下:data.u64 = 0,因为fd只占32字节。或者将data.ptr指向包含文件描述符的结构体。
epoll_wait()用来等待事件发生。参数evlist返回已就绪的文件描述符的信息,空间需要自己分配。maxevents用来指定evlist的元素个数。timeout和poll()一样。调用成功后,返回数组evlist的元素个数;超时返回0;出错为-1。
当创建一个epoll实例时,内核在内存中创建了一个新的i-node并打开文件描述,内核中维护的数据结构(兴趣列表等)是与打开的文件描述相关的:
-
当使用
epoll_ctl()添加了一个元素到兴趣列表中,这个元素同时记录了该文件描述符和监控的事件结构还有该描述符对应的打开的文件描述。当所有指向该打开的文件描述的文件描述符都被关闭后,这个打开的文件描述才会从epoll的兴趣列表中删除,如果有dup的还存在,epoll_wait将仍会返回之前的fd。可以添加复制的文件描述符到同一epfd。 -
如果
epfd指向同一个打开的文件描述(例如通过fork()、dup()),则兴趣列表也相同。通过其中一个epfd修改兴趣列表会影响所有的实例。 -
当有一个线程阻塞在
epoll_wait()时,另一个线程添加兴趣列表会立即生效,并且是线程安全的,不过好多程序不这么做,而是使用管道,比如主线程接收连接,然后向与工作线程相连的管道写,通知工作线程添加该连接到兴趣列表。 -
与
select()和poll()不同,epoll不是无差别轮询,当有I/O操作使文件描述符就绪时,会出现中断,然后调用callback函数。该回调函数会在就绪列表中添加元素。epoll_wait()就是简单的从就绪列表中取出元素。 -
需要监视的文件描述符是在内核中维护的,不再需要来回在用户空间和内核空间传递数据(
epoll_wait时)。
套接字就绪条件
读:
-
套接字接收缓冲区中的数据字节数大于等于低水位标记。设置
SO_RCVLOWAT可以修改低水位标记,默认为1。 -
对端关闭写部分(接收到FIN),
shutdown(fd, SHUT_WR)或关闭套接字。 -
监听套接字有连接可以接受。
写:
-
套接字发送缓冲区的可用空间字节数大于等于低水位标记。设置
SO_SNDLOWAT可以修改低水位标记。 -
对端套接字关闭。写将产生
RST和SIGPIPE。 -
非阻塞
connect()成功建立连接或失败。
当套接字出错时,既可读又可写,会返回-1和错误值。
惊群现象
经常会出现多进程或多线程的服务器。如果有多个accept()阻塞在接受同一个监听套接字的连接(等待相同的fd进行读写一般没什么意义,所以最常见的在监听套接字,不过为什么我测试读写没发现惊群,难道是我姿势不对),会唤醒所有的线程或进程,导致性能下降,这就是惊群。Linux2.6内核已经修复了这种现象,通过加锁只会唤醒一个调用线程或进程。
更常见的是使用I/O多路复用技术。当有多个epfd等待相同的文件描述符就绪时也会发生惊群(可以是不同的epfd,也可以是fork的相同的epfd),将惊群从accept提前到了epoll,这时只有一个可以成功连接,其余accept均返回错误。在Linux4.5内核,提供了EPOLLEXCLUSIVE,可以在EPOLL_CTL_ADD时与需要监听的事件相或来解决惊群现象,只会唤醒设置了这个选项的并且阻塞在epoll_wait的线程(?)。
有一种更好的办法用于epoll_wait,使用SO_REUSEPORT监听相同地址和端口的套接字,内核会将连接分配给不同的套接字实现简单的负载均衡,也不会出现惊群。
UDP
UDP是无连接的协议也没有流量控制。一个UDP套接字可以和多个UDP套接字通信,只要对端的目的地址指向该套接字。UDP没有真正的发送缓冲区,只有一个UDP数据报的大小上限,当大小合适时会立刻发送出去,不需要保存副本。
UDP获知错误会比较麻烦,因为是无连接的,通常不会返回给本地套接字。虽然是无连接的协议,但是可以使用connect()将UDP套接字连接起来,不会有数据上的交互,只是绑定了目的地址和端口号到本地套接字上。有下面几种作用:
-
不需要也不能给输出操作指定目的地址。所有的输出都会发送到已连接的地址。
-
只能接收到已连接的套接字发送的数据,不会收到其他套接字发送的数据。
-
当出现异步错误时会立即返回。
-
提高一定的效率。
UDP的连接是不对称的,只是对使用connect()的这一端起作用。当再次调用connect()时,可以修改连接到的地址,当地址族为AF_UNSPEC时,可以解除连接。
UNIX域套接字
UNIX域套接字的地址是使用路径名来表示的,不会由内核分配地址,必须调用bind(),无法将一个套接字绑定在已存在的路径名上,可以在绑定之前调用unlink()。绑定成功会在文件系统中创建一个条目,当关闭套接字时也不会删除文件。可以使用Linux抽象socket名空间,只需要指定sun_path的第一个字节为NULL,不会出现冲突,关闭套接字会自动删除。
使用socketpair()可以创建一对已连接的UNIX域套接字,相当于创建了一个双向管道,最常用的用法是父子进程各使用一个进行IPC通信。pipe()管道就是基于socketpair()实现。
最特殊的功能是使用sendmsg()和recvmsg()实现描述符传递,实际上传递的是对同一个打开的文件描述的引用,会导致描述符的引用计数加一。
UNIX域的数据报是在内核中传输,也是可靠的。
网络方面暂时告一段落,感觉写的不是很好,太细节了。
留下评论